Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」のデータセットのFareの欠損値を修正するための情報を集めてみました。
前回色々と情報は集めてみたものの、まだまだ納得できる値は見つかっていません。
ということで今回も引き続き、Fareの欠損値の修正を検討していきましょう。
細かいところは前回の記事を読んでいただくことにして、とりあえず前回のデータの形まで一気に進めます。
まずはデータを読み込んで、”Sex(性別)”の値を修正、訓練用データセットとテスト用データセットを連結した「all_data」というデータフレームを作ります。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
all_data = pd.concat([train.drop(columns = "Survived"), test])
all_data
実行結果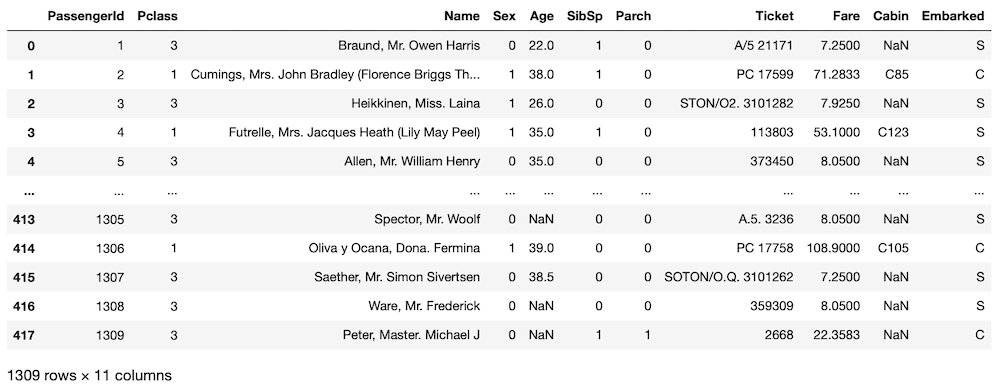
次に”Fare(料金)”が欠損している人のデータを表示しつつ、その人のデータに近い人のデータを絞り込んでいきます。
<セル2>
print(test[test["Fare"].isnull()])
fare_nan = all_data[all_data["Pclass"] == 3]
fare_nan = fare_nan[fare_nan["Embarked"] == "S"]
fare_nan = fare_nan[(fare_nan["SibSp"] == 0) & (fare_nan["Parch"] == 0)]
fare_nan
実行結果
PassengerId Pclass Name Sex Age SibSp Parch Ticket \
152 1044 3 Storey, Mr. Thomas 0 60.5 0 0 3701
Fare Cabin Embarked
152 NaN NaN S 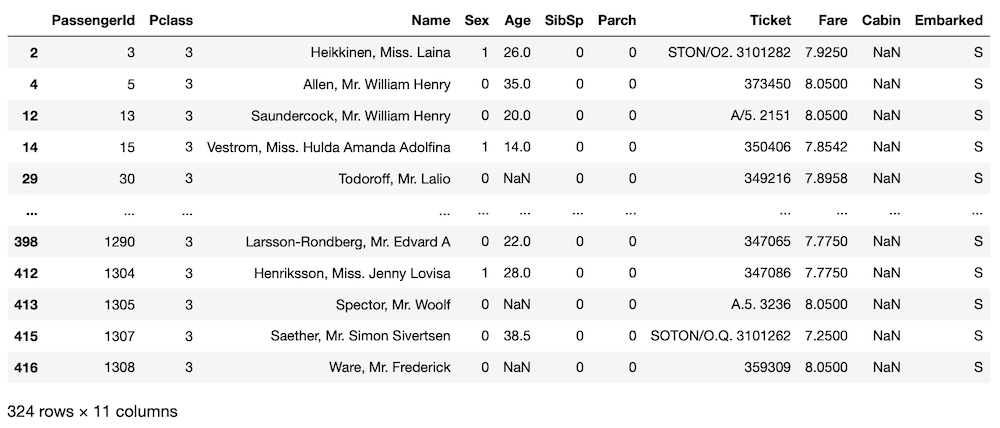
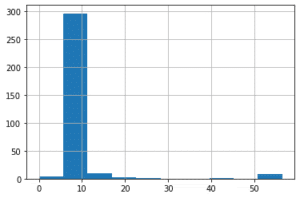
最後に現在絞り込まれている人が支払った料金のヒストグラムを表示しておきましょう。
<セル3>
fare_nan["Fare"].hist()
実行結果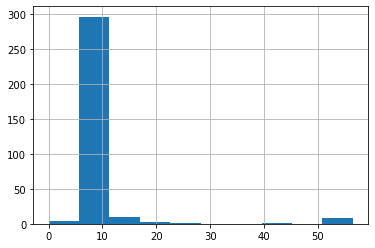
前回のプログラムをまとめてみるとこんな感じです。
これで大多数の人の料金が8ドル前後であることまでは分かったのですが、50ドルだったりする人もいて、まだまだ絞り込めていない感じがします。
ということで今回はここからさら情報を集めていきましょう。
データを修正するための情報収集
ここからは料金が欠損値になっている人のデータからではなく、同じ料金(または同じ程度の料金)を支払っている人に類似性がないか見ていきましょう。
とりあえず先ほど絞りこんだ人々からさらに30ドル以上の高額を支払った人を抽出してみます。
<セル4>
fare_temp = fare_nan[fare_nan["Fare"] >= 30]
fare_temp
実行結果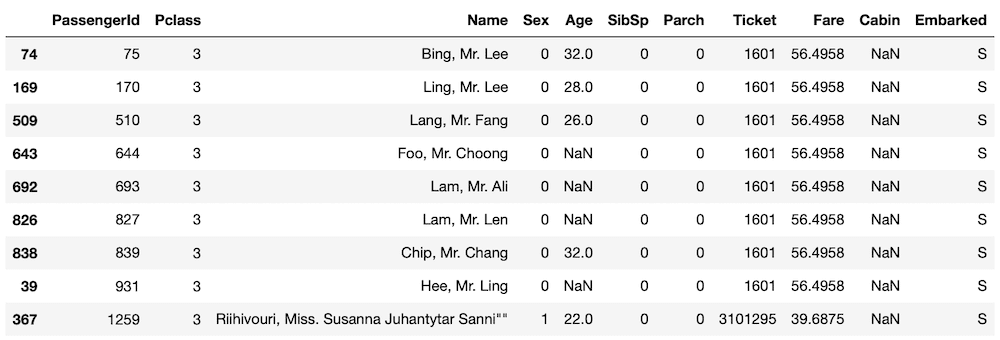
ここで気づくことが一つ。
56.4958ドル支払った人の”Ticket(チケット番号)”が「1601」と同じになっています。
似通った名前が多いですが、それでも名前は違いますし、年齢も少しずつ違うことからみると、同一人物が何かの原因で間違って重複しているということではなさそうです。
つまり同じチケット番号なら、同じ料金であると言えそうです。
ということで同じチケット番号をもつ人がいるのか確認してみましょう。
<セル5>
print(all_data[all_data["Ticket"] == "3701"])
実行結果
PassengerId Pclass Name Sex Age SibSp Parch Ticket \
152 1044 3 Storey, Mr. Thomas 0 60.5 0 0 3701
Fare Cabin Embarked
152 NaN NaN S 残念ながら同じチケット番号をもつ人は見つかりませんでした。
それでは近い番号のチケットをもつ人は同じような料金なのでしょうか?
10ドル以上30ドル未満を支払った人を見てみましょう。
<セル6>
fare_temp = fare_nan[(fare_nan["Fare"] >= 10) & (fare_nan["Fare"] < 30)]
fare_temp.sort_values("Fare", ascending=False)
実行結果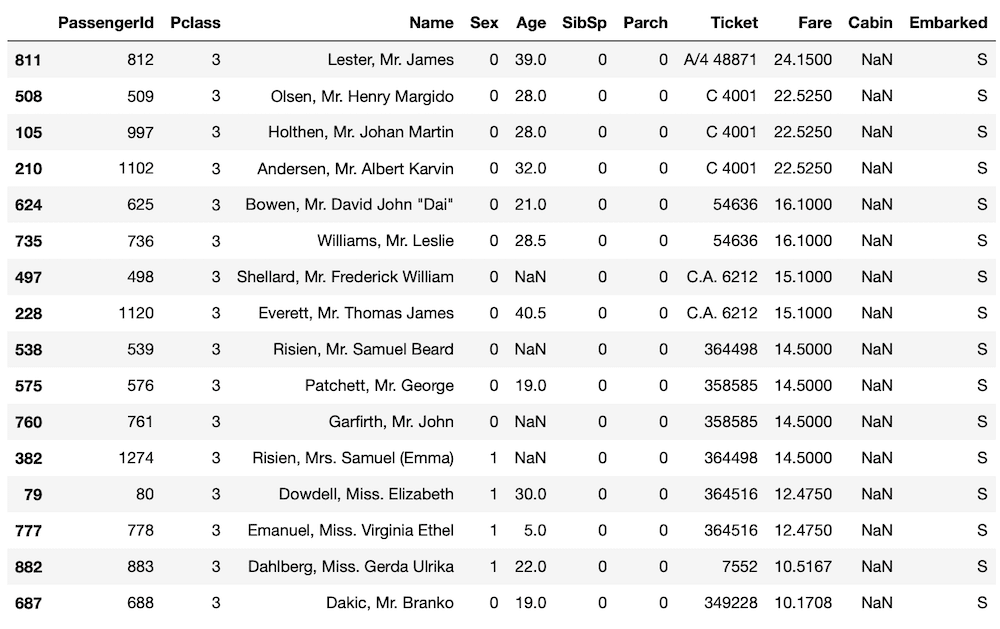
次に9.5ドル以上10ドル未満支払った人を見てみましょう。
<セル7>
fare_temp = fare_nan[(fare_nan["Fare"] >= 9.5) & (fare_nan["Fare"] < 10)]
fare_temp.sort_values("Fare", ascending=False)
実行結果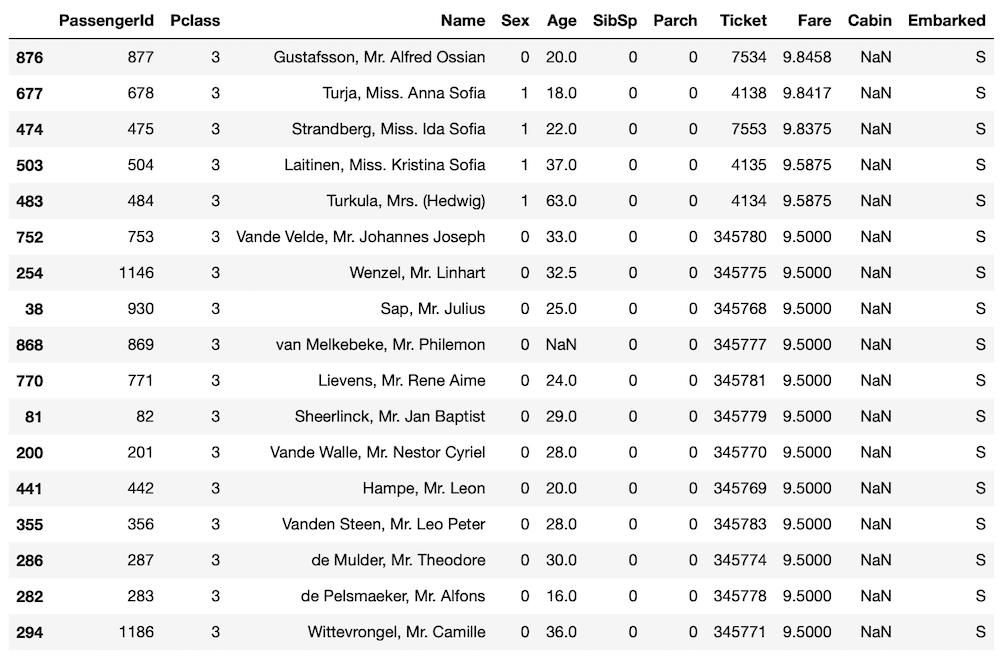
何となくチケット番号が近いと同じような料金を支払っているように見えます。
ただしチケット番号がそのまま料金に直結するかというとそうではなく、番号が小さい、大きいが料金が高い安いとは関係なさそうです。
とりあえず乗客No.1044の人のチケット番号は3701なので3000番台の人がいくら支払ったか見てみましょう。
チケット番号3000番台の人を抽出してみる
ということでチケット番号が3000番台の人を抽出するプログラムを作ってみました。
def int_check(number):
try:
int(number)
except:
return False
return True
ticket_list = []
for number in fare_nan["Ticket"]:
if int_check(number) == True:
if int(number) >=3000 and int(number) < 4000:
ticket_list.append(number)
for number in ticket_list:
print(fare_nan[fare_nan["Ticket"] == str(number)])上から解説していきましょう。
まずはこちらの部分から。
def int_check(number):
try:
int(number)
except:
return False
return Trueここでは新しい関数として、int型(整数)かどうか確認する関数を定義しています。
その理由としては、チケット番号にたまに文字が入っているため、全てstr型(文字列)となっており、番号で抽出できなかったので、文字が入っているチケットはとりあえず無視するためです。
try、exceptを使うのは例外処理という方法ですが、こちらの記事で解説していますので、良かったらご覧ください。

int_check(number)でnumberに入ったものがint型に変更可能なら「True」、変更不可能なら「False」を返します。
この関数を使って、Ticketの値がint型に変更可能なもののうち、3000以上、かつ4000未満のものをリストticket_listにに格納している部分がこちらです。
ticket_list = []
for number in fare_nan["Ticket"]:
if int_check(number) == True:
if int(number) >=3000 and int(number) < 4000:
ticket_list.append(number)最後にリストticket_listに格納したチケット番号をもつデータを表示させる部分がこちらです。
for number in ticket_list:
print(fare_nan[fare_nan["Ticket"] == str(number)])これを実行してみました。
<セル8>
def int_check(number):
try:
int(number)
except:
return False
return True
ticket_list = []
for number in fare_nan["Ticket"]:
if int_check(number) == True:
if int(number) >=3000 and int(number) < 4000:
ticket_list.append(number)
for number in ticket_list:
print(fare_nan[fare_nan["Ticket"] == str(number)])
実行結果
PassengerId Pclass Name Sex Age SibSp Parch \
810 811 3 Alexander, Mr. William 0 26.0 0 0
Ticket Fare Cabin Embarked
810 3474 7.8875 NaN S
PassengerId Pclass Name Sex Age SibSp \
108 1000 3 Willer, Mr. Aaron (Abi Weller")" 0 NaN 0
Parch Ticket Fare Cabin Embarked
108 0 3410 8.7125 NaN S
PassengerId Pclass Name Sex Age SibSp Parch Ticket \
152 1044 3 Storey, Mr. Thomas 0 60.5 0 0 3701
Fare Cabin Embarked
152 NaN NaN S
PassengerId Pclass Name Sex Age SibSp Parch Ticket \
243 1135 3 Hyman, Mr. Abraham 0 NaN 0 0 3470
Fare Cabin Embarked
243 7.8875 NaN S 3番目の乗客No.1044は今、料金を知りたい人なので、これ以外を見ていきましょう。
最初の乗客No.811はチケット番号3474で料金は7.8875ドル。
2番目の乗客No.1000はチケット番号3410で料金は8.7125ドル。
最後の乗客No.1135はチケット番号3470で料金は7.8875ドル。
やはり料金は8ドル前後で問題なさそうです。
あとは7.8875ドルにするのか、8.7125ドルにするのか、はたまた違う値にするのかですが、あまり違いがなさそうなので、今回は7.8875ドルにしてみましょう。
ということで何とか修正値が決まりました。
次回は値を修正して、機械学習を行い、データを予想・提出して、新しいスコアを取得してみましょう。
ではでは今回はこんな感じで。
コメント