Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の一番基本なデータセット「タイタニック号乗客の生存予測」のコンペティションの内容を確認しました。
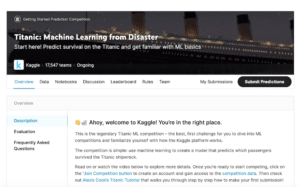
今回はデータセットをダウンロードして、自分のパソコン上で読み込んでみましょう。
データセットのダウンロード
ということで早速Kaggleにログインします。
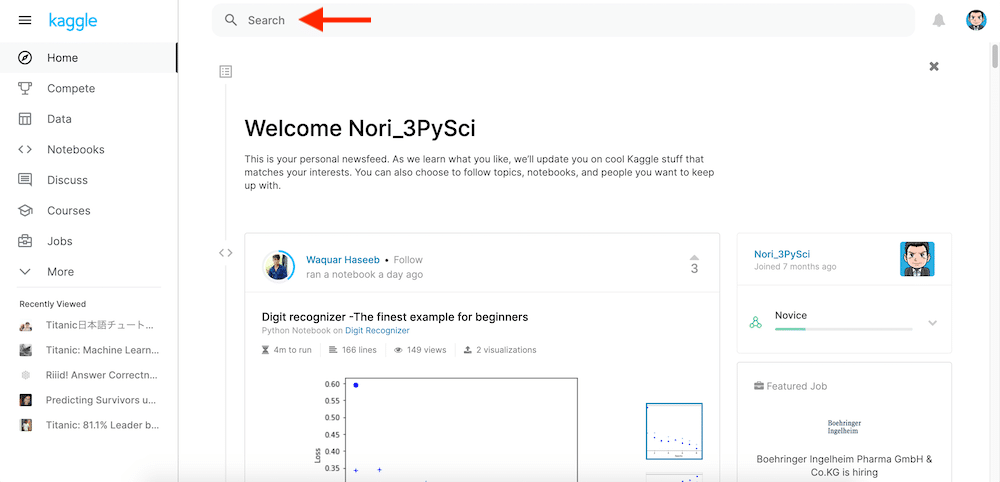
ログインしたら、上部の検索窓で「titanic」を検索します。
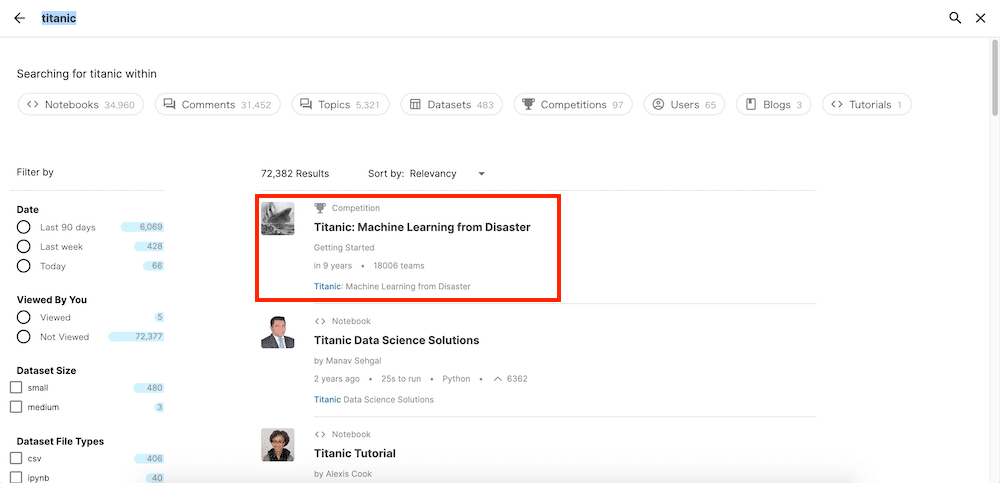
「Titanic:Machine Learning from Disaster」のコンペティションを探します。
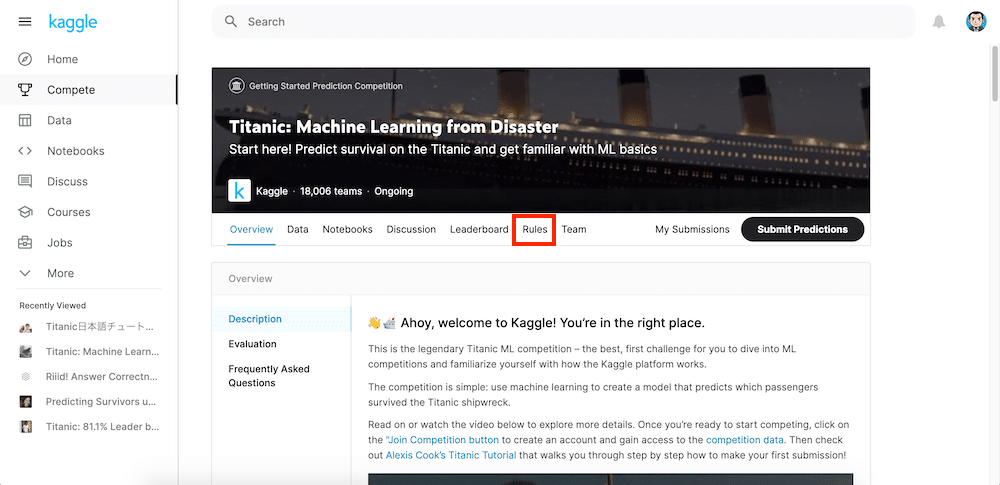
「Rule」のタブをクリックします。
このコンペティションのルールに同意していたら、「You have accepted the rules from this competition. Good luck!」と表示されているはずです。
まだ同意していなかったら、「By clicking on the “I understand and accept” button, you indicate that you agree to be bound with the rules outlined below.」という文章と「I Understand and Accept」というボタンが表示されていることと思います。

この場合は、ルールを確認して、問題なければ「I Understand and Accept」ボタンをクリックします。
ルールに同意したら、「Data」タブをクリックします。
「Data」タブでは下の方にスクロールします。
途中で「Kaggle competitions download -c titanic」という表記が現れますが、こちらは多分Kaggle上のnotebookでこのデータセットを使う場合のコマンドだと思われます。

自分のPC上でデータを扱いたい人はもっと下まで行きます。
「Download All」というボタンがデータセットのダウンロードボタンです。
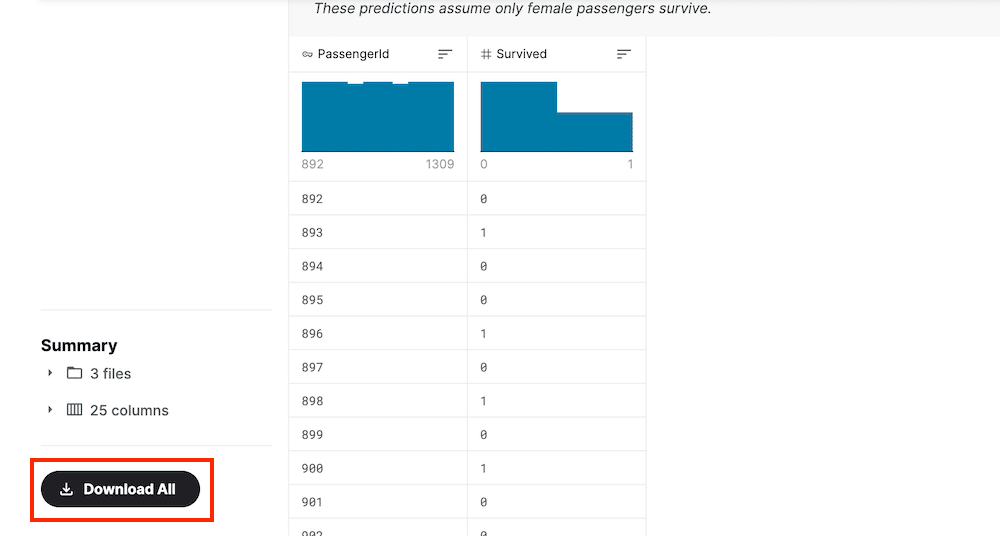
このボタンをクリックしてデータセットをダウンロードしましょう。
データセットの確認
「titanic.zip」というファイルがダウンロードされたことでしょう。
ただしダウンロードされたデータセットはZip形式で圧縮されていますので、まずは展開が必要です。
Macの場合、ダブルクリックすれば同じフォルダ内で展開されます。
「titanic」というフォルダが作成されたら、ダブルクリックして中身を確認してみましょう。
「gender_submission.csv」、「test.csv」、「train.csv」という3つのファイルがありました。
これがこの「タイタニック号乗客の生存予測」のデータセットの全部です。
Jupyter Notebookで読み込んでみる
それではJupyter Notebookでこれらのデータを読み込んで、とりあえず表示させてみましょう。
まずは訓練用データセット「train.csv」から。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
train
実行結果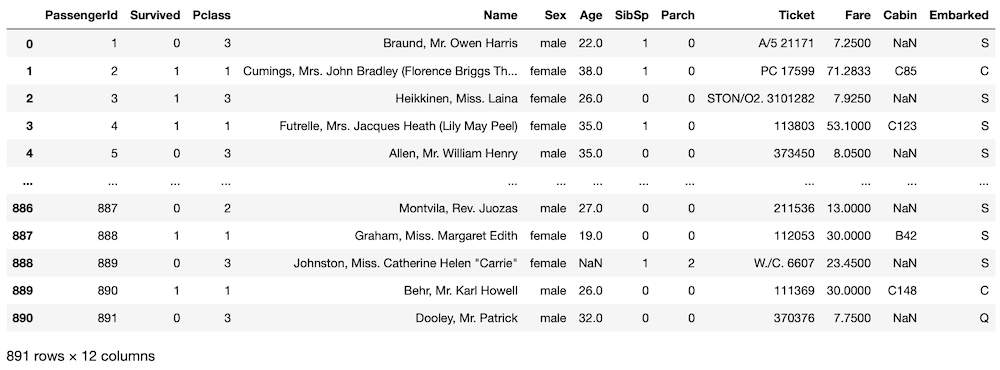
次にテスト用データセット「test.csv」です。
<セル2>
test = pd.read_csv("test.csv")
test
実行結果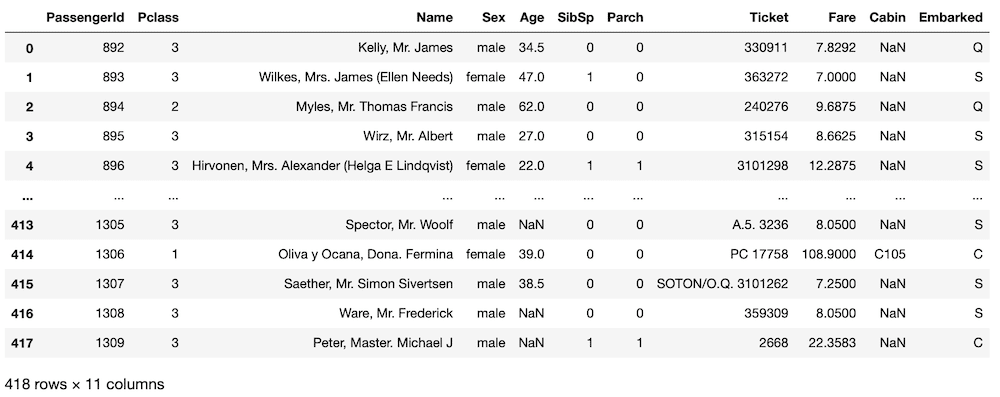
先ほどの「train.csv」とは異なり、「Survived(生存)」の列がありません。
今回のデータセットではここを予想するということになります。
最後に「gender_submission.csv」というファイル。
<セル3>
gender_submission = pd.read_csv("gender_submission.csv")
gender_submission
実行結果
表示してみたら分かりました。
これは提出するデータの形式を示してくれているファイルです。
ただし答えはでたらめのようなので、あくまでもこういう形式でファイルを提出してくださいよと示しているだけのものです。
ということで「train.csv」で機械学習し、そのモデルを使って「test.csv」で生存予想をするという流れになります。
次回は訓練用データセットを眺めていくことにしましょう。
ではでは今回はこんな感じで。
コメント