Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットのFareの欠損値を修正したデータで機械学習・生存予測し、データをKaggleに提出してみました。
今回はEmbarked(乗船地)の欠損値を修正していきます。
と言うことでデータの読み込みから行いますが、前回までの修正点を入れ込んでいきます。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
test.loc[test["Fare"].isnull() == True, "Fare"] = 7.8875
all_data = pd.concat([train.drop(columns = "Survived"), test])
all_data
実行結果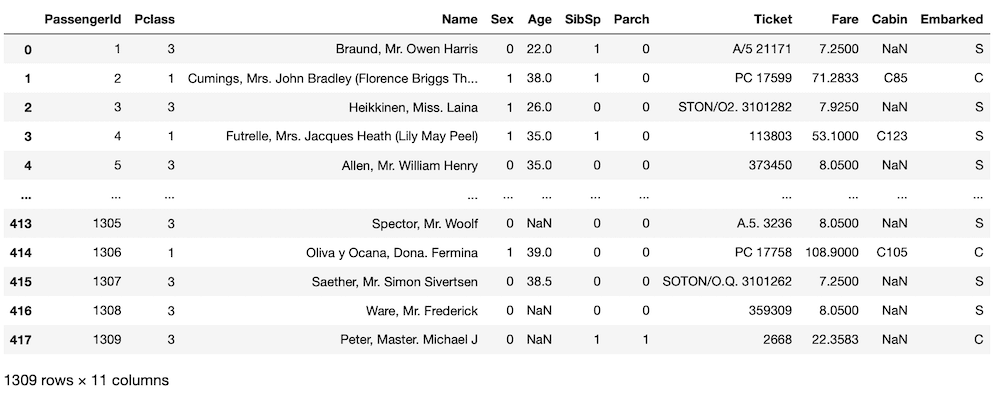
これで前回までの点を修正したデータセットになっています。
訓練用データセット「train」、テスト用データセット「test」と探索用データセットとして「train」と「test」を連結した「all_data」も用意しておきましょう。
それでは欠損値を埋めるための情報収集開始です。
欠損値を修正するための情報収集
まずはEmbarked(乗船地)の欠損値が「train」と「test」のどちらのデータセットにあるのか確認します。
<セル2>
train.isnull().sum()
実行結果
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64<セル3>
test.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
dtype: int64「train」のデータセットの「Embarked」に2つの欠損値があることが確認できました。
ではその欠損値のデータを見てみましょう。
<セル4>
print(all_data[all_data["Embarked"].isnull() == True])
実行結果
PassengerId Pclass Name Sex Age \
61 62 1 Icard, Miss. Amelie 1 38.0
829 830 1 Stone, Mrs. George Nelson (Martha Evelyn) 1 62.0
SibSp Parch Ticket Fare Cabin Embarked
61 0 0 113572 80.0 B28 NaN
829 0 0 113572 80.0 B28 NaN どちらの人もPclass(等級)は「1」、一緒に乗船した家族はいない(SibSp、Parch共に0)、Ticket(チケット番号)が「113572」 、Fare(料金)は「80.0」ドル、Cabin(キャビン)は「B28」です。
この中で絞り込めそうな情報は「Ticket」と「Cabin」でしょうか。
この2つで検索をかけて、同じ「Ticket」か「Cabin」の人がいないか探してみましょう。
<セル5>
print(all_data[all_data["Ticket"] == "113572"])
実行結果
PassengerId Pclass Name Sex Age \
61 62 1 Icard, Miss. Amelie 1 38.0
829 830 1 Stone, Mrs. George Nelson (Martha Evelyn) 1 62.0
SibSp Parch Ticket Fare Cabin Embarked
61 0 0 113572 80.0 B28 NaN
829 0 0 113572 80.0 B28 NaN <セル6>
print(all_data[all_data["Cabin"] == "B28"])
実行結果
PassengerId Pclass Name Sex Age \
61 62 1 Icard, Miss. Amelie 1 38.0
829 830 1 Stone, Mrs. George Nelson (Martha Evelyn) 1 62.0
SibSp Parch Ticket Fare Cabin Embarked
61 0 0 113572 80.0 B28 NaN
829 0 0 113572 80.0 B28 NaN どちらの条件でも、この二人(乗客No.62、830)しか見つかりません。
そうしたらここからは確率論的に考えましょう。
まずEmbarkedはC、S、Qの3箇所。
これがどのような割合になっているのか確認してみます。
<セル7>
all_data["Embarked"].hist()
実行結果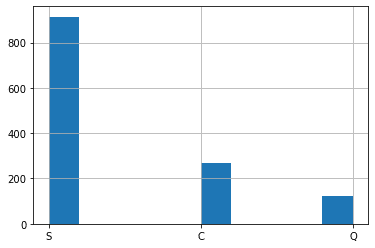
「S」が圧倒的に多いですね。
では同じアルファベットのCabinにいる人のEmbarkedはどうでしょうか?
ちなみにある文字を含んでいるかどうかを確認するには「.str.contains(“検索文字”)」を用います。
<セル8>
all_data[all_data["Cabin"].str.contains("B") == True]["Embarked"].hist()
実行結果
この条件だと「C」と「S」が大体同数くらいになりました。
それでは大体同じくらいの料金(Fare)を支払っている人だとどうでしょうか?
料金が70ドルから90ドルの範囲の人のEmbarkedを確認してみます。
<セル9>
all_data[(all_data["Fare"] > 70) & (all_data["Fare"] <= 90)]["Embarked"].hist()
実行結果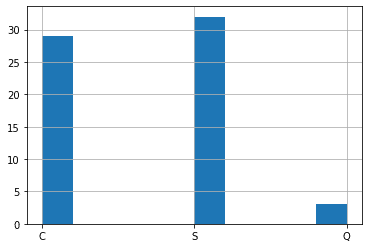
これまた「C」と「S」が同数くらいで、少し「Q」がいると言う感じになりました。
こうなってくるとEmbarkedの値の決め手はないので、もうえいやっと決めてしまいましょう。
ということで今回は全体で一番多かった「S」としてしまいます。
Embarkedを修正して、機械学習・予想、データの提出
それではまずはEmberkedのデータを修正して、修正できたか確認していきます。
<セル10>
train.loc[train["Embarked"].isnull() == True, "Embarked"] = "S"
train.isnull().sum()
実行結果
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 0
dtype: int64これで元々2つあった「Emberked」の欠損値がなくなっていることが確認できました。
次に機械学習モデルを構築していきます。
変数xに「Embarked」を追加して、機械学習させてみます。
<セル11>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked"]]
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=10000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-11-380b34d2ed95> in <module>
9
10 model = LinearSVC(max_iter=10000000)
---> 11 model.fit(x_train, y_train)
12 pred = model.predict(x_test)
13
(中略)
/opt/anaconda3/lib/python3.7/site-packages/numpy/core/_asarray.py in asarray(a, dtype, order)
83
84 """
---> 85 return array(a, dtype, copy=False, order=order)
86
87
ValueError: could not convert string to float: 'S'Embarkedの値が「C」、「S」、「Q」の文字になっているので、機械学習できないとエラーが出てきました。
ということでそれぞれ「0」、「1」、「2」と数字に変えていきます。
ちなみにtrain、test両方とも変更する必要があるので、お忘れなく。
<セル12>
train.loc[train["Embarked"] == "S", "Embarked"] = 0
train.loc[train["Embarked"] == "C", "Embarked"] = 1
train.loc[train["Embarked"] == "Q", "Embarked"] = 2
test.loc[test["Embarked"] == "S", "Embarked"] = 0
test.loc[test["Embarked"] == "C", "Embarked"] = 1
test.loc[test["Embarked"] == "Q", "Embarked"] = 2
実行結果このセルでは何も起こりません。
train、testのデータセットを表示して、確認してみましょう。
<セル13>
train
実行結果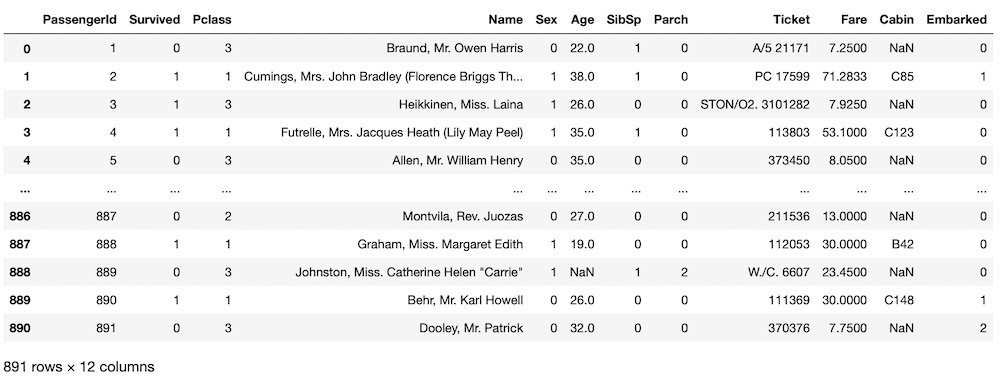
<セル14>
test
実行結果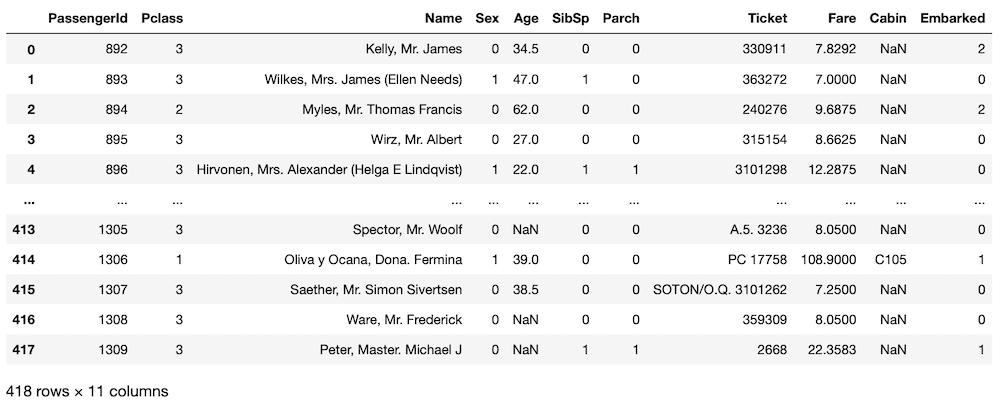
どちらのデータセットでも「Embarked」が数字になっていることが確認できました。
ということで再度、機械学習させてみましょう。
<セル15>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked"]]
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=10000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.8324022346368715ここのスコアは最初が「0.7932960893854749」、Fareの欠損値を修正したものでは「0.8044692737430168」なので、少しずつ上がってきているように見えます。
この機械学習モデルで生存予想をしてデータを出力します。
<セル16>
x_testset = test.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked"]]
pred = model.predict(x_testset)
submit_data = pd.DataFrame()
submit_data["PassengerId"] = test["PassengerId"]
submit_data["Survived"] = pred
submit_data = submit_data.set_index("PassengerId")
submit_data.to_csv("./submit_data_embarked.csv")
実行結果Jupyter notebook上では何も起こりませんが、新たに「submit_data_embarked.csv」というファイルが作成されます。
これに予想データが出力されているので、Kaggleに提出しましょう。
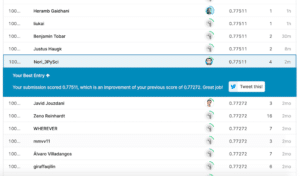
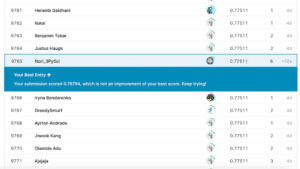
そして今回、提出した結果は…
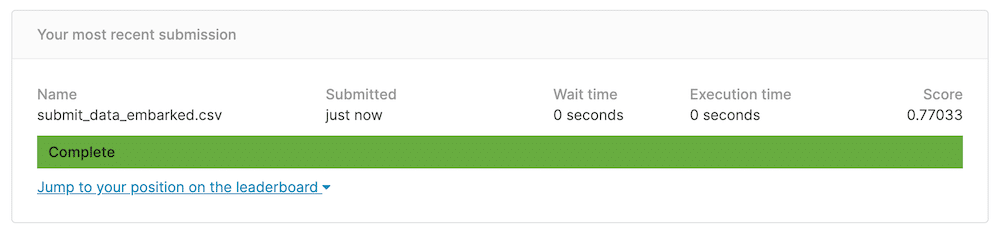
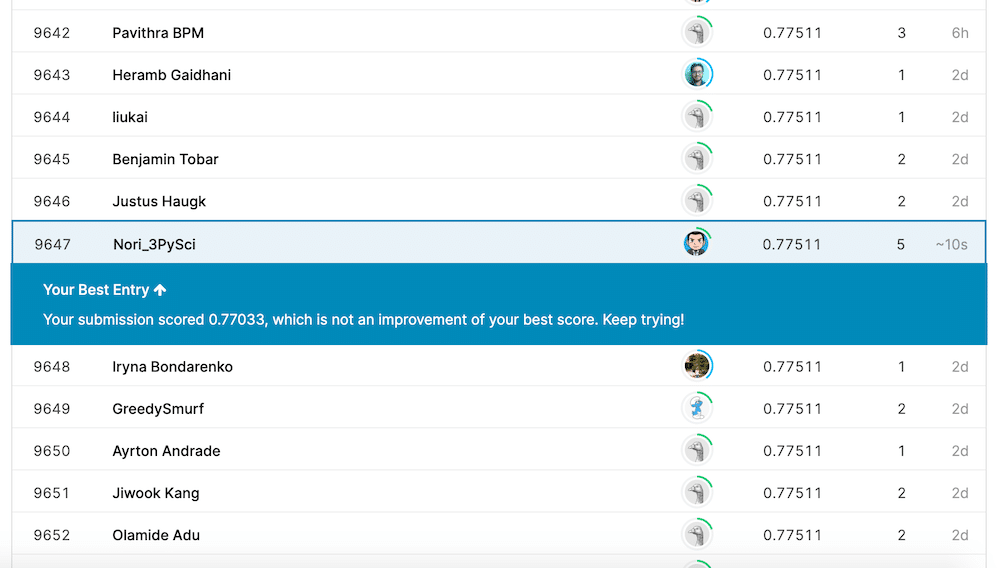
残念ながら前回のスコア「0.77511」を超えることはできませんでした。
次回からは「Age(年齢)」を修正していきますが、結構な数の欠損値があるので何回かに分けて修正していきたいと思います。
ではでは今回はこんな感じで。
コメント