Kaggle
前回は機械学習・データサイエンスのプラットフォーム「Kaggle(カグル)」の「タイタニック号乗客の生存予測」の生存予想データを提出し、スコアを取得してみました。
ここからはさらに良いスコアが取れるよう、モデルを改善していく段階になります。
モデル改善の第一歩として、まずはデータ中の欠損値を妥当な値に修正していきましょう。
ということで欠損値がどの特徴量に含まれるのか確認していきます。
まずはデータの読み込みから。
今回は訓練用のデータセット(train.csv)とテスト用のデータセット(test.csv)を最初に読み込んでしまいましょう。
<セル1>
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
実行結果実行しても特に何も起こりません。
ということで次の二つのセルでそれぞれを表示してみます。
<セル2>
train
実行結果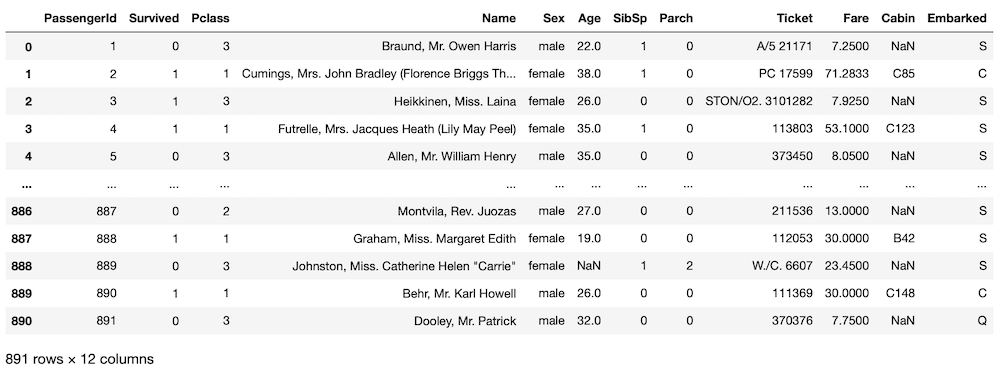
<セル3>
test
実行結果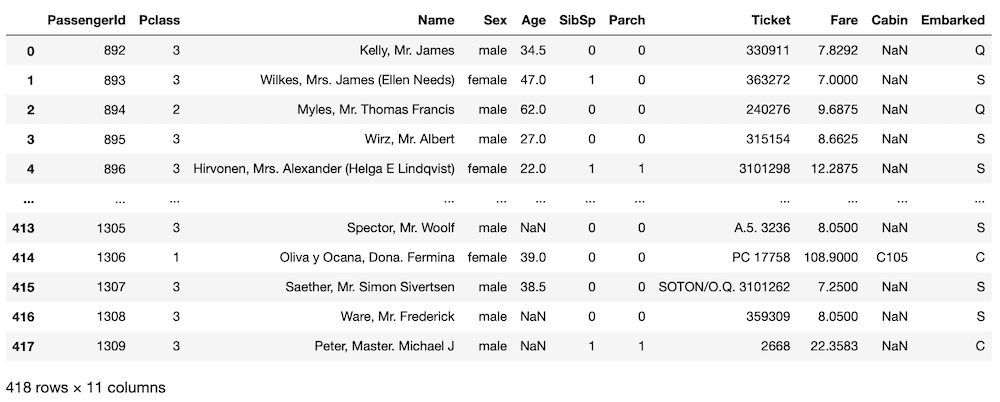
そして前回に文字から数字に変更したように今回も「Sex」を変更しておきます。
<セル4>
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
実行結果<セル5>
train
実行結果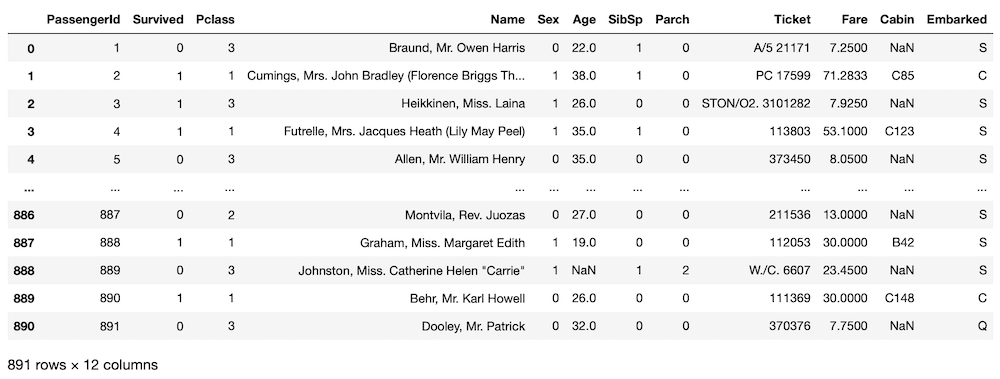
<セル6>
test
実行結果
次にどの特徴量に欠損値があるか確認しておきましょう。
<セル7>
train.isnull().sum()
実行結果
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64<セル8>
test.isnull().sum()
実行結果
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64欠損値がある中で欠損値の個数が少ない順で見ると、Fare、Embarked、Age、Cabinとなります。
Cabinに関しては、訓練用データセットの891個のデータ中、687個が欠損値、そしてテスト用データセットの418個のデータ中、327個が欠損値となっています。
Cabinはちょっと修正するのは難しそうなので、Fare、Embarked、Ageの三つを修正していきます。
今回はその中でも一番欠損値の個数が少ない「Fare」を修正していきましょう。
データを修正するための情報収集
まずはどう修正するか考えるために、情報収集を行いましょう。
今回、Fareのデータの中で欠損値を含むデータの詳細を確認しましょう。
<セル9>
print(test[test["Fare"].isnull()])
実行結果
PassengerId Pclass Name Sex Age SibSp Parch Ticket \
152 1044 3 Storey, Mr. Thomas 0 60.5 0 0 3701
Fare Cabin Embarked
152 NaN NaN S Fareは料金なので、この人のデータと類似するデータの人であれば、同じような料金になっていると推測されます。
ということでデータを探索していきますが、探索するデータは広い方がいいので、訓練用データセットとテスト用データセットを結合し、探索用データセットを作ります。
ただし訓練用データセットにある「Survived」のデータはテスト用データセットには含まれませんので、「Survived」を抜いたデータをテスト用データセットに連結します。
<セル10>
all_data = pd.concat([train.drop(columns = "Survived"), test])
all_data
実行結果
訓練用データ891個+テスト用データ418個=1309個のデータとなり、ちゃんと連結できました。
Pandasのデータフレームの連結の方法はこちらの記事で解説していますので、良かったらこちらもご覧ください。
また列や行を削除する方法はまだ解説していませんので、今後どこかの機会で解説したいと思います。
ここから類似したデータを探すため、条件を絞っていきます。
料金に直結しそうなデータとしては客室のグレード、つまり「Pclass」が大きく影響することが考えられます。
先ほどのFareが欠損したデータの人(以降、乗客No.1044と呼びます)はPclassが「3」となっているので、Pclassが「3」のデータのみに絞ります。
<セル11>
fare_nan = all_data[all_data["Pclass"] == 3]
fare_nan
実行結果
1309個のデータから709個のデータへと絞り込めましたが、それでもまだまだデータ数が多いです。
ということで次は乗船地により料金が変わるだろうと踏んで、「Embarked」を乗客No.1044の「S」に絞ります。
<セル12>
fare_nan = fare_nan[fare_nan["Embarked"] == "S"]
fare_nan
実行結果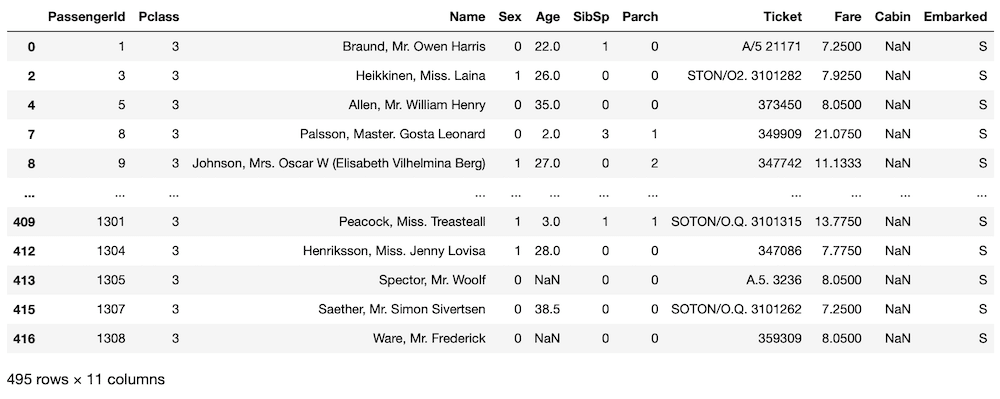
495個のデータまで絞り込めましたが、まだまだ多く、決定打となるデータにはたどり着けていません。
あと絞り込みに使えそうなデータは「SibSp(兄弟姉妹の数)」、「Parch(親子供の数)」くらいでしょうか。
乗客No.1044はどちらも「0」なので、一応絞り込んでみましょう。
<セル13>
fare_nan = fare_nan[(fare_nan["SibSp"] == 0) & (fare_nan["Parch"] == 0)]
fare_nan
実行結果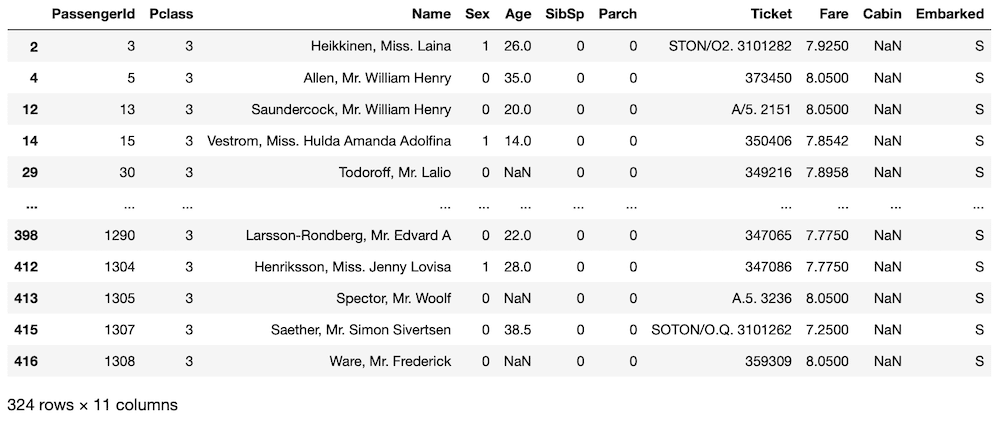
324個のデータまで絞り込めました。
しかしまだまだデータ数は多いです。
今データとして見えている分だけで推察すると、今絞り込んだ人たちのFare(料金)は7ドル後半から8ドル前半のようです。
もし他の人も同じような料金であれば、8ドルとしてしまっても大きなズレは生じなさそうです。
ということでここで一旦、料金の分布を見てみることにしましょう。
ヒストグラムを表示する方法はこちらの記事で解説していますので、良かったらこちらもご覧ください。
<セル14>
fare_nan["Fare"].hist()
実行結果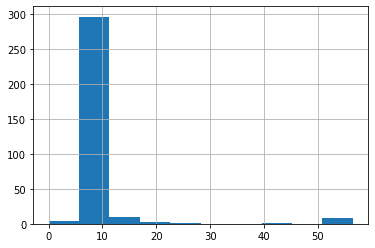
10ドルよりも低いところに集まっているのが分かります。
ここをもう少し細かく見てみましょう。
<セル15>
fare_nan["Fare"].hist(range=(0, 15))
実行結果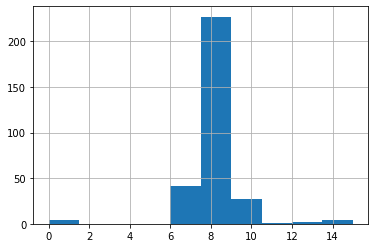
やはり8ドルのところに集中していることが分かります。
確率論から言うと、8ドルにしてしまってもそうそうずれることはないように感じます。
しかし一方で同じ条件でデータを絞った中に50ドルを超える料金を支払っている人も含まれています。
そう言う意味ではまだまだ納得できていません。
なかなか考えも煮詰まってきたので、今回はここまでとして、次回さらに他に何かできないか考えてみましょう。
ということで今回はこんな感じで。
コメント