Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットのAgeの欠損値をランダムに設定してみました。
今回もランダム値を使っていきますが、年齢が分かっている乗客の年齢分布をランダム値の重みとして使うことで、全体の統計値を崩さないようにランダムな年齢を設定していきます。
ということで前回同様、データの読み込みとこれまでの修正を行っていきます。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
test.loc[test["Fare"].isnull() == True, "Fare"] = 7.8875
train.loc[train["Embarked"].isnull() == True, "Embarked"] = "S"
train.loc[train["Embarked"] == "S", "Embarked"] = 0
train.loc[train["Embarked"] == "C", "Embarked"] = 1
train.loc[train["Embarked"] == "Q", "Embarked"] = 2
test.loc[test["Embarked"] == "S", "Embarked"] = 0
test.loc[test["Embarked"] == "C", "Embarked"] = 1
test.loc[test["Embarked"] == "Q", "Embarked"] = 2
all_data = pd.concat([train.drop(columns = "Survived"), test])
all_data
実行結果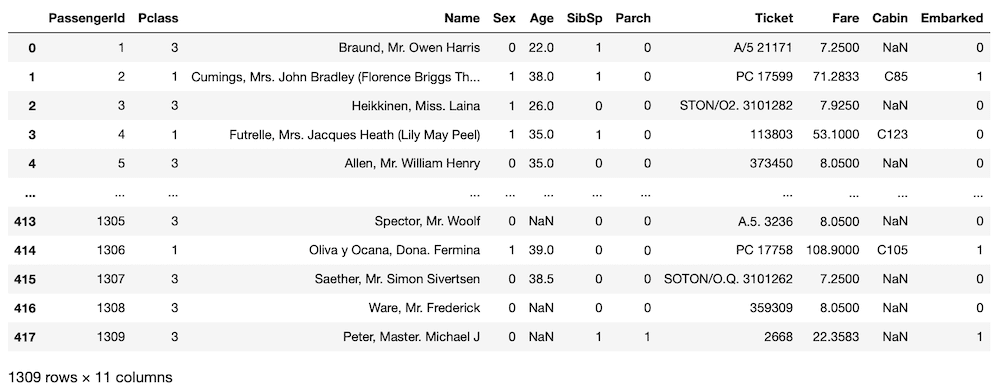
ついでに現在の訓練用データセットとテスト用データセットの年齢分布のグラフ(ヒストグラム)を確認しておきましょう。
<セル2>
train["Age"].hist()
実行結果
<セル3>
test["Age"].hist()
実行結果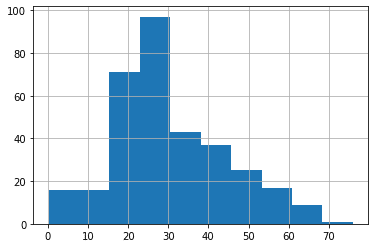
それでは始めていきましょう。
年齢分布の数値データを取得する
まずは年齢分布の数値データを取得していきます。
その際には「.value_counts()」という関数を用います。
<セル4>
age_values = all_data["Age"].value_counts()
age_values
実行結果
24.00 47
22.00 43
21.00 41
30.00 40
18.00 39
..
76.00 1
22.50 1
74.00 1
80.00 1
0.67 1
Name: Age, Length: 98, dtype: int64この「.value_counts()」は、個数の多い順に出力されます。
このままでは使いにくいので、年齢値(ここではインデックスとして使用)の昇順に並び替えます。
インデックスの並び替えをするには「.sort_index()」を使います。
<セル5>
age_values = age_values.sort_index()
age_values
実行結果
0.17 1
0.33 1
0.42 1
0.67 1
0.75 3
..
70.50 1
71.00 2
74.00 1
76.00 1
80.00 1
Name: Age, Length: 98, dtype: int64これで昇順になりました。
しかし現状のデータはPandasのシリーズ(一列のデータ)になっています。
<セル6>
print(type(age_values))
実行結果
<class 'pandas.core.series.Series'>やはり使いにくいので、numpyのarray(配列)に変換しておきます。
<セル7>
import numpy as np
age_values = np.array(age_values)
age_values
実行結果
array([ 1, 1, 1, 1, 3, 3, 2, 10, 12, 7, 10, 5, 6, 4, 6, 10, 4,
4, 1, 3, 5, 8, 2, 6, 19, 20, 39, 3, 29, 23, 1, 41, 43, 1,
26, 1, 47, 1, 34, 30, 1, 30, 32, 3, 30, 40, 2, 23, 24, 4, 21,
16, 2, 23, 31, 2, 9, 14, 1, 20, 18, 3, 11, 18, 9, 10, 21, 2,
6, 14, 14, 9, 15, 8, 6, 4, 10, 8, 1, 4, 5, 6, 3, 7, 1,
5, 5, 4, 5, 3, 1, 1, 2, 1, 2, 1, 1, 1])次に年齢のリストを作成したいので、「.unique()」の関数を使い、重複しない年齢の一覧を取得します。
<セル8>
age_list = all_data["Age"].unique()
age_list
実行結果
array([22. , 38. , 26. , 35. , nan, 54. , 2. , 27. , 14. ,
4. , 58. , 20. , 39. , 55. , 31. , 34. , 15. , 28. ,
8. , 19. , 40. , 66. , 42. , 21. , 18. , 3. , 7. ,
49. , 29. , 65. , 28.5 , 5. , 11. , 45. , 17. , 32. ,
16. , 25. , 0.83, 30. , 33. , 23. , 24. , 46. , 59. ,
71. , 37. , 47. , 14.5 , 70.5 , 32.5 , 12. , 9. , 36.5 ,
51. , 55.5 , 40.5 , 44. , 1. , 61. , 56. , 50. , 36. ,
45.5 , 20.5 , 62. , 41. , 52. , 63. , 23.5 , 0.92, 43. ,
60. , 10. , 64. , 13. , 48. , 0.75, 53. , 57. , 80. ,
70. , 24.5 , 6. , 0.67, 30.5 , 0.42, 34.5 , 74. , 22.5 ,
18.5 , 67. , 76. , 26.5 , 60.5 , 11.5 , 0.33, 0.17, 38.5 ])こちらもこのままでは使いにくいので、昇順に変換します。
ただここで注意点です。
先ほど年齢分布のインデックス値である年齢を並び替えた場合は「.sort_index()」を使いましたが、これはPandasの関数です。
今回はnumpyのarray(配列)の並び替えなので、「np.sort(“並び替えるnumpy array”)」を使います。
<セル9>
age_list = np.sort(age_list)
age_list
実行結果
array([ 0.17, 0.33, 0.42, 0.67, 0.75, 0.83, 0.92, 1. , 2. ,
3. , 4. , 5. , 6. , 7. , 8. , 9. , 10. , 11. ,
11.5 , 12. , 13. , 14. , 14.5 , 15. , 16. , 17. , 18. ,
18.5 , 19. , 20. , 20.5 , 21. , 22. , 22.5 , 23. , 23.5 ,
24. , 24.5 , 25. , 26. , 26.5 , 27. , 28. , 28.5 , 29. ,
30. , 30.5 , 31. , 32. , 32.5 , 33. , 34. , 34.5 , 35. ,
36. , 36.5 , 37. , 38. , 38.5 , 39. , 40. , 40.5 , 41. ,
42. , 43. , 44. , 45. , 45.5 , 46. , 47. , 48. , 49. ,
50. , 51. , 52. , 53. , 54. , 55. , 55.5 , 56. , 57. ,
58. , 59. , 60. , 60.5 , 61. , 62. , 63. , 64. , 65. ,
66. , 67. , 70. , 70.5 , 71. , 74. , 76. , 80. , nan])こちらの年齢のリストには最後に「nan」が含まれていますのが、先ほどの年齢分布のリストには「nan」の個数は含まれていません。
つまりこちらの年齢のリストは、年齢分布のリストに比べて1つデータが多いことを覚えておいてください。
重みありランダム値でAgeの欠損値を修正する
ここから重みありランダム値を使ってAge(年齢)の欠損値を修正していきます。
まずは修正すべき欠損値の個数を確認します。
<セル10>
all_data.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 263
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 1014
Embarked 0
dtype: int64今回は欠損値の個数よりも多い個数の修正値を重みありランダム値で先に準備しておき、欠損値を順番に一つずつ置き換えていくという手法をとってみます。
重みありのランダム値を取得するには、「randam.choices(ランダム値のリスト, 出力するランダム値の個数, weights=重みのリスト)」を使用します。
今回、置き換える欠損値の個数は「263個」ですので、300個のランダム値を出力してみます。
<セル11>
import random
random_age_list = random.choices(age_list[:-1], k = 300, weights = age_values)
random_age_list = np.array(random_age_list)
random_age_list
実行結果
array([ 8. , 27. , 31. , 36. , 36. , 23.5 , 36. , 26. , 32. ,
56. , 22. , 51. , 30. , 24. , 1. , 34. , 20. , 17. ,
51. , 48. , 29. , 40.5 , 49. , 16. , 33. , 36. , 30. ,
70. , 26. , 25. , 50. , 42. , 41. , 26. , 11. , 18. ,
25. , 48. , 20.5 , 19. , 27. , 42. , 40. , 48. , 35. ,
36. , 0.33, 29. , 18.5 , 21. , 32. , 38. , 28. , 52. ,
27. , 20. , 2. , 0.75, 20. , 26. , 51. , 45. , 58. ,
2. , 36. , 56. , 33. , 4. , 28. , 24. , 48. , 37. ,
40. , 39. , 35. , 23. , 23. , 58. , 28. , 27. , 34. ,
3. , 18. , 49. , 25. , 31. , 47. , 18. , 23. , 21. ,
19. , 15. , 26. , 34. , 27. , 28. , 31. , 18. , 8. ,
(以下略)
使いやすいよう途中でnumpyのarrayに変換しています。
この300個のランダム値をAgeの欠損値と置き換えていきます。
<セル12>
random_list_no = 0
for i in range(len(train)):
if np.isnan(train.iloc[i, 5]) == True:
train.iloc[i, 5] = random_age_list[random_list_no]
random_list_no = random_list_no + 1
for i in range(len(test)):
if np.isnan(test.iloc[i, 4]) == True:
test.iloc[i, 4] = random_age_list[random_list_no]
random_list_no = random_list_no + 1「random_list_no」を先ほどのランダム値のリストのインデックスとして使用しますので、最初に「random_list_no = 0」と定義しておきます。
次にfor文を使って、訓練用データセットのデータの番号を一つずつ取得し、変数iに代入します。
その変数iを使ってAgeが「NaN」のもののみ分類し、ランダム値のリストから一つとっては欠損値と置き換えるということをしています。
それがこの部分です。
for i in range(len(train)):
if np.isnan(train.iloc[i, 5]) == True:
train.iloc[i, 5] = random_age_list[random_list_no]
random_list_no = random_list_no + 1そして欠損値はテスト用データセットにも含まれますので、同様にして欠損値を一つずつ置き換えて行っています。
for i in range(len(test)):
if np.isnan(test.iloc[i, 4]) == True:
test.iloc[i, 4] = random_age_list[random_list_no]
random_list_no = random_list_no + 1ちなみに前回解説しましたが、「train.iloc[i, 5]」と「test.iloc[i, 4]」で取得している列(trainでは5=6列目、testでは4=5列目)が異なっていますが、これは訓練用データセットでは「survived」の列が挿入されているため、列番号がずれているということです。
欠損値が修正されたか確認してみましょう。
<セル13>
train.isnull().sum()
実行結果
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 0
dtype: int64<セル14>
test.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
dtype: int64Ageの欠損値は訓練用データセットもテスト用データセットも「0」になりました。
この時点での年齢分布のグラフも確認しておきましょう。
<セル15>
train["Age"].hist()
実行結果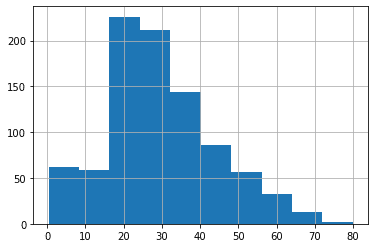
<セル16>
test["Age"].hist()
実行結果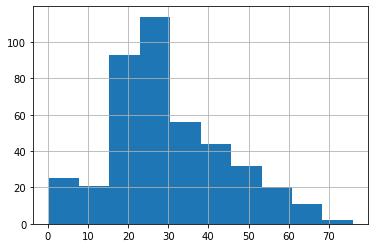
それぞれ欠損値修正前後で比較してみましょう。
| 修正前 | 修正後 | |
| train | | |
| test | | |
欠損値修正前後で年齢分布の大幅な変更はないことが確認できました。
機械学習・予測
ここのプログラムは前回と変わりありません。
<セル17>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = train.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked", "Age"]]
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=10000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.770949720670391これまでのこの時点でのスコアはこんな感じでした。
| 修正項目 | 機械学習スコア |
| 初期(修正なし) | 0.79330 |
| Fare | 0.80447 |
| Embarked | 0.83240 |
| Age(平均値) | 0.81564 |
| Age(ランダム値) | 0.74860 |
前回、Ageをランダム値で修正した時が一番低いスコアになっていましたが、今回はそれに次ぐ低いスコアになりました。
とりあえずこのままKaggleに提出してみましょう。
ということで得られたスコアがこちら。

残念ながら今回はスコアは改善しませんでした。
まぁそういうこともあるさと、気持ちを切り替えていきましょう。
次回は少し考えを変えて、機械学習でAge(年齢)を予測させて、それを修正値として使用し、生存予測をしてみるという2段構えの機械学習を試してみたいと思います。
ではでは今回はこんな感じで。
コメント