Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」に登録してみました。
今回はkaggleに登録したほとんどの人が最初にやるだろう「タイタニック号乗客の生存予測」のデータセットを見ていきましょう。
まずは「タイタニック号乗客の生存予測」のデータセットへのアクセスから。
Kaggleにログインし、左のメニューの「Compete」をクリック。
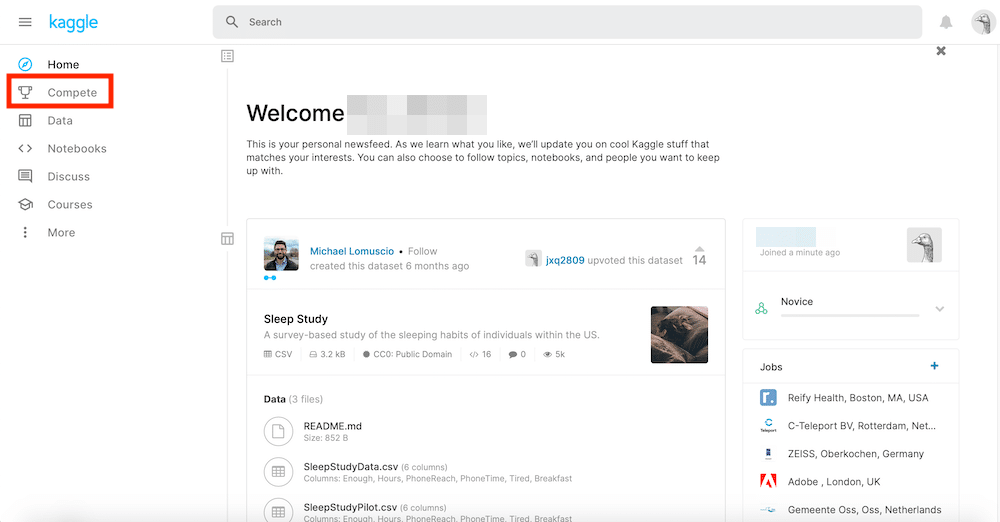
上の「Search」のウインドウにtitanicと入力しEnterを押します。
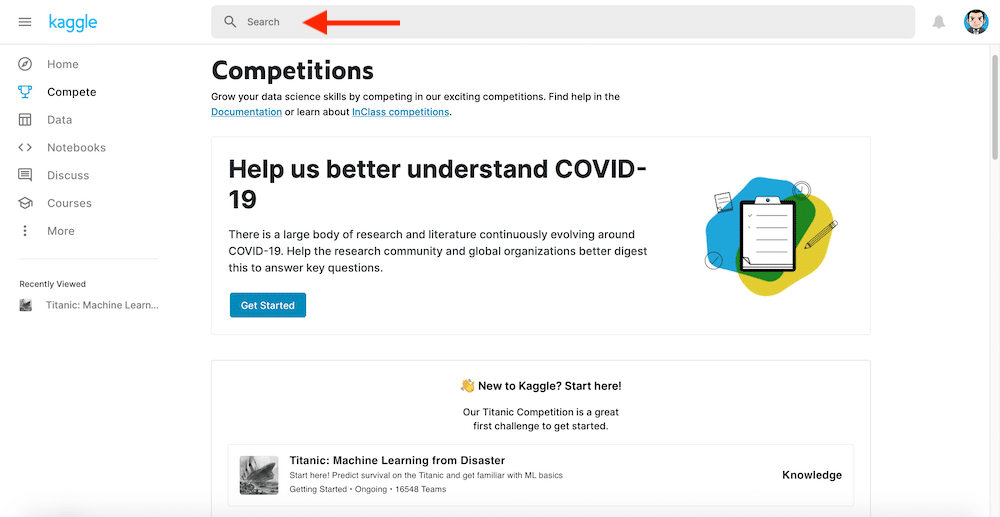
出てきたリストの中で「Titanic: Machine Learning from Disaster」をクリック。

これで「タイタニック号乗客の生存予測」のデータセットのページに到達できました。
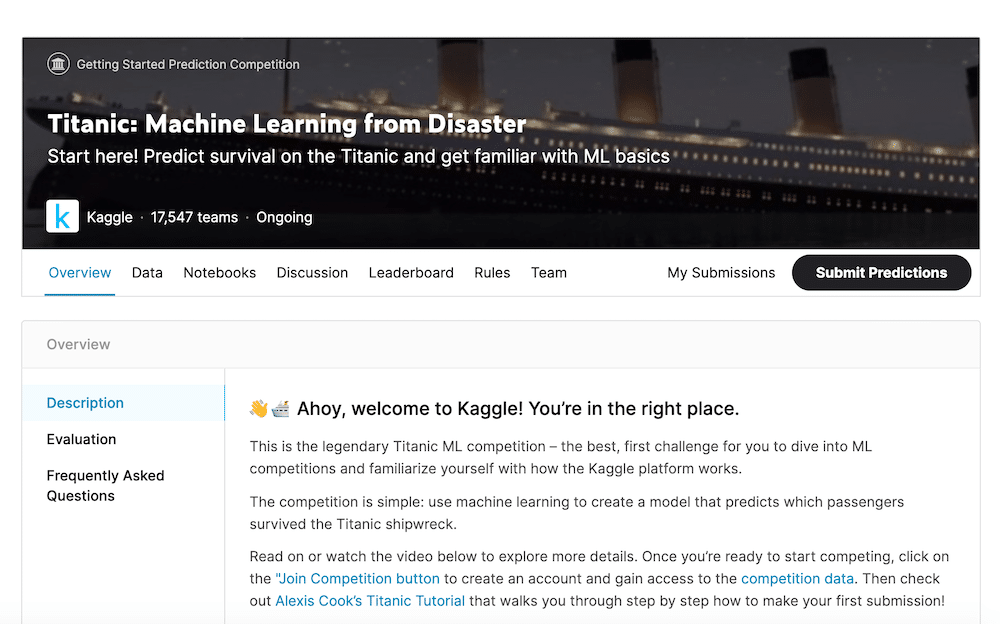
Overview:概要
まずは上のメニューのうち、「Overview (概要)」を確認していきましょう。
「Overview」には「Description(説明)」、「Evaluation(評価)」、「Frequently Asked Questions(よく寄せられる質問)」の3つのサブメニューがあります。
Description:説明
Descriptionではこのデータセットの説明をしています。
どういう経緯のデータで、どんな特徴量があり、何を予想するのかが書かれていますので、良い結果を出すためにも、しっかり読んでおくのがいいでしょう。
上から順に見ていきましょう。

最初にはこのタイタニック号のデータセットは機械学習を最初にやるデータセットで、これを使ってKaggleに慣れましょうといった感じのことが書かれています。
次は「The Challenge」という項目になっています。
このデータセットの背景が書かれていて、いくつかの特徴量からどんな人が生き延びられたのかを予想するモデルを構築するのが目標とのことです。
「Overview of How Kaggles’s Competitions Work」ではKaggleのコンペティションの流れを説明しています。

- Join the Competition(コンペティション参加する)
- 説明を読んで、コンペティションのルールに同意して、データセットを受け取る
- Get to Work(取り組む)
- モデルを組み立て、予想の結果ファイルを作成する
- Make a Submission(提出する)
- 予想ファイルをアップロードして、スコアを受け取る
- Check the Leaderboard(順位を確認する)
- 自分の予想モデルの順位をリーダーボードで確認する
- Improve Your Score(スコアを改善する)
- discussion forumを確認して、多くのチュートリアルや他の参加者から知見を得る
「What Data Will I Use in This Competition?」では、このコンペティションではどんなデータを受け取るのか書かれています。

今回は特徴量と生存・死亡データが記された学習用の「Train.csv」と、特徴量だけが記された「test.csv」というデータを受け取ります。
そして「test.csv」に対して生存・死亡を予想し、その予想結果ファイルをアップロードします。
「How to Submit your Prediction to Kaggle」では、データのアップロードの方法が書かれています。
データをアップロードするには、まず「Submit Predictions」をクリックします。
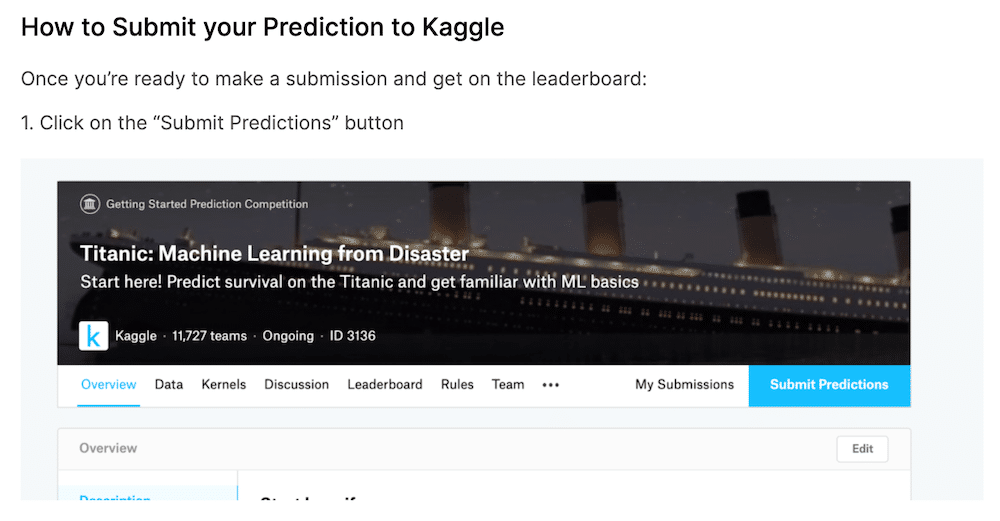
CSVファイルをパソコン(?)に上矢印のアイコンのところからファイルをアップロードします。
(1日に10回まで提出できます)
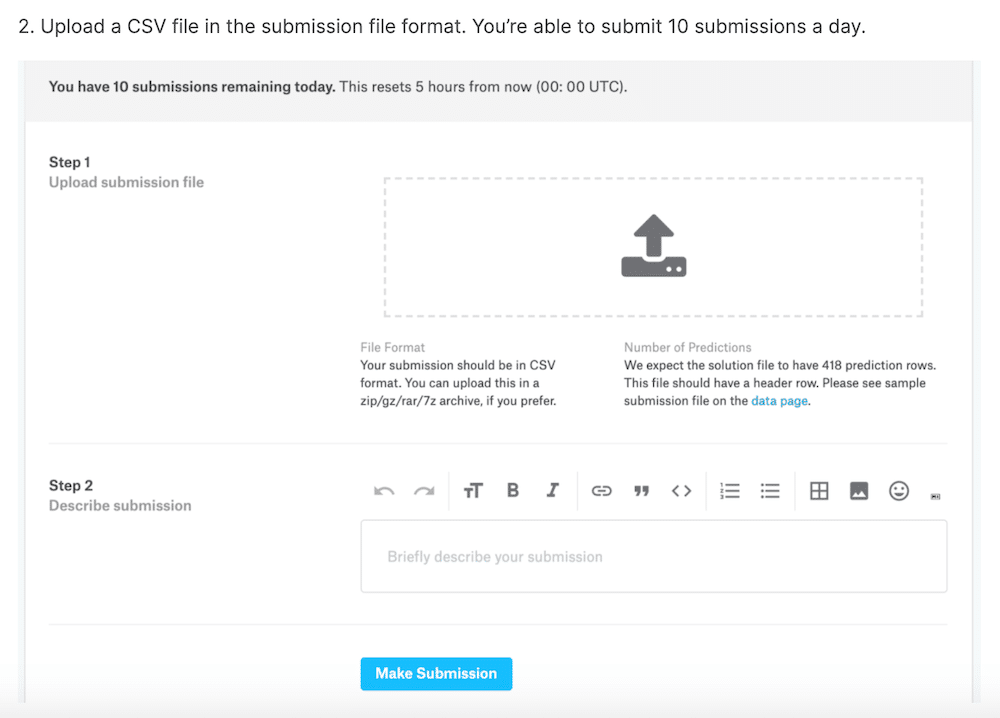
ファイルフォーマットの解説です。

「Passengerid(乗客ID)」と「Survived(生存か否か)」の2つの列のみで、418名の乗客データが含まれるファイルのみ提出できるとのことです。
「Got it! I’m ready to get started. Where do I get help if I need it?」ではもし誰かの助けが必要な時どうしたらいいか書かれています。
「A Last Word on Kaggle Notebooks」では自分のPCに機械学習の環境を構築しなくても、Kaggleの自分のアカウント内にJupyter Notebookの環境が準備されていますよ、使ってくださいね、と書かれています。

個人的にはAnacondaをインストールしてあるので、そちらでやる方が慣れていますが、そのうちにKaggleのnotebookも使ってみて、解説できたらなと思っています。
Evaluation:評価
次はEvaluation、評価方法に関してです。
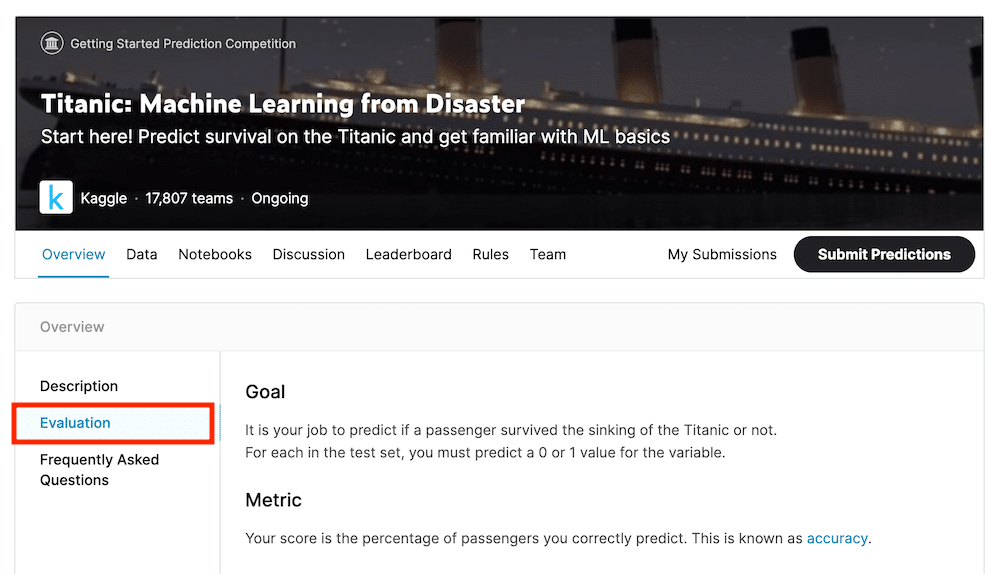
「Goal」には最終的にすべきことがかかれています。
今回の場合はそれぞれの乗客が生き延びたのか、それとも亡くなったのかを0か1で予想します。
「Metric」はスコアの算出方法です。
今回は正答率を%で算出し、それがスコアになるようです。

「Submission File Format」には提出するファイルフォーマットに関して書かれています。

例がある分、先ほどよりは分かりやすいですね。
Frequently Asked Questions:よく寄せられる質問
ここはその名の通りよく寄せられる質問とその答えが記載されています。

そこまで重要ではないと思うので、とりあえず解説は割愛します。
興味があれば覗いてみてください。
Data:データ
次は「Data」のタブです。
こちらではデータの詳しい説明を見ることができます。
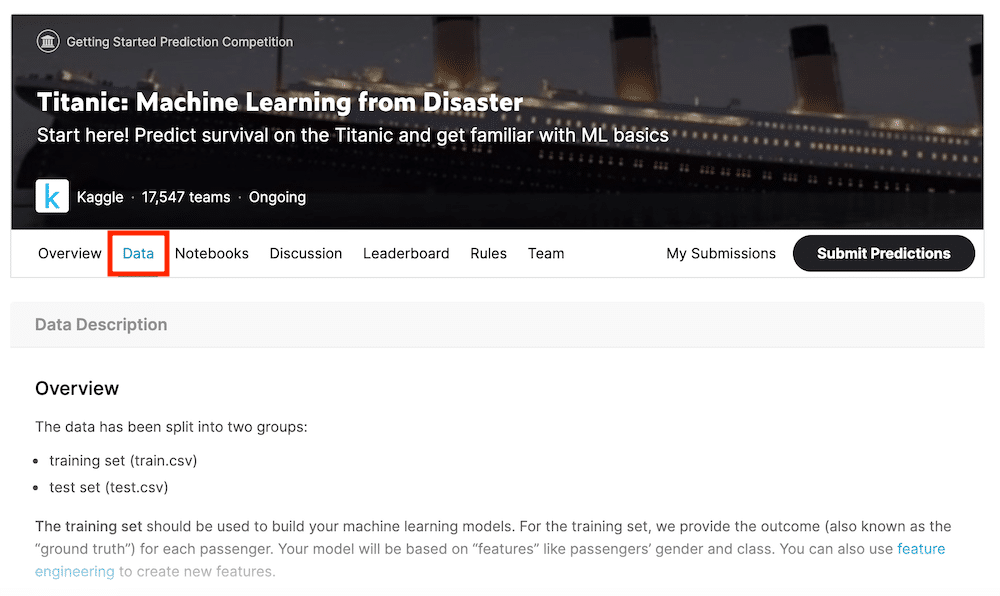
「Overview」ではデータの概要が示されています。
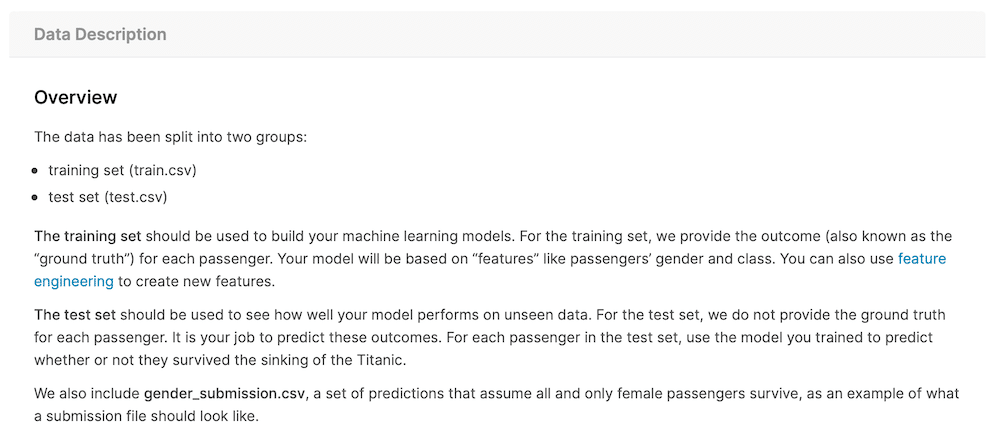
今回は「training set (train.csv)」と「test set (test.csv)」、つまり訓練用のデータセットと実際に予想するためのデータセットが含まれています。
「Data Dictionary」では特徴量とその簡単な解説、また値の意味が記されています。
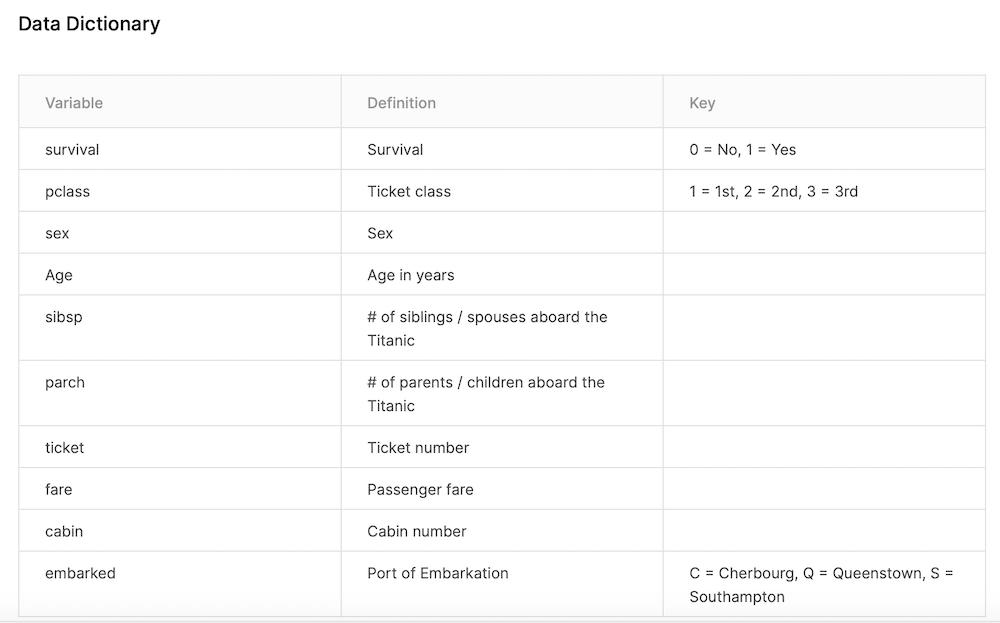
特徴量に関しては、実際に機械学習する時に見ていきましょう。
「Variable Notes」は変数の補助情報で、先ほどの特徴量に関する補足情報のようです。

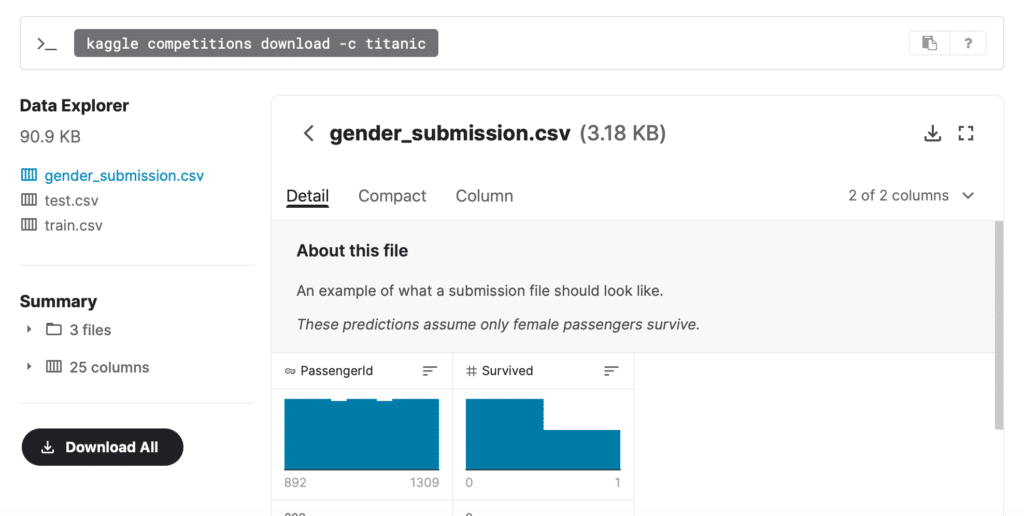
最後は「Data Explorer」で、こちらでデータの統計を少し見たり、データをダウンロードしたりできるようです。
Notebooks:ノートブック
「Notebooks」では他の参加者の機械学習モデルを見ることができます。
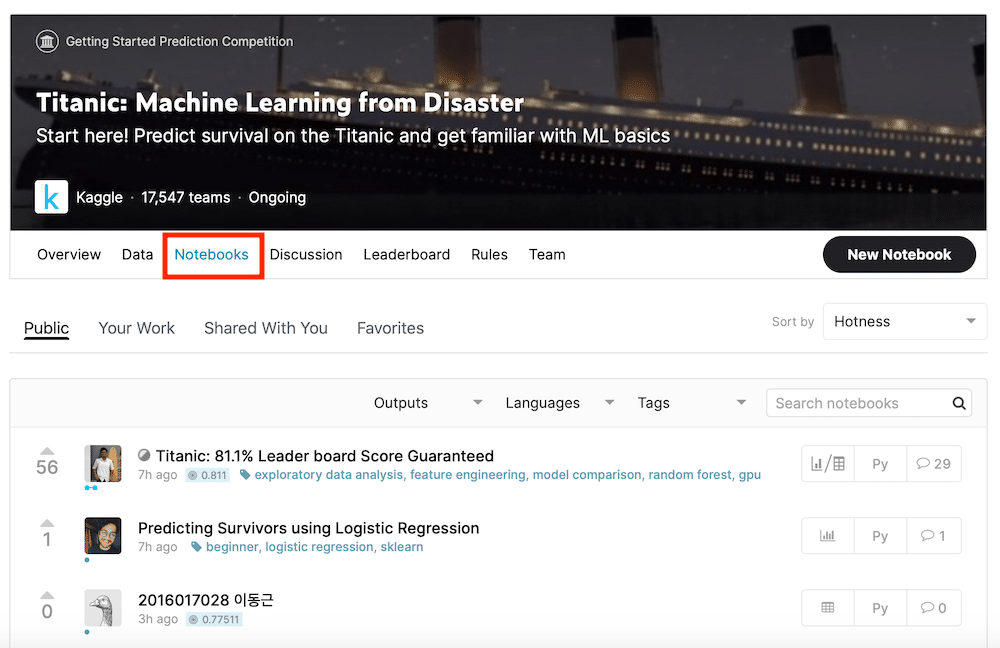
自分でがんばってみてもなかなか糸口がつかめない時や他の人がどんな方法でモデルを構築しているのか勉強したいときなんかに見るといいかもですね。
Discussion:ディスカッション
「Discussion」、日本語にすると「討論」です。

ここは参加者が「こうしたらいいんじゃないか?」「いやいやこうした方がもっとスコアがよくなるんじゃないか?」と議論を重ねる場所です。
困ったり、疑問が浮かんだりしたら、ここで聞いてみるのもいいかもしれません。
ただし英語ですが。
Leaderboard:スコアボード
「Leaderboard」は日本語にすると「スコアボード」です。
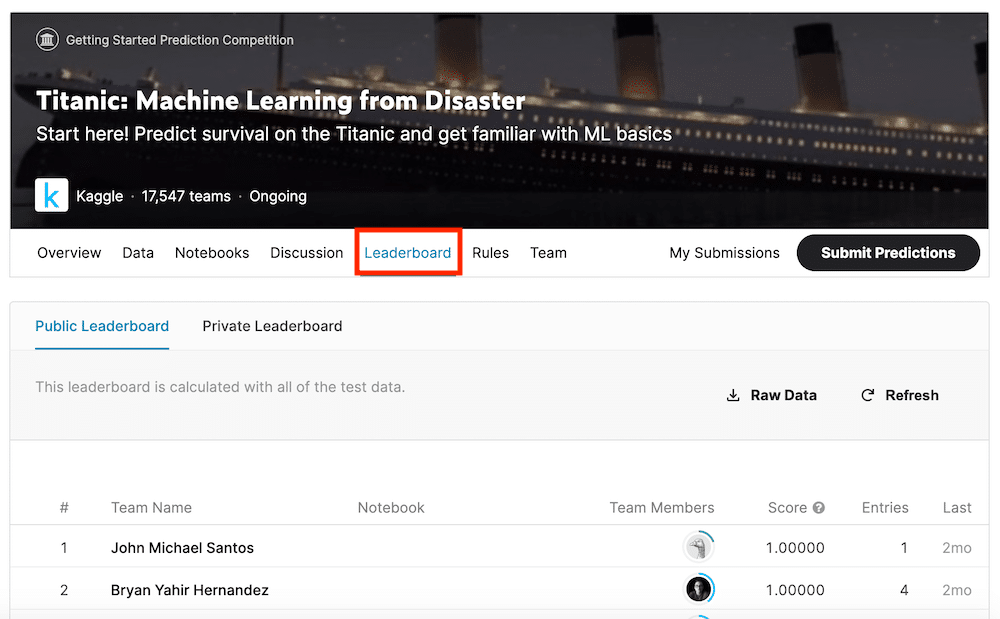
自分が機械学習で予想した結果をアップロードするとここにスコアと共に順位が載ります。
少しでもスコアが良くなるよう、そして少しでも順位が上がるよう頑張りたいものですね。
Rule:ルール
「Rule」はこのコンペティションに参加するためのルールが書かれています。
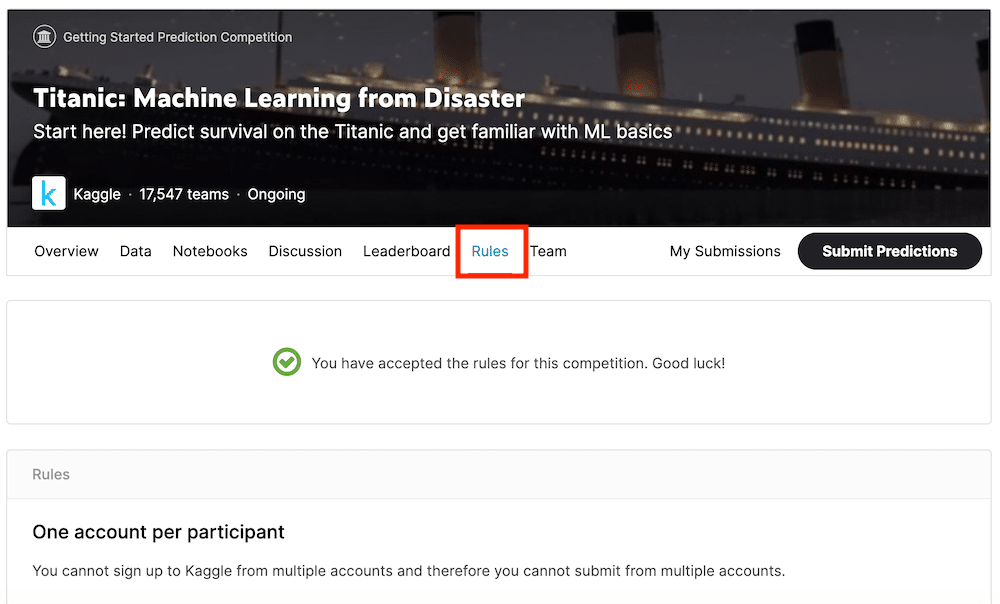
私はこの「タイタニック号乗客の生存予測」のコンペティションに参加しているので、「You have accepted the rule for this competition. Good luck!(このコンペティションのルールに同意しているよ!がんばって!)」と表示されています。
まだ同意していない場合は、こんな感じのものが表示されます。

「By clicking on the “I understand and accept” button, you indicate that you agree to be bound with the rules outlined below. (“理解して、同意します”のボタンをクリックすることによって、下に記されたルールに同意したことになります)」と書かれています。
コンペティションなので、不正はダメなわけです。
中には賞金がかかっているコンペティションもありますしね。
ということでルールを見ていきましょう。
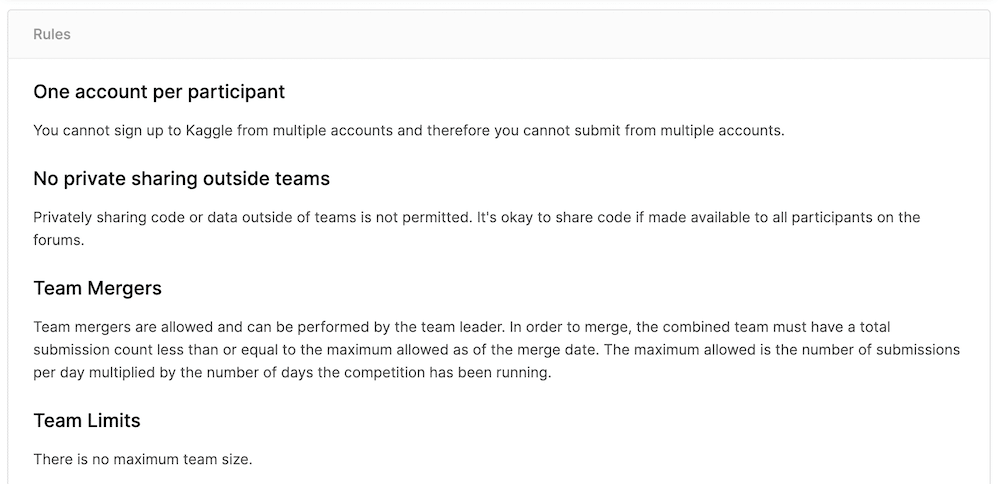
One account per participant:参加者一人には1アカウント
Kaggleでは複数のアカウントで参加することはできません。つまり複数のアカウントからデータを提出してはいけません。
No private sharing outside teams:チーム以外での非公開の場所でのデータの共有の禁止
Kaggleではチームを組めるのでそのチーム内での非公開のデータ共有は大丈夫ですが、チーム外の人と非公開のデータ共有は禁止です。
ただし、フォーラムの参加者全員がアクセスできるのであればデータの共有はOK。
Team Mergers:チームの統合
チームの統合は許可されていて、リーダーが行うことができます。統合後のチームではデータの提出回数は統合時の時点で許可されている最大値以下の数になります。
許可される最大数は、1日あたりの提出数に、コンテストが実行されている日数を掛けたもの。
Team limit:チームの人数の制限
チームの人数に制限はなし。

Submittion Limit:データ提出の制限
1日に10回データを投稿できます。
最後の5つの提出データを審査に回すことができます。
Competition Timeline:コンペティションのタイムスケジュール
開始日時:2012年9月28日 9:13
チーム統合の締め切り:なし
参加の締め切り:なし
終了日時:なし
このコンペティションは機械学習を始める人が楽しむためのものです。
タイタニックのデータセットはインターネット上に公開されていますが、答えを調べてしまうとこのデータセットの意味が無くなるので、そういうことはしないでください。
ということでルールを読んでみました。
もちろんコンペティションによってルールが違うこともあると思うので、しっかり確認して進めていきましょう。
今回気になるのは、”No private sharing”ということで、このサイトで解説をしていっていいのかということですね。
このサイトは非公開でなく、全世界に公開しているので、”Private sharing”になならないと思いますが、念のためKaggleの「Notebooks」上でもコードを公開していくことにしましょう。
Team:チーム
「Team」では他の参加者と一緒にコンペティションに取り組むことができるようになります。
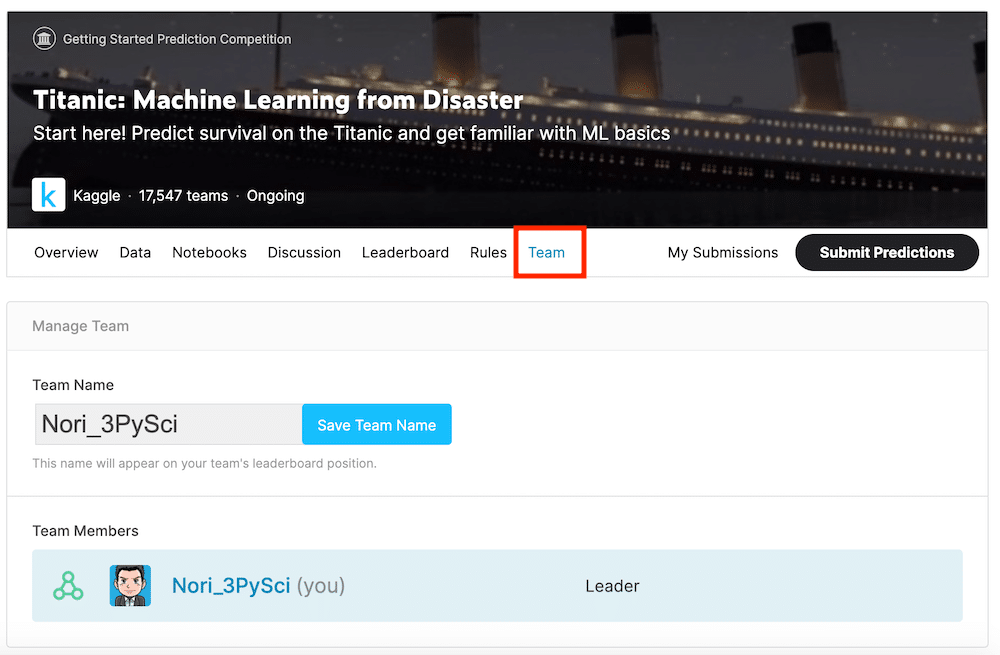
このチーム内の参加者だけであれば、非公開の情報のやり取りをしてもいいということですね。
My Submissions:自分の提出データ
「My submissions」では過去の自分の提出データを見ることができます。
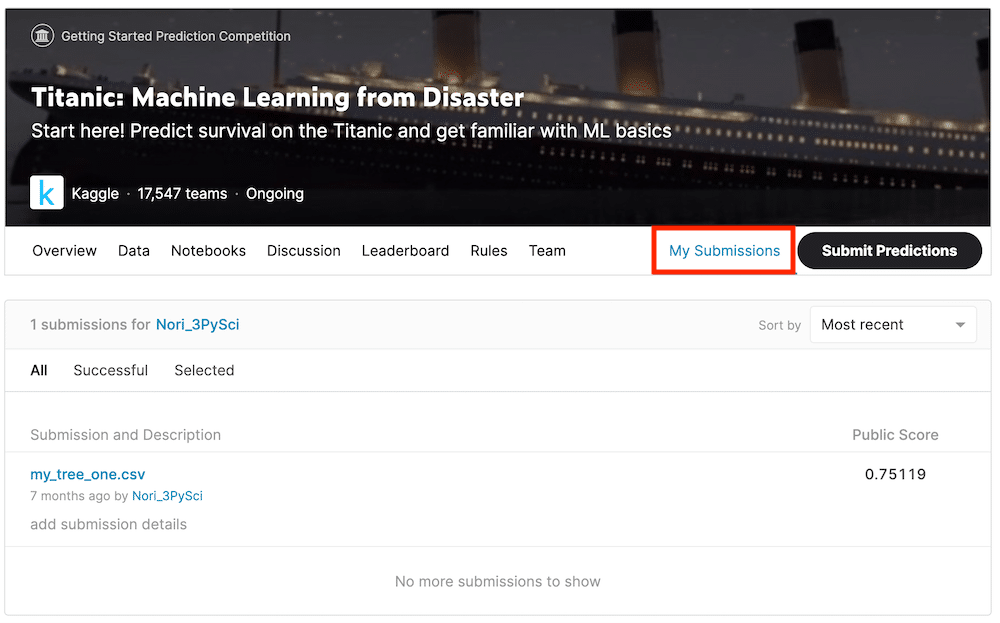
私も一度データを提出しているので、すでにスコアが見えています。
今後はこれを上回るようにモデルを改善していくということですね。
Submit Predictions:予想データの提出
「Submit predictions」は予想データを提出するボタンです。
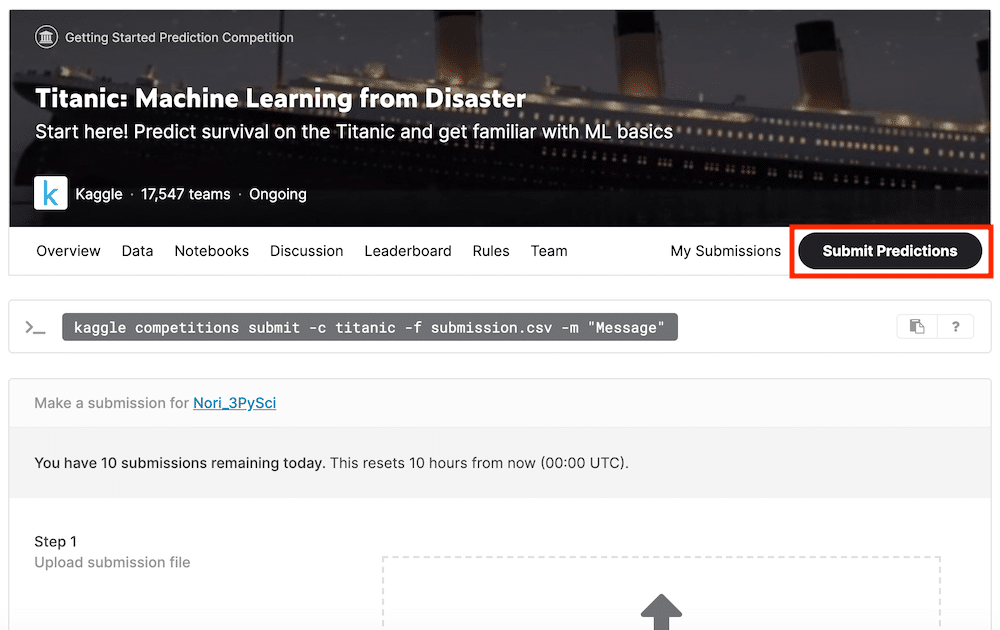
自分が満足するデータができたら、こちらからデータを提出してみましょう。
なかなか大変でしたが、これで全容が把握できたかと思います。
次回はこのタイタニック号のデータセットを読み込んで、中身を確認していきましょう。
ということで今回はこんな感じで。
コメント