Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットのAgeの欠損値をPclassに注目して分析してみました。
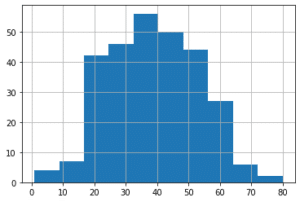
その結果、Pclassが「1」、「2」のものに関しては年齢分布をAgeの欠損値に当て嵌めても良さそうでしたが、「3」のものに関しては全体の年齢分布と変わらないため、もう少し分析が必要そうでした。
ということで今回は名前(Name)と年齢の関係性を読み解いていきたいと思います。
前回と同じく、まずはデータの読み込みとこれまでの修正を行っていきます。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
test.loc[test["Fare"].isnull() == True, "Fare"] = 7.8875
train.loc[train["Embarked"].isnull() == True, "Embarked"] = "S"
train.loc[train["Embarked"] == "S", "Embarked"] = 0
train.loc[train["Embarked"] == "C", "Embarked"] = 1
train.loc[train["Embarked"] == "Q", "Embarked"] = 2
test.loc[test["Embarked"] == "S", "Embarked"] = 0
test.loc[test["Embarked"] == "C", "Embarked"] = 1
test.loc[test["Embarked"] == "Q", "Embarked"] = 2
all_data = pd.concat([train.drop(columns = "Survived"), test])
all_data
実行結果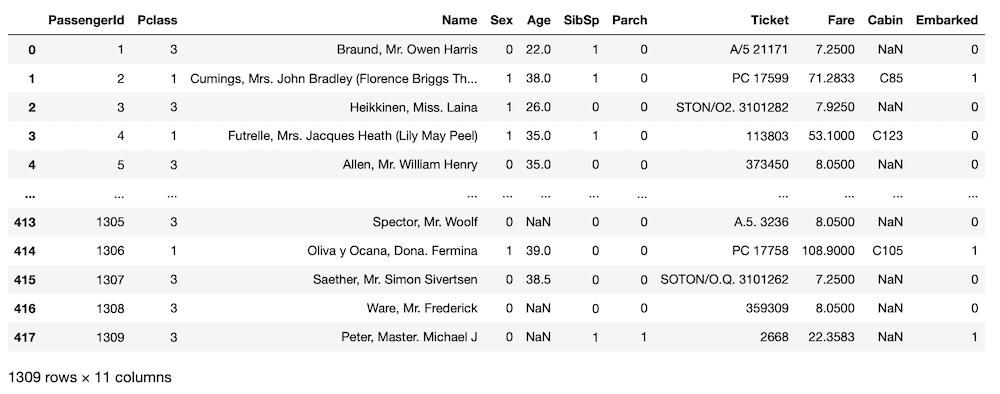
それではNameに注目して解析していきましょう。
Nameの敬称に注目してみる
Nameに注目すると言っても、名前そのものからは年齢を推測するのは難しいです。
もちろん名前の流行り廃りがあるので極論を言えばできなくはないでしょうが、少なくとも私には英語名の、しかもタイタニック号が沈没した1912年頃の名前から年齢を推測することは困難です。
しかし敬称(Mr.とかMrs、Miss)からは何らかの年齢の情報が得られるかもしれません。
ということでまずは名前から敬称を抜き出し、年齢分布を見ていくことにします。
流れとしては、
- 名前の列のデータを一つずつ読み込む
- split関数で姓、名、敬称を分割する
- 敬称にはピリオドが付くので、分割したデータの中でendwith関数で最後にピリオドが付くものを選択する
- 敬称をリストに格納する
という感じで行っていきます。
最初に敬称をリストに格納して、どんな敬称があるのかset関数で重複を省いて表示させてみます。
<セル2>
title_list = []
for name in all_data["Name"]:
for name_split in name.split():
if name_split.endswith(".") == True:
title_list.append(name_split)
title_unique = set(title_list)
print(title_unique)
実行結果
{'Dona.', 'Mme.', 'Countess.', 'Rev.', 'L.', 'Mrs.', 'Sir.', 'Ms.', 'Major.', 'Col.', 'Mlle.', 'Don.', 'Jonkheer.', 'Capt.', 'Mr.', 'Master.', 'Dr.', 'Lady.', 'Miss.'}思ったよりも色々な敬称があるようです。
といっても本当にこれらが敬称なのか確認する必要があります。
これは一つずつ調べていくのが良いでしょう。
Dona. : スペインの貴婦人に対する敬称
Mme. : フランス語の既婚女性に対する敬称
Countess. : イギリス語の伯爵夫人に対する敬称

Rev. : 聖職者に対する敬称
Mrs. : 既婚女性に対する敬称
Sir. : 騎士に与えられる称号、もしくは男性に対する敬称
Ms. : 配偶者の有無に関わらず使われる女性に対する敬称
Major. : 軍の少佐に対する敬称
Col. : 軍の大佐に対する敬称

Mlle.: フランス語の未婚女性に対する敬称
Don. : スペイン語の男性に対する敬称

Jonkheer. : オランダとベルギーの貴族に対する敬称
Capt. : 船長に対する敬称(略称?)
Mr. : 男性に対する敬称
Master. : 少年や青年男性に対する敬称
Dr. : 博士に対する敬称
Lady. : 貴婦人、女侯爵、伯爵夫人などに対する敬称
Miss. : 未婚女性に対する敬称
この時代の敬称はなかなかたくさんあって大変です。
ここまではネットで調べれば情報が得られたのですが、一つだけ「L.」に関しては敬称なのか何なのか調べた限りでは分かりませんでした。
ということで「L.」を持つ人のデータを見てみましょう。
<セル3>
all_data[all_data["Name"].str.contains("L\\.") == True]
実行結果
「Rothschild, Mrs. Martin (Elizabeth L. Barrett)」というのを見ると旧姓なのか別名なのか、どちらにせよこの人は「Mrs.」という敬称をもっているため、「L.」は敬称でないように見えます。
また敬称だったとしても、一人の人が2つの敬称をもっているとその人が2回カウントされることになり、データ数にずれが出てきてしまいます。
ということで「L.」は除外してデータを解析していきましょう。
すると先ほど敬称を分類したときのプログラムがこう変わります。
<セル4>
title_list = []
for name in all_data["Name"]:
for name_split in name.split():
if name_split.endswith(".") == True:
if name_split != "L.":
title_list.append(name_split)
title_unique = set(title_list)
print(title_unique)
実行結果
{'Dona.', 'Col.', 'Mme.', 'Master.', 'Don.', 'Ms.', 'Mlle.', 'Dr.', 'Rev.', 'Capt.', 'Countess.', 'Lady.', 'Jonkheer.', 'Major.', 'Mrs.', 'Sir.', 'Mr.', 'Miss.'}「if name_split != “L.”:」で”L.”以外のものを取得して、リストへ追加しています。
ついでに各敬称の数を数えておきましょう。
<セル5>
for title in title_unique:
title_count = title_list.count(title)
print(str(title) + ":" + str(title_count))
実行結果
Dona.:1
Col.:4
Mme.:1
Master.:61
Don.:1
Ms.:2
Mlle.:2
Dr.:8
Rev.:8
Capt.:1
Countess.:1
Lady.:1
Jonkheer.:1
Major.:2
Mrs.:197
Sir.:1
Mr.:757
Miss.:260多いものもあれば少ないものもありますね。
今回は敬称を一つ一つ調べてきたため、長くなってきましたのでここまで。
次回は敬称に対する年齢分布を見ていきましょう。
ではでは今回はこんな感じで。
コメント