Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットのFareの修正値を決めました。
今回は欠損値を修正し、機械学習、予想、そしてkaggelへ提出・スコアの取得を行っていきます。
ということでまずはデータの読み込みから。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
test.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
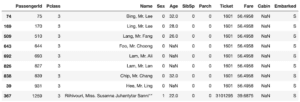
dtype: int64今回、値が欠損していたのはテスト用データのFare(料金)の1つの値でした。
そこで「test.isnull().sum()」でそれぞれの特徴量の欠損値の数を確認してみると、確かにFareで欠損値が一つとなっています。
今回はこの欠損値を「7.8875」に修正します。
Fareの欠損値を修正する
ということで早速値を修正していきます。
<セル2>
test.loc[test["Fare"].isnull() == True, "Fare"] = 7.8875
test.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
dtype: int64「test.isnull().sum()」で確認してみると、確かに欠損値は「0」になりました。
さらにちゃんとFareの値が「7.8875」になっているか、乗客No.1044のデータを確認してみます。
<セル3>
print(test[test["PassengerId"] == 1044])
実行結果
PassengerId Pclass Name Sex Age SibSp Parch Ticket \
152 1044 3 Storey, Mr. Thomas 0 60.5 0 0 3701
Fare Cabin Embarked
152 7.8875 NaN S 間違いなく修正されていることが確認できました。
機械学習して、生存予想をしてみる
次に機械学習をして、それぞれの乗客の生存予想をしていきましょう。
前に予想をした時とほぼ同じですが、変数x(使用する特徴量)に「Fare」を追加します。
ちなみに前に予想を行った時の記事はこちらです。

ということでこんな感じです。
<セル4>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare"]]
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=10000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.8044692737430168前回、ここでのスコアは「0.7932960893854749」だったので、少し良くなっている…でしょうか。
それではテスト用データセットの予想をしてみます。
こちらでも変数x_testsetに「Fare」を追加するのを忘れないようにしてください。
<セル5>
x_testset = test.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare"]]
pred = model.predict(x_testset)
print(pred)
実行結果
[0 1 0 0 1 0 1 0 1 0 0 0 1 0 1 1 0 0 1 1 0 0 1 0 1 0 1 0 0 0 0 0 1 1 0 0 1
1 0 0 0 0 0 1 1 0 0 0 1 1 0 0 1 1 0 0 0 0 0 1 0 0 0 1 0 1 1 0 0 1 1 0 1 0
1 0 0 1 0 1 0 0 0 0 0 0 1 1 1 0 1 0 1 0 0 0 1 0 1 0 1 0 0 0 1 0 0 0 0 0 0
1 1 1 1 0 0 1 0 1 1 0 1 0 0 1 0 1 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0
0 0 1 0 0 1 0 0 1 1 0 1 1 0 1 0 0 1 0 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 1 0 1
0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 1 0 0 1 0 0 1 0 1 0 0 0 0 1 0 0 1 0 1 0 1 0
1 0 1 1 0 1 0 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 0 0 1 0 1 1 1 0 0 0 0 0 0 0 1
0 0 0 1 1 0 0 0 0 1 0 0 0 1 1 0 1 0 0 0 0 1 0 1 1 1 0 0 0 0 0 0 1 0 0 0 0
1 0 0 0 0 0 0 0 1 1 0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1 0 0
1 0 0 0 0 0 0 0 0 0 1 0 1 0 1 0 1 1 0 0 0 1 0 1 0 0 1 0 1 1 0 1 0 0 1 1 0
0 1 0 0 1 1 1 0 0 0 0 0 1 1 0 1 0 0 0 0 0 1 0 0 0 1 0 1 0 0 1 0 1 0 0 0 0
0 1 1 1 1 1 0 1 0 0 0]そして提出用ファイルを出力します。
<セル6>
submit_data = pd.DataFrame()
submit_data["PassengerId"] = test["PassengerId"]
submit_data["Survived"] = pred
submit_data = submit_data.set_index("PassengerId")
submit_data.to_csv("./submit_data_fare.csv")出力された「submit_data_fare.csv」をKaggleに提出します。
提出方法はこちらの記事で解説していますので、良かったらご覧ください。
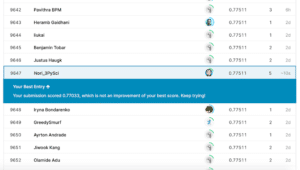
で、今回の結果は…
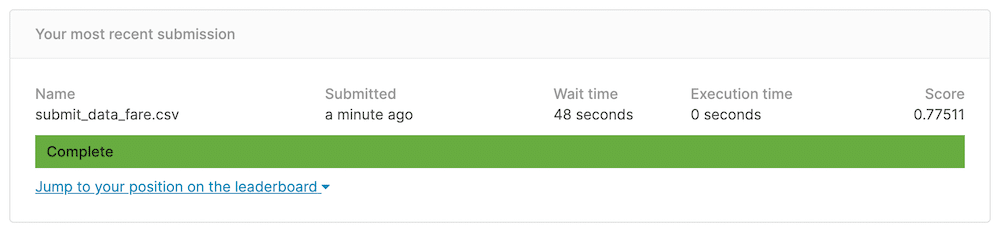
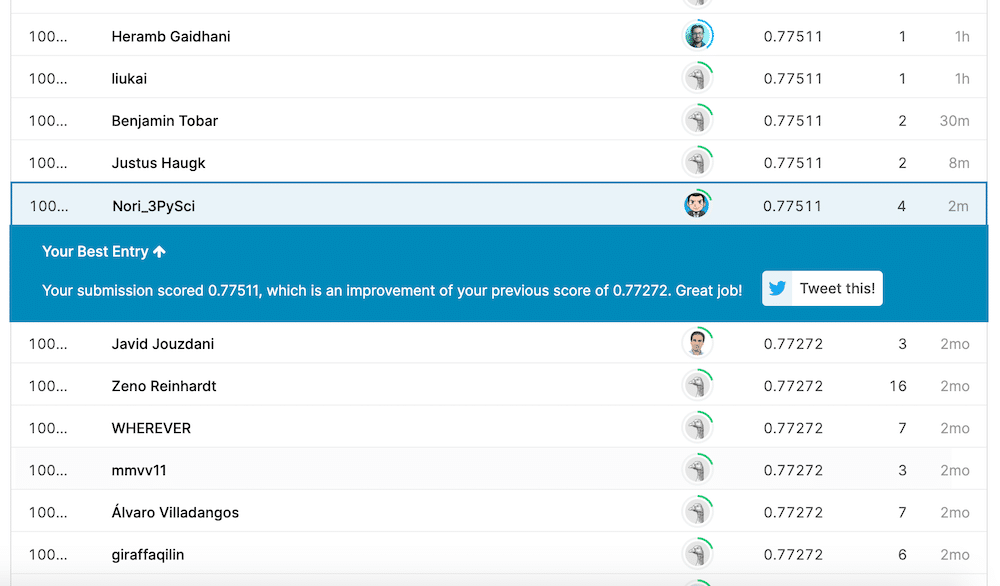
前のスコアが「0.77272」だったのに対し、今回は「0.77511」とほんの少し良くなりました。
機械学習にブレはあるので、スコアが良くなった要因がモデルが良くなったからなのか、たまたまなのか分かりませんが、まぁよしとしましょう。
次回からは訓練用データセットに2つの欠損値がある「Embarked(乗船地)」のデータを修正していきます。
ではでは今回はこんな感じで。
コメント