正規表現
前回、よく使う正規表現の特殊文字(メタ文字、メタキャラクタ)をまとめてみました。
今回は正規表現のエスケープ文字(エスケープシーケンス)でできることを勉強していきます。
エスケープシーケンスに関して、前に「「\(バックスラッシュ)」はエスケープ文字としてこの後に来る文字が特殊な意味を持たず、単純に文字列として認識するようにしています。」というお話をしました。
それはそれで間違いではないんですが、エスケープシーケンスを使うと他にも色々できるということを今回は紹介していきます。
それでは始めていきましょう。
文字として認識
まずは前にも紹介した通常なら特殊な意味を持つ文字が、単純に文字列として認識されるという例です。
例として「*(アスタリスク:直前の文字が0回以上繰り返す)」を試してみましょう。
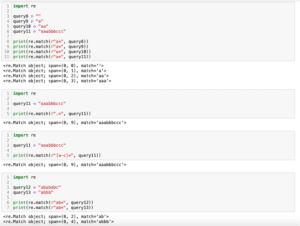
import re
query1 = "*"
print(re.match(r"\*", query1))
print(re.match(r"*", query1))
実行結果
<re.Match object; span=(0, 1), match='*'>
---------------------------------------------------------------------------
error Traceback (most recent call last)
Cell In[3], line 6
3 query1 = "*"
5 print(re.match(r"\*", query1))
----> 6 print(re.match(r"*", query1))
(中略)
error: nothing to repeat at position 0「\*」とすると「*という文字」になるため、query1の「*」とマッチします。
しかしながらバックスラッシュでエスケープしない場合は「直前の文字が0回以上繰り返す」という意味になりますが、直前に文字がないためにエラーとなってしまいました。
このようにエスケープせずに使うと特殊な意味を持つものは下記の表のようなものがあります。
| 特殊文字 | エスケープの仕方 |
| \ | \\ |
| . | \. |
| * | \* |
| + | \+ |
| ? | \? |
| { } | \{ \} |
| ( ) | \( \) |
| [ ] | \[ \] |
| ^ | \^ |
| $ | \$ |
| | | \| |
エスケープすると特殊な意味をもつ文字
ここからは逆にエスケープすると特殊な意味をもつ文字を紹介していきます。
\s:空白文字、\S:空白文字以外
「\s」では空白文字(半角スペース、\t、\n、\r、\f)を、「\S」は空白文字以外を示します。
import re
query2 = " "
query3 = "a"
print(re.match(r"\s", query2))
print(re.match(r"\s", query3))
print(re.match(r"\S", query2))
print(re.match(r"\S", query3))
実行結果
<re.Match object; span=(0, 1), match=' '>
None
None
<re.Match object; span=(0, 1), match='a'>\d:数字、\D:数字以外
「\d」では数字を、「\D」は数字以外を示します。
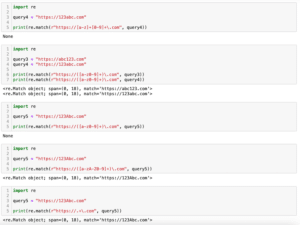
import re
query3 = "a"
query4 = "1"
print(re.match(r"\d", query3))
print(re.match(r"\d", query4))
print(re.match(r"\D", query3))
print(re.match(r"\D", query4))
実行結果
None
<re.Match object; span=(0, 1), match='1'>
<re.Match object; span=(0, 1), match='a'>
None「\d」は「[0-9]」、「\D」は「^0-9」と同じ意味になります。
import re
query3 = "a"
query4 = "1"
print(re.match(r"[0-9]", query4))
print(re.match(r"[^0-9]", query3))
実行結果
<re.Match object; span=(0, 1), match='1'>
<re.Match object; span=(0, 1), match='a'>\w:半角英数字とアンダースコアのうち任意の一文字、 \W:半角英数字とアンダースコア以外の文字のうち任意の一文字
「\w」では半角英数字とアンダースコアのうち任意の一文字を、「\D」は半角英数字とアンダースコア以外の文字のうち任意の一文字を示します。
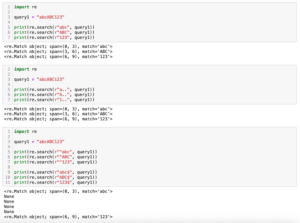
import re
query3 = "a"
query4 = "1"
query5 = "+"
query6 = "A"
print(re.match(r"\w", query3))
print(re.match(r"\w", query4))
print(re.match(r"\w", query5))
print(re.match(r"\w", query6))
print(re.match(r"\W", query3))
print(re.match(r"\W", query4))
print(re.match(r"\W", query5))
print(re.match(r"\W", query6))
実行結果
<re.Match object; span=(0, 1), match='a'>
<re.Match object; span=(0, 1), match='1'>
None
<re.Match object; span=(0, 1), match='A'>
None
None
<re.Match object; span=(0, 1), match='+'>
None「\w」は「[a-zA-Z0-9_]」を、「\D」は「[^a-zA-Z0-9_]」と同じ意味になります。
\l、\L、\u、\UはPythonの正規表現では使えない?
色々なサイトを見ていると「\l」は半角英小文字のうち1文字、\Lは半角英小文字以外のうち1文字、「\u」は半角英大文字のうち1文字、「\U」は半角英大文字以外のうち1文字を表すとされています。
しかしPythonで使ってみたところ、エラーとなってしまいました。
import re
query3 = "a"
print(re.match(r"\l", query3))
実行結果
---------------------------------------------------------------------------
error Traceback (most recent call last)
Cell In[5], line 5
1 import re
3 query3 = "a"
----> 5 print(re.match(r"\l", query3))
(中略)
error: bad escape \l at position 0import re
query3 = "a"
print(re.match(r"\L", query3))
実行結果
---------------------------------------------------------------------------
error Traceback (most recent call last)
Cell In[11], line 5
1 import re
3 query3 = "a"
----> 5 print(re.match(r"\L", query3))
(中略)
error: bad escape \L at position 0import re
query3 = "a"
print(re.match(r"\u", query3))
実行結果
---------------------------------------------------------------------------
error Traceback (most recent call last)
Cell In[6], line 5
1 import re
3 query3 = "a"
----> 5 print(re.match(r"\u", query3))
(中略)
error: incomplete escape \u at position 0import re
query3 = "a"
print(re.match(r"\U", query3))
実行結果
---------------------------------------------------------------------------
error Traceback (most recent call last)
Cell In[12], line 5
1 import re
3 query3 = "a"
----> 5 print(re.match(r"\U", query3))
error: incomplete escape \U at position 0次回はPythonのreモジュールにはどのような関数があるかを紹介していきます。
ではでは今回はこんな感じで。
コメント