Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットのAgeの欠損値を重みありのランダムに設定してみました。
今回はAge(年齢)の欠損値を機械学習で予想できるのかを試してみたいと思います。
そして精度よく予想できたら、その値を使って、さらに生存予測をしていくという戦略です。
ではまずは前回同様、データの読み込みとこれまでの修正を行っていきます。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
test.loc[test["Fare"].isnull() == True, "Fare"] = 7.8875
train.loc[train["Embarked"].isnull() == True, "Embarked"] = "S"
train.loc[train["Embarked"] == "S", "Embarked"] = 0
train.loc[train["Embarked"] == "C", "Embarked"] = 1
train.loc[train["Embarked"] == "Q", "Embarked"] = 2
test.loc[test["Embarked"] == "S", "Embarked"] = 0
test.loc[test["Embarked"] == "C", "Embarked"] = 1
test.loc[test["Embarked"] == "Q", "Embarked"] = 2
all_data = pd.concat([train.drop(columns = "Survived"), test])
all_data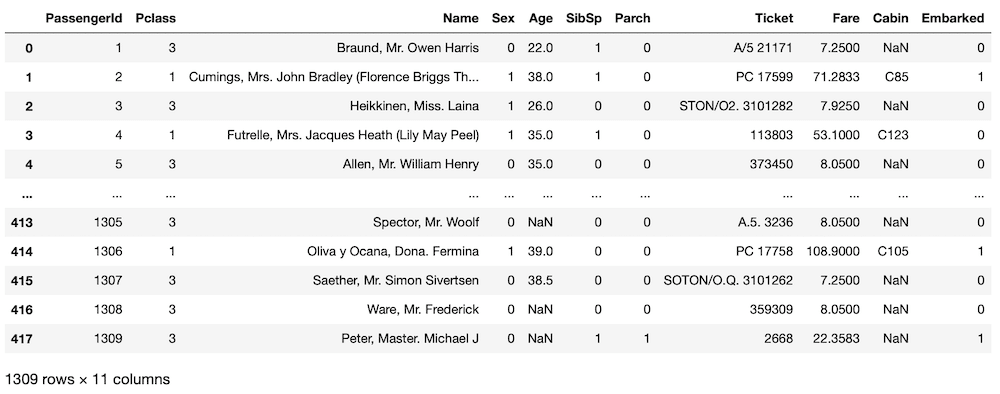
そしてAge(年齢)の欠損値の数を確認しておきましょう。
<セル2>
all_data.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 263
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 1014
Embarked 0
dtype: int641309個のデータ中、263個のデータが欠損しています。
この状況からAgeの値を機械学習・予想するプログラムを作成していきましょう。
Ageに対する機械学習の準備
Ageの値が欠損していない1046個のデータを訓練用データセットとして機械学習させていきます。
ということでAgeの値が欠損していないデータと欠損しているデータを寄り分けます。
<セル3>
Age_yes = all_data[all_data["Age"].isnull() == False]
Age_no = all_data[all_data["Age"].isnull() == True]
実行結果「Age_yes」にAgeの値が欠損していないデータを、「Age_no」にAgeの値が欠損しているデータを寄り分けました。
ここでは寄り分けただけなので、実行しても何も起こっていないように見えます。
それぞれのデータを表示してみましょう。
<セル4>
Age_yes
実行結果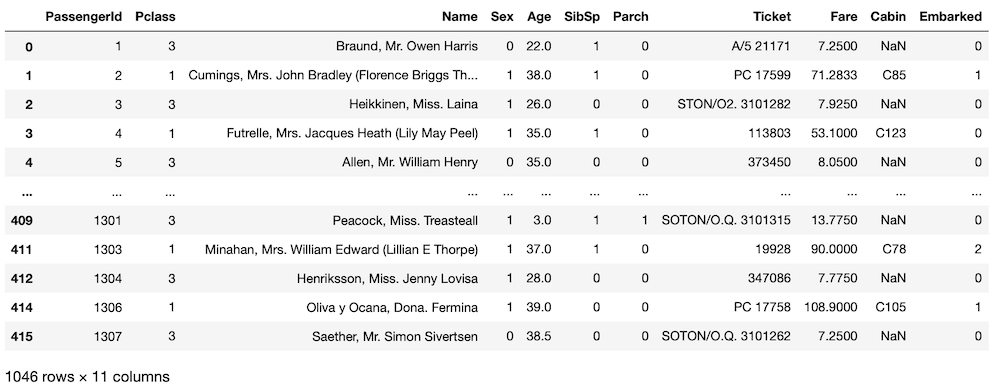
<セル5>
Age_no
実行結果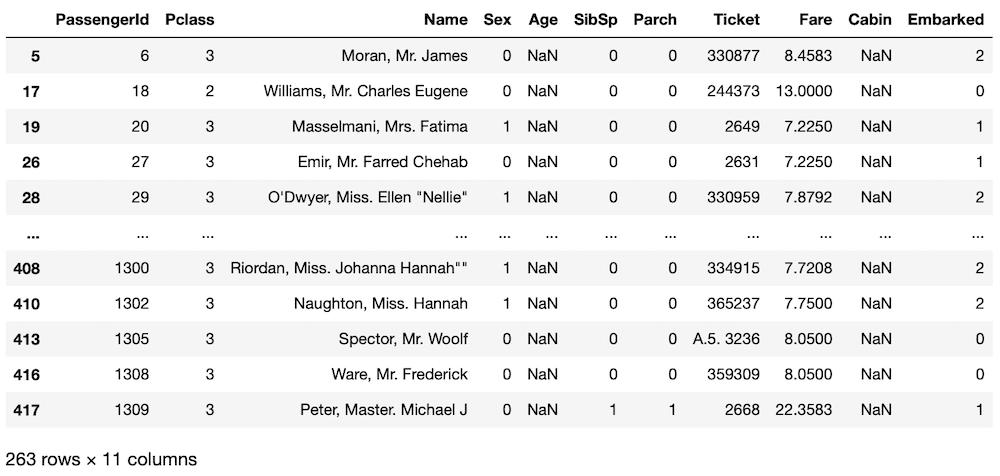
これでAgeが欠損していないデータと欠損しているデータにより分けることができました。
一応、それぞれのデータセットの欠損値の数を確認しておきましょう。
<セル6>
Age_yes.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 774
Embarked 0
dtype: int64<セル7>
Age_no.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 263
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 240
Embarked 0
dtype: int64確かに寄り分けられています。
機械学習を試してみる
ではAgeのデータが欠損していないデータセット「Age_yes」を使って機械学習させてみましょう。
今回は数値を予想したいので、回帰(Regression)になります。
ということで一番基本的な「LinearRegression」モデルを使って機械学習させてみます。
今のところ、欠損していないデータは「Pclass」、「Sex」、「SibSp」、「Parch」、「Fare」、「Embarked」ですのでとりあえず全部説明変数として使ってみることにします。
<セル8>
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
x = Age_yes.loc[:, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked"]]
y = Age_yes["Age"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearRegression()
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(r2_score(y_test, pred))
実行結果
0.17765627431220632スコアが「0.17766」というかなり低いスコアになってしまいました。
これでは満足に予想できているとは言えません。
その原因を探るため、それぞれの値間の相関係数を計算してみます。
<セル9>
corr = Age_yes.corr()
corr
実行結果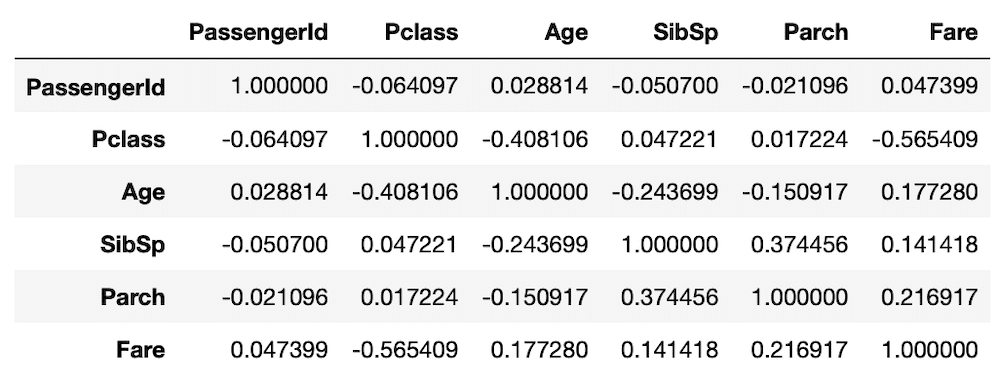
Ageの列を見てみると、「Pclass」が-0.48106となっており、負の相関が少しあるように見えます。
他の値は残念ながら、ほとんど相関がないようです。
ということで説明変数を「Pclass」だけにして、再度機械学習を試してみます。
<セル10>
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
x = Age_yes.loc[:, ["Pclass"]]
y = Age_yes["Age"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearRegression()
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(r2_score(y_test, pred))
実行結果
0.13841400089854328「0.13841」とかなり低いスコアとなってしまいました。
ということは機械学習でAge(年齢)の値を予測するのは難しそうということです。
残念ながらこのアイデアはボツということで、次回からはもう少し地道にAgeの欠損値を埋めていく方法をかんがえていきましょう。
ではでは今回はこんな感じで。
コメント