Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットのEmbarkedの欠損値を修正してみました。
今回からはAge(年齢)の欠損値を修正していきます。
と言うことでデータの読み込みをして、これまでに行ってきた修正をしましょう。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
test.loc[test["Fare"].isnull() == True, "Fare"] = 7.8875
train.loc[train["Embarked"].isnull() == True, "Embarked"] = "S"
train.loc[train["Embarked"] == "S", "Embarked"] = 0
train.loc[train["Embarked"] == "C", "Embarked"] = 1
train.loc[train["Embarked"] == "Q", "Embarked"] = 2
test.loc[test["Embarked"] == "S", "Embarked"] = 0
test.loc[test["Embarked"] == "C", "Embarked"] = 1
test.loc[test["Embarked"] == "Q", "Embarked"] = 2
all_data = pd.concat([train.drop(columns = "Survived"), test])
all_data
実行結果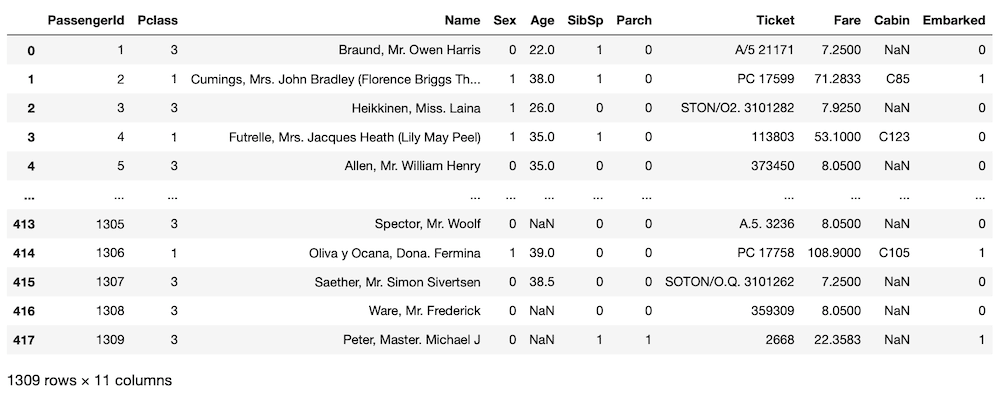
欠損値の数を確認してみましょう。
<セル2>
all_data.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 263
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 1014
Embarked 0
dtype: int64FareとEmbarkedの欠損値は確かになくなっています。
今回対象としているAge(年齢)ではtrain.csvとtest.csv合わせて263個の欠損値があるようです。
どちらに何個あるのか確認してみます。
<セル3>
print(train["Age"].isnull().sum())
print(test["Age"].isnull().sum())
実行結果
177
86訓練用データセット(train.csv)に177個、テスト用データセット(test.csv)に86個の欠損値があるようです。
最終的にはこの欠損値のデータそれぞれを一つずつ見て、妥当な年齢を入力していくのがいいのでしょうが、まずはざっくり試して、少しずつ修正を重ねて、真の値に近づけていきましょう。
ということで今回はざっくりと平均値を欠損値に当てはめてみようと思います。
平均値を欠損値と置き換える
まずは年齢の平均値を取得していきます。
<セル4>
print(all_data["Age"].mean())
実行結果
29.881137667304014平均値はほぼ30歳という結果になりました。
ということで今回は年齢の欠損値を「30」と置き換えてみます。
<セル5>
train.loc[train["Age"].isnull() == True, "Age"] = 30
test.loc[test["Age"].isnull() == True, "Age"] = 30
実行結果ここでは値を置き換えただけなので実行しても何も起こっているように見えません。
trainとtestの欠損値が無くなっているか確認します。
<セル6>
train.isnull().sum()
実行結果
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 0
dtype: int64<セル7>
test.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
dtype: int64どちらの欠損値も無くなっていることが確認できました。
機械学習・予想、スコアの取得
ではこのデータで機械学習して、生存予想、データの提出をしてみましょう。
<セル8>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked", "Age"]]
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=10000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.8156424581005587ここのスコアは最初が「0.7932960893854749」、Fareの欠損値を修正したものでは「0.8044692737430168」、Embarkedの欠損値を修正したものは「0.8324022346368715」でした。
でもKaggleに提出して得られたスコアでは、Fareの欠損値を修正したものが一番良かったです。
ということで今回のモデルは良さそうですが、過剰に期待せず、淡々と提出してみましょう。
それではデータを出力していきますが、今回は出力するファイル名を「submit_data_Age.csv」としてみました。
<セル9>
x_testset = test.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked", "Age"]]
pred = model.predict(x_testset)
submit_data = pd.DataFrame()
submit_data["PassengerId"] = test["PassengerId"]
submit_data["Survived"] = pred
submit_data = submit_data.set_index("PassengerId")
submit_data.to_csv("./submit_data_Age.csv")
実行結果これでデータが出力されましたので、Kaggleに提出して、スコアをゲットしてみます。
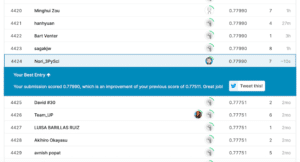
そして今回のスコアがこちら。
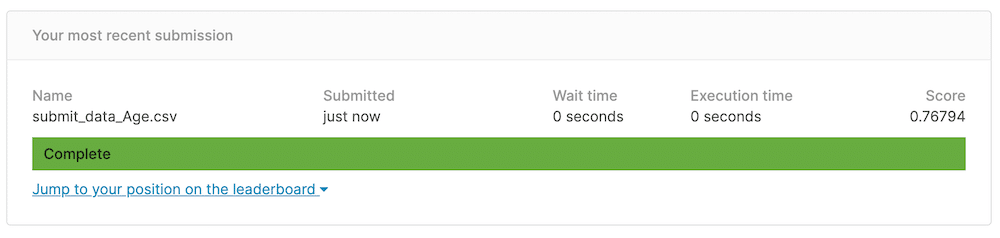
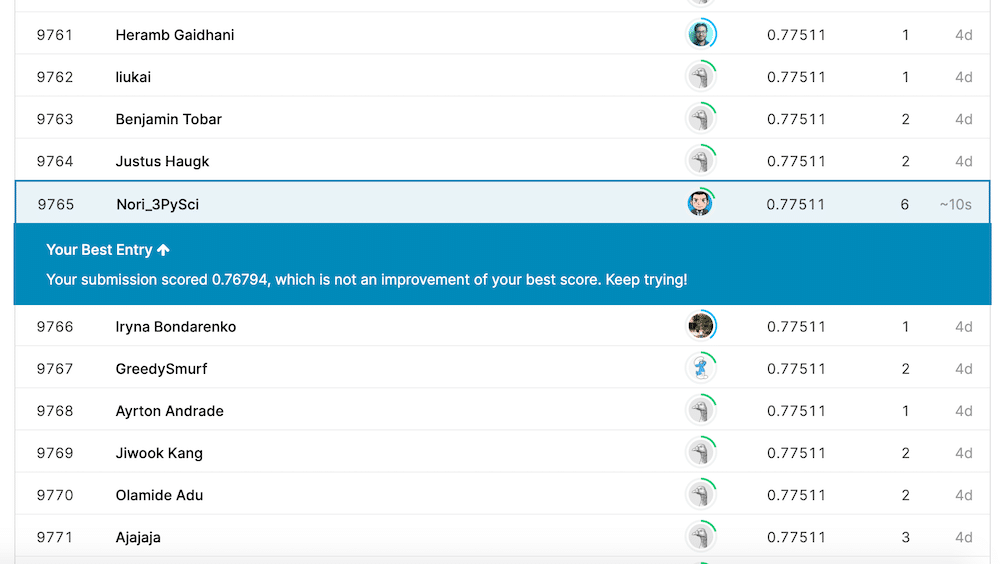
むしろこれまでで一番悪いスコアになってしまったんではないでしょうか。
理由として考えられるのは、Age(年齢)の欠損値を一律で「30」にしてしまったこと、もちろんこれは現実的にはありえません。
つまり間違ったデータを元に機械学習しているため、得られる予想も間違ったものになってしまったと考えられます。
このことから元になるデータの正確性が重要であると言えそうです。
ではどうやって値が欠損しているデータを正確なデータに仕上げるのか、次回も続けてそこを色々と検討していきたいと思います。
ではでは今回はこんな感じで。
コメント