Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットのAgeの欠損値を一律に「30」修正してみました。
Age(年齢)は1309人のうち、263人のデータが欠損していましたが、欠損している全ての人が30歳であることは現実的にはかなり確率が低いため、間違ったデータセットとなってしまい、間違った予想をしてしまったと考えられます。
今回はもう少し値をばらけさせるということで、ランダムな値にしてみようと思います。
ということで前回同様、データの読み込みとこれまでの修正を行っていきます。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
test.loc[test["Fare"].isnull() == True, "Fare"] = 7.8875
train.loc[train["Embarked"].isnull() == True, "Embarked"] = "S"
train.loc[train["Embarked"] == "S", "Embarked"] = 0
train.loc[train["Embarked"] == "C", "Embarked"] = 1
train.loc[train["Embarked"] == "Q", "Embarked"] = 2
test.loc[test["Embarked"] == "S", "Embarked"] = 0
test.loc[test["Embarked"] == "C", "Embarked"] = 1
test.loc[test["Embarked"] == "Q", "Embarked"] = 2
all_data = pd.concat([train.drop(columns = "Survived"), test])
all_data
実行結果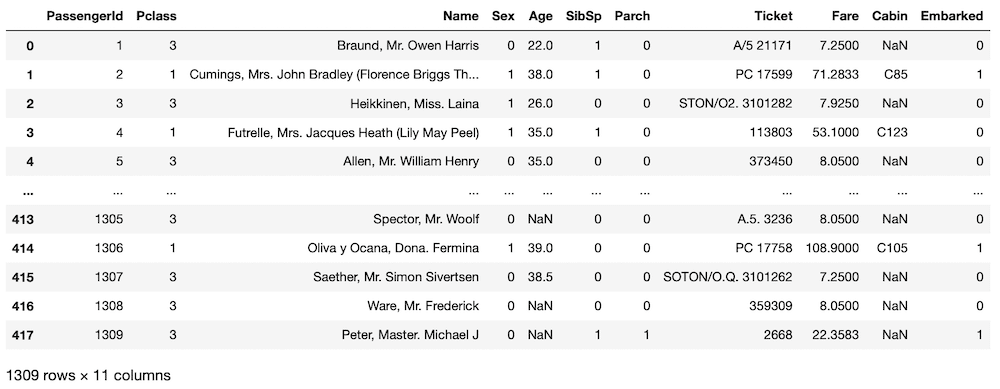
それでは始めていきましょう。
ランダム値の範囲を決める
今回はAge(年齢)の欠損値をランダムな値としてみましょう。
しかしランダムといっても200歳といった現実的にあり得ない年齢にはできません。
今回はランダム値の最大値、最小値をタイタニック号に乗船している人の年齢の最大値、最小値としましょう。
ということでまずはタイタニック号に乗船している人の年齢の最大値、最小値を取得します。
最大値、最小値などの統計値を取得する簡単な方法は「.describe()」を使うことです。
こちらの記事で紹介していますので、良かったらどうぞ。
今回は「Age」の統計値が欲しいので、「all_data[“Age”].describe()」となります。
<セル2>
all_data["Age"].describe()
実行結果
count 1046.000000
mean 29.881138
std 14.413493
min 0.170000
25% 21.000000
50% 28.000000
75% 39.000000
max 80.000000
Name: Age, dtype: float64色々値が出てきましたが、最大値は「max」、最小値は「min」の行の値です。
最高齢が80歳、最年少が0.17歳ということが分かりました。
欠損値にランダムな値を代入する
次にデータセットの欠損値に0.17から80までのランダムな値を代入していきます。
<セル3>
import random
import numpy as np
for i in range(len(train)):
if np.isnan(train.iloc[i, 5]) == True:
train.iloc[i, 5] = random.uniform(0.17, 80)
for i in range(len(test)):
if np.isnan(test.iloc[i, 4]) == True:
test.iloc[i, 4] = random.uniform(0.17, 80)
実行結果ここでは値を代入するだけなので、実行しても何も表示されません。
少しややこしいので順に説明していきましょう。
まず最初の行の「for i in range(len(train)):」で訓練用データセットの行数を変数iに格納していきます。
次に「if np.isnan(train.iloc[i, 5]) == True:」で欠損値の判定を行っています。
その中で「train.iloc[i, 5]」という部分はi行目の”Age”の値を示しています。

train.iloc[i, “Age”]のように行”数”と列”名”を同時に使うことはできないため、ここでは行”数”と列”数”に合わせています。
またここでは「.isnull()」ではなくて、「.isnan()」を使っています。
まず「.isnull()」はPandasの関数ですが、Pandasのデータフレーム中の一つの値を取り出した時、その値はPandasのデータフレーム型ではなく、str型だったり、int型、numpy型といった型になります。
今回、「Age」の値は「numpy型」だったため、Pandasの欠損値判定の関数である「.isnull()」ではなく、numpyの欠損値判定の関数「.isnan()」を用いたということです。
そのためこのセルの最初で「import numpy as np」としてnumpyをインポートしています。
次に「train.iloc[i, 5] = random.uniform(0.17, 80)」として、指定した場所(i行目のAgeの列)に、「random.uniform(0.17, 80)」としてランダムな値を代入しています。
またテスト用データセット(test)では、Ageを指定するための列数が違うことに注意してください。

先ほどのtrainでは6列目(つまり5)がAgeでしたが、testでは5列目(つまり4)がAgeの列になっています。
これで欠損値が無くなったか確認してみましょう。
<セル4>
train.isnull().sum()
実行結果
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 0
dtype: int64<セル5>
test.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
dtype: int64もう一つ年齢構成が歪な形(ある年齢だけ突出している等)になっていないか、ヒストグラムを描いて確認してみます。
<セル6>
train["Age"].hist()
実行結果
<セル7>
test.isnull().sum()
実行結果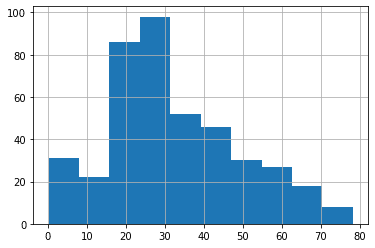
特に歪な形になっていないようなので、これで機械学習・予測をしていきましょう。
機械学習・予測
ここのプログラムは前回と変わりありません。
<セル8>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked", "Age"]]
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=10000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.7486033519553073これまでのこの時点でのスコアはこんな感じでした。
| 修正項目 | 機械学習スコア |
| 初期(修正なし) | 0.79330 |
| Fare | 0.80447 |
| Embarked | 0.83240 |
| Age(平均値) | 0.81564 |
今回は「0.74860」なのでこれまでの中で一番低いスコアになっています。
ただこのスコアとKaggleのスコアはそれほど関連していなかったりするので、とりあえずKaggleで採点してもらいましょう。
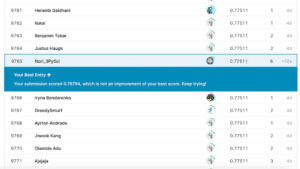
ということでKaggleで得られたスコアがこちら。

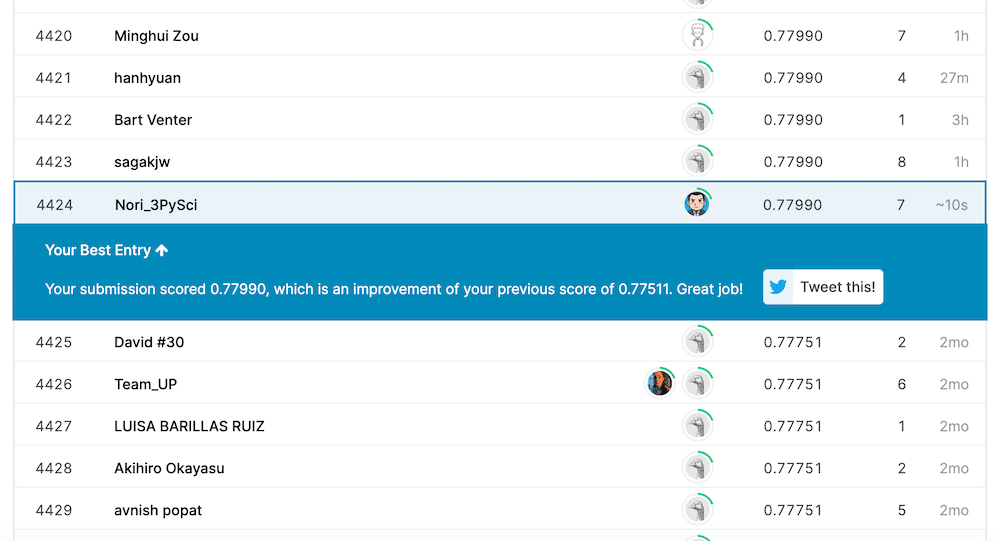
これまでの最高スコアが「0.77511」だったのに対し、今回は「0.77990」とほんの少しアップしました。
なかなかこうやって上がっていくとうれしいものですね。
しかしランダムな値もまだまだ信用できるデータではありません。
次回はランダム値を使いつつもAge(年齢)の統計値に沿ったランダム値、つまり年齢に重みを設定してランダム値を設定して、機械学習に使ってみましょう。
ではでは今回はこんな感じで。
コメント