ランダムデータのファイルが欲しい!
前にjunney様より「グラフタイトルをファイル名としたい」というご質問を頂き、答えてみました。
ただどうやら他にもプログラムが動いていない部分があるようで、再度ご質問を頂きました。
抜粋してみるとこんな感じ。
今、6列4000行のcsvファイルをファイル毎にグラフ化しています。
pandasを使っているのですが、途中データの格納のあたりがわかってなく、
結果はグラフが1個しかできずで、、、
https://3pysci.com/python-matplotlib-25/
前回はとりあえずグラフタイトルをファイル名とするだけだったので、手打ちで簡単なデータを作ってみましたが、流石に6列4000行のデータを手打ちするのはしんどい。
そうでなくてもこれから色々データの解析方法やグラフ化を解析していくのに、簡単にデータを作成するプログラムを作っておけば、後々楽なんじゃないかと。
ということでランダムなデータファイルを作るプログラムを作ってみたので、解説していきます。
インポートとセッティング部
まずは必要なモジュールをインポートしていきます。
今回はcsvとrandomを使いますが、これらはAnacondaでは(多分Pythonの標準モジュール)最初からインストールされていますので、そのままインポートできます。
import csv
import random続いて次のセルにセッティング部を書いていきます。
セッティング部は、ここにある変数やリストの中身を書き換えることで、簡単に出力を変えることを変えることを目的としています。
まずは出力ファイル名、またそれぞれのデータ名、ヘッダー用の変数を準備します。
file_name_head = "testdata_"
file_name_end = ""
file_ext = ".txt"
data_name_head = "data_"
data_name_end = ""
value_name_head = "value_"
value_name_end = ""
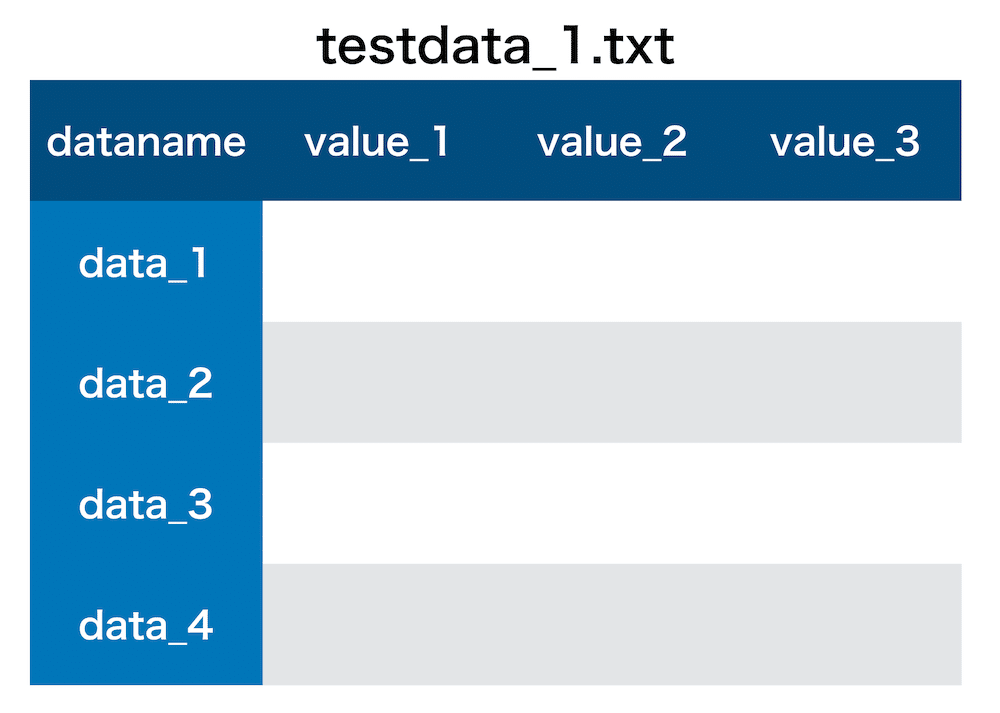
index_name = "dataname"ここで想定しているのは、
ファイル名は「file_name_head + 数字 + file_name_end + file_ext」、つまり上の例だと「testdata_X.txt」
データ名が「data_name_head + 数字 + data_name_end」、つまり上の例だと「data_X」
ヘッダーが「index_name, value_name_head + 数字1 + value_name_end, value_name_head + 数字2 + value_name_end…」、つまり上の例だと「dataname, value_X1, value_X2, value_X3 …」
となります。
図で表してみるとこんな感じです。
次にファイル数、行数、列数、ランダム数値の範囲を決めていきます。
no_files = 10
rows = 10
columns = 6
random_range = [0, 99]no_filesでファイル数、rowsで行数(データ数)、columnsで列数、random_rangeでランダム数値の範囲を設定しました。
ということでセッティング部としてはこんな感じ。
file_name_head = "testdata_"
file_name_end = ""
file_ext = ".txt"
data_name_head = "data_"
data_name_end = ""
value_name_head = "value_"
value_name_end = ""
index_name = "dataname"
no_files = 10
rows = 10
columns = 6
random_range = [0, 99]メインプログラム部:ファイル作成
ここから処理するプログラムを書いていきます。
まずはファイル名を作成し、ファイルを開く部分です。
for no_file in range(no_files):
filename = file_name_head + str(no_file + 1) + file_name_end + file_ext
print(filename)
f = open(filename, "w")
writer = csv.writer(f)
f.close()「for no_file in range(no_files):」でファイル番号を一つずつ取り出します。
そして「filename = file_name_head + str(no_file + 1) + file_name_end + file_ext」でファイル名を作成します。
この際、str(no_file + 1)としているのは、range(no_files)で作った数値のリストは0から始まるので、それを1からに変えているということです。
「print(filename)」で確認のため出力しています。
そして次の3行で、ファイルを新規作成(同じファイル名がある場合は上書き)して開き、csvを出力できるようにして、ファイルを閉じています。
f = open(filename, "w")
writer = csv.writer(f)
f.close()この「writer = csv.writer(f)」と「f.close()」の間に処理するプログラムを書いていきます。
for no_file in range(no_files):
filename = file_name_head + str(no_file + 1) + file_name_end + file_ext
print(filename)
f = open(filename, "w")
writer = csv.writer(f)
f.close()
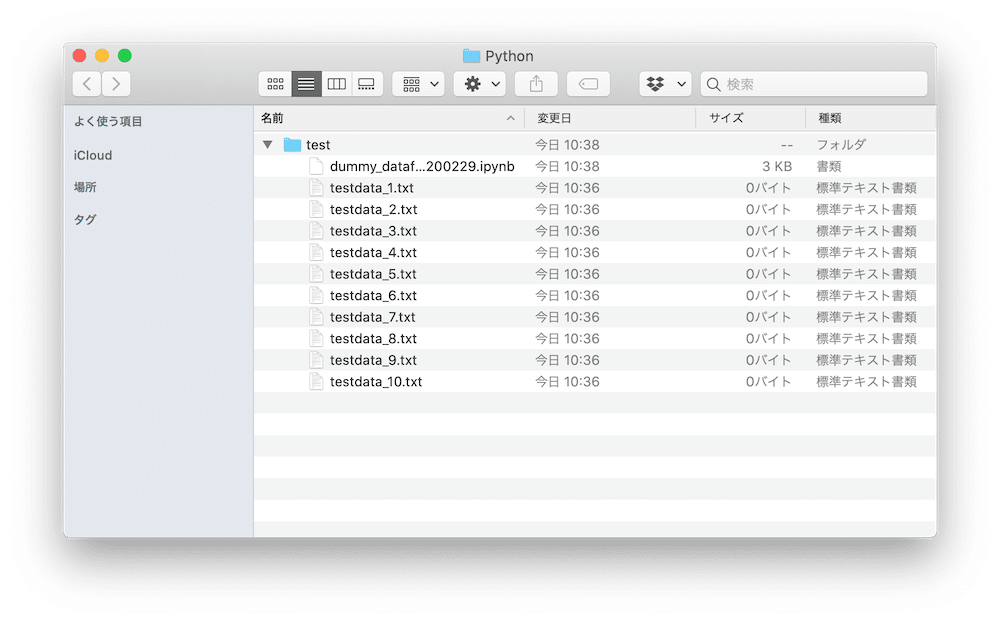
実行結果
testdata_1.txt
testdata_2.txt
testdata_3.txt
testdata_4.txt
testdata_5.txt
testdata_6.txt
testdata_7.txt
testdata_8.txt
testdata_9.txt
testdata_10.txt出力されたファイルはこちら。
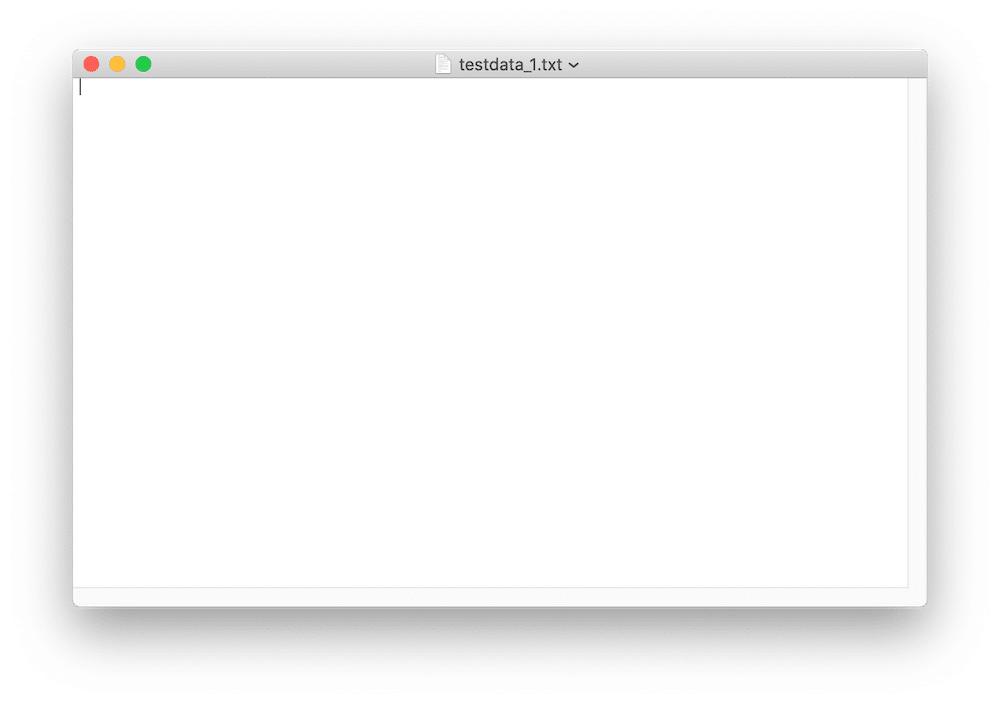
ただファイルの中身は何もありません。
「print(filename)」は確認用だったので、次からは「#」を行の先頭につけてコメントアウト(プログラムとしては読まれない部分)しておきます。
次に中身を書き出すプログラムを作成していきます。
メインプログラム部:ヘッダー出力
ヘッダー部分を書き出すプログラムを作っていきます。
header = [index_name]
for column in range(columns):
valuename = value_name_head + str(column + 1) + value_name_end
header.append(valuename)
writer.writerow(header)「header = [index_name]」でヘッダーのリストを作り出し、一列目は「変数index_name」を入力します。
「for column in range(columns):」で列の数をリスト化し、「valuename = value_name_head + str(column + 1) + value_name_end」でそれぞれの列のヘッダーを作成します。
作成した列のヘッダーを「header.append(valuename)」で変数headerに入れます。
全部の列のヘッダーを作成し、変数headerに入れ終わったら、「writer.writerow(header)」でファイルに書き出します。
ということでここまでで全体としてはこんな感じ。
for no_file in range(no_files):
filename = file_name_head + str(no_file + 1) + file_name_end + file_ext
# print(filename)
f = open(filename, "w")
writer = csv.writer(f)
header = [index_name]
for column in range(columns):
valuename = value_name_head + str(column + 1) + value_name_end
header.append(valuename)
writer.writerow(header)
f.close()
実行結果
ヘッダーが出力できました。
メインプログラム部:データ出力
次はデータ出力部分です。
for row in range(rows):
data = []
dataname = data_name_head + str(row + 1) + data_name_end
data.append(dataname)
for column in range(columns):
data.append(random.randint(random_range[0], random_range[1]))
writer.writerow(data)まず「row in range(rows):」でセッティング部で指定した行数を繰り返します。
そしてこの3行でデータ名を決めて、リストdataに入れていきます。
data = []
dataname = data_name_head + str(row + 1) + data_name_end
data.append(dataname)今度は「for column in range(columns):」でセッティング部で指定した列数を繰り返し、「data.append(random.randint(random_range[0], random_range[1]))」でランダムな数を取得して、リストdataに入れていきます。
ちなみに「random.randint()」はランダムな整数を取得する関数です。
「randomモジュール」に関してはまた今度詳しく解説してみたいと思います。
指定した列数だけランダムな数を取得して、リストdataに入れ終わったら、「writer.writerow(data)」でファイルに書き出します。
この「指定した列数だけランダムな数を取り出し、ファイルに書き出す」という動作を指定した列数だけ繰り返したら終わりというわけです。
全体を書いてみるとこんな感じです。
for no_file in range(no_files):
filename = file_name_head + str(no_file + 1) + file_name_end + file_ext
# print(filename)
f = open(filename, "w")
writer = csv.writer(f)
header = [index_name]
for column in range(columns):
valuename = value_name_head + str(column + 1) + value_name_end
header.append(valuename)
writer.writerow(header)
for row in range(rows):
data = []
dataname = data_name_head + str(row + 1) + data_name_end
data.append(dataname)
for column in range(columns):
data.append(random.randint(random_range[0], random_range[1]))
writer.writerow(data)
f.close()
print("Done")ちなみに最後に「print(“Done”)」を書いておくと、プログラムが終了したか分かりやすいです。
実行すると「Done」が表示され、ファイルができます。
ファイルの中身としてはこんな感じです。
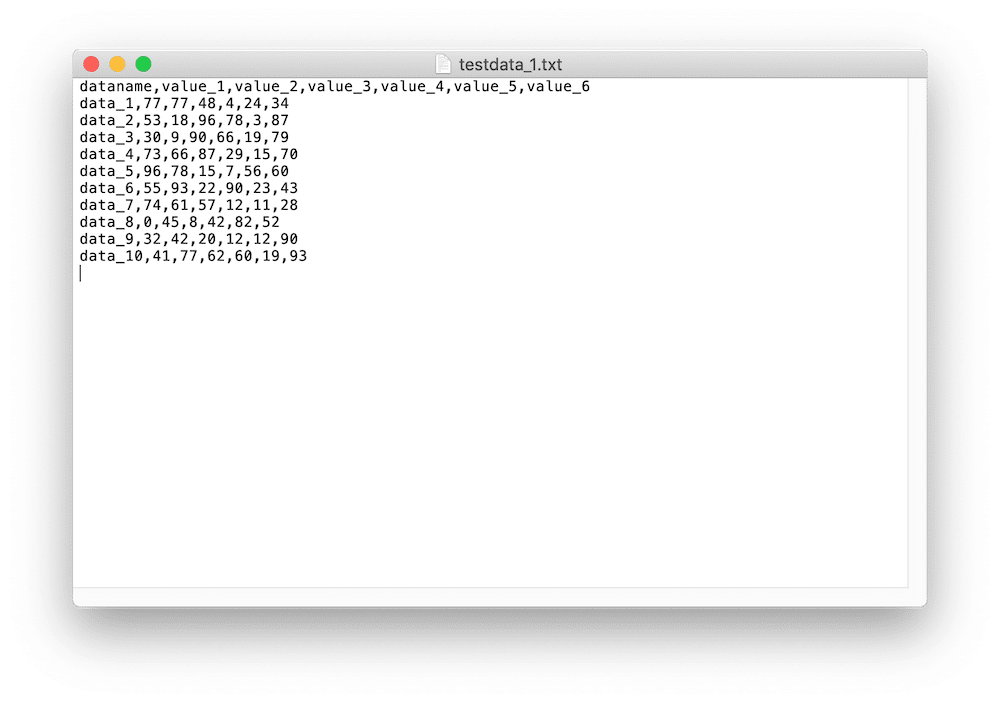
これで意図したデータファイルができました。
ただ今回はランダムな数だけなので、そのうちにもう少し整った数のリスト、つまり直線的に増減する数のリストだったり、指数関数的に増減する数のリストを出力できるようにしたいものです。
とりあえずはこの形で、Pandasを使ってグラフを作っていくというのをやってみたいと思います。
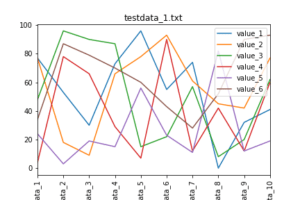
ではでは今回はこんな感じで。
コメント