データ解析支援ライブラリPandas
前回はデータ解析支援ライブラリPandasのconcatを使ってデータフレームを連結する方法を解説しました。
そこで生まれた疑問がconcatで連結した際、同じ行名、列名ができてしまった場合、その後、その行や列を呼び出し型はどうなるのか?ということです。
というのも行名や列名を取得することもあれば、行名や列名で呼び出したりすることもあるからです。
色々試してみる前に、とりあえず準備していきましょう。
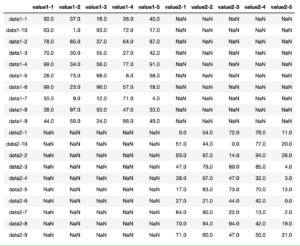
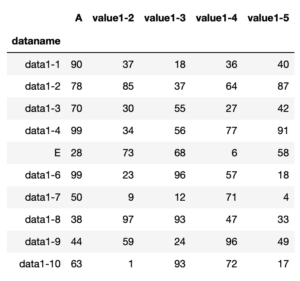
使用するデータは前回のデータの1番を使ってみます。
データの読み込み方はこんな感じ。
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df
実行結果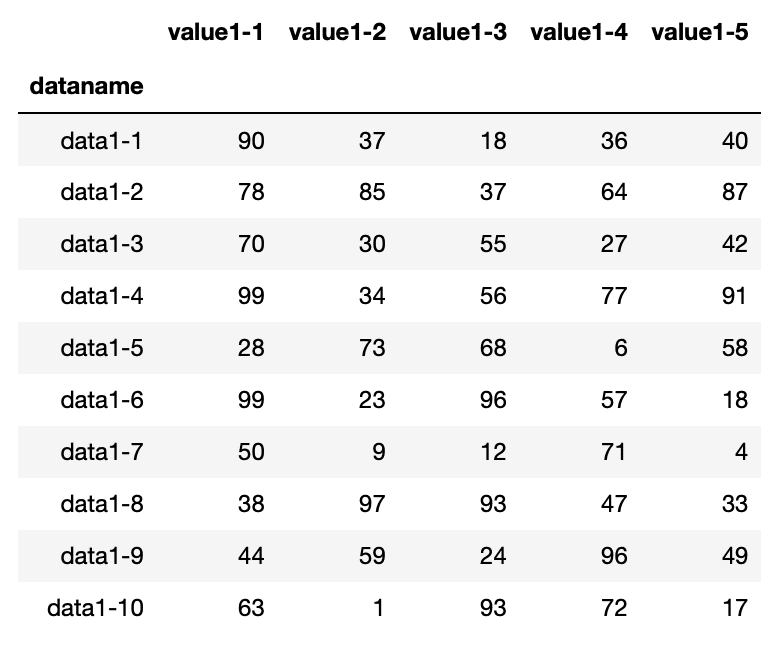
とりあえずは普通に呼び出す方法を復讐していきましょう。
復習:行名、列名を取得する index、columns
まずは行名、列名を取得する方法を復習していきます。
まずは行名を取得するには、indexを用います。
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
print(df.index)
実行結果
Index(['data1-1', 'data1-2', 'data1-3', 'data1-4', 'data1-5', 'data1-6',
'data1-7', 'data1-8', 'data1-9', 'data1-10'],
dtype='object', name='dataname')列名を取得するには、columnsを用います。
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
print(df.columns)
実行結果
Index(['value1-1', 'value1-2', 'value1-3', 'value1-4', 'value1-5'], dtype='object')これで行名、列名を取得する方法を思い出しました。
復習:行データ、列データを呼び出す方法
今回は行名、列名を使ってデータを呼び出したいので、まずはその方法を復習しましょう。
細かいことはこちらの記事をご覧ください。
列名を使ってデータを呼び出すには、データフレーム名[“列名”]です。
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
print(df["value1-1"])
実行結果
dataname
data1-1 90
data1-2 78
data1-3 70
data1-4 99
data1-5 28
data1-6 99
data1-7 50
data1-8 38
data1-9 44
data1-10 63
Name: value1-1, dtype: int64行名を使ってデータを呼び出すには、データフレーム.loc[“行名”]です。
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
print(df.loc["data1-1"])
実行結果
value1-1 90
value1-2 37
value1-3 18
value1-4 36
value1-5 40
Name: data1-1, dtype: int64これでデータを呼び出す方法も復讐できました。
ということでconcatでデータフレームを連結した際、同じ行名や列名が複数ある場合を試していきましょう。
復習:concatでデータフレームを連結
ということで次にconcatでデータフレームを連結し、同じ行名、同じ列名を複数回もつデータフレームを作成してみます。
まずは縦方向に同じデータフレーム「df」を連結し、新しいデータフレーム「df_y」を作成します。
連結するコマンドは「df_y = pd.concat([df, df], axis=0)」です
(間違いなく縦に連結するするため、axis=0を追加しています)
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df_y = pd.concat([df, df], axis=0)
df_y
実行結果
次に横方向に同じデータフレーム「df」を連結し、新しいデータフレーム「df_x」を追加します。
連結するコマンドは「df_x = pd.concat([df, df], axis=1)」です。
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df_y = pd.concat([df, df], axis=0)
df_x = pd.concat([df, df], axis=1)
df_x
実行結果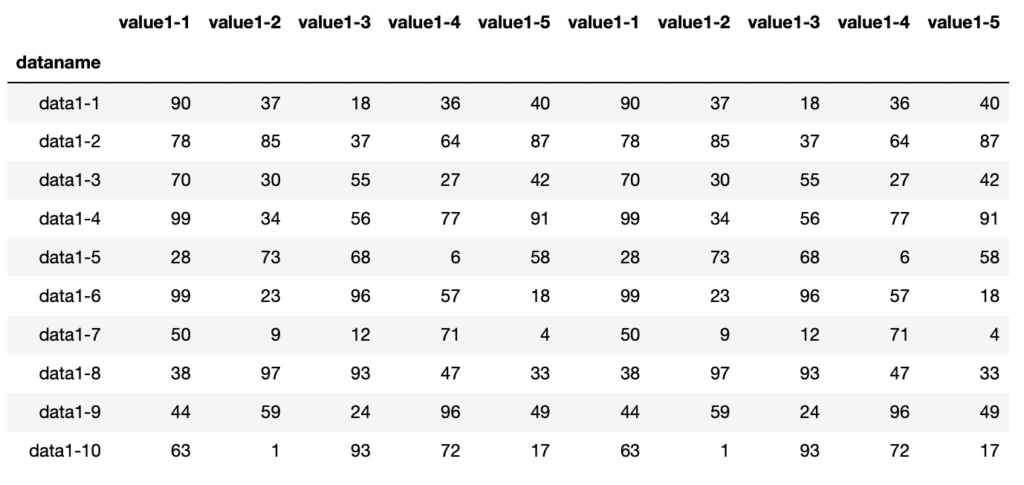
これで縦、または横に連結したデータフレーム「df_y」「df_x」が作成できました。
同じ列名、行名を複数回もつデータフレームで列名、行名を取得してみる
では同じ列名、同じ行名を複数回もつデータフレームで列名、行名を取得してみましょう。
まずはdf_yの列名、行名を取得してみます。
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df_y = pd.concat([df, df], axis=0)
df_x = pd.concat([df, df], axis=1)
print(df_y.index)
print(df_y.columns)
実行結果
Index(['data1-1', 'data1-2', 'data1-3', 'data1-4', 'data1-5', 'data1-6',
'data1-7', 'data1-8', 'data1-9', 'data1-10', 'data1-1', 'data1-2',
'data1-3', 'data1-4', 'data1-5', 'data1-6', 'data1-7', 'data1-8',
'data1-9', 'data1-10'],
dtype='object', name='dataname')
Index(['value1-1', 'value1-2', 'value1-3', 'value1-4', 'value1-5'], dtype='object')やはり同じ行名が2回入っています。
次にdf_xの行名、列名を取得してみます。
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df_y = pd.concat([df, df], axis=0)
df_x = pd.concat([df, df], axis=1)
print(df_x.index)
print(df_x.columns)
実行結果
Index(['data1-1', 'data1-2', 'data1-3', 'data1-4', 'data1-5', 'data1-6',
'data1-7', 'data1-8', 'data1-9', 'data1-10'],
dtype='object', name='dataname')
Index(['value1-1', 'value1-2', 'value1-3', 'value1-4', 'value1-5', 'value1-1',
'value1-2', 'value1-3', 'value1-4', 'value1-5'],
dtype='object')こちらは同じ列名が2回入っています。
同じ列名、行名を複数回もつデータフレームで列データ、行データを取得してみる
次に同じ列名、行名を複数回もつデータフレームで、列データ、行データを呼び出してみましょう。
先ほどの列名、行名を取得した結果、df_yでは同じ行名が2回、df_xでは同じ列名が2回入っているので、df_yでは行方向、df_xでは列方向のデータを取得してみます。
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df_y = pd.concat([df, df], axis=0)
df_x = pd.concat([df, df], axis=1)
print(df_y.loc["data1-1"])
print(df_x["value1-1"])
実行結果
value1-1 value1-2 value1-3 value1-4 value1-5
dataname
data1-1 90 37 18 36 40
data1-1 90 37 18 36 40
value1-1 value1-1
dataname
data1-1 90 90
data1-2 78 78
data1-3 70 70
data1-4 99 99
data1-5 28 28
data1-6 99 99
data1-7 50 50
data1-8 38 38
data1-9 44 44
data1-10 63 63なんと同じ行名、列名のデータが別で表示されました。
ということは同じ名前が付いている行、列は同列に扱われるということです。
このままでは行名、列名でデータを取得すると、毎回複数のデータが取得されてしまいます。
別々に取得したい場合はどうしたらいいでしょうか?
同じ行名、列名が含まれる場合は行数、列数でデータを取得する
一つの答えとして、行名、列名ではなく、行数、列数で取得するという方法があります。
行数で取得する場合は、「.iloc[行数]」で取得できます。
ということで同じ行名を2回もつdf_yで試してみましょう。
ちなみに1行目(インデックスとして0)と11行目(インデックスとして10) が同じ行名のデータですので、その2つを呼び出してみます。
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df_y = pd.concat([df, df], axis=0)
df_x = pd.concat([df, df], axis=1)
print(df_y.iloc[0])
print(df_y.iloc[10])
実行結果
value1-1 90
value1-2 37
value1-3 18
value1-4 36
value1-5 40
Name: data1-1, dtype: int64
value1-1 90
value1-2 37
value1-3 18
value1-4 36
value1-5 40
Name: data1-1, dtype: int64確かに別の行として呼び出せました。
次に同じ列名をもつdf_xで、同じ列名のデータ(value1-1)を呼び出してみます。
列を呼び出すには「iloc[:,列数]」になります。
同じ列名は1列目(インデックスとして0)、6列目(インデックスとして5)です。
import pandas as pd
df = pd.read_csv("python-pandas-10_data1.txt", index_col=0)
df_y = pd.concat([df, df], axis=0)
df_x = pd.concat([df, df], axis=1)
print(df_x.iloc[:,0])
print(df_x.iloc[:,5])
実行結果
dataname
data1-1 90
data1-2 78
data1-3 70
data1-4 99
data1-5 28
data1-6 99
data1-7 50
data1-8 38
data1-9 44
data1-10 63
Name: value1-1, dtype: int64
dataname
data1-1 90
data1-2 78
data1-3 70
data1-4 99
data1-5 28
data1-6 99
data1-7 50
data1-8 38
data1-9 44
data1-10 63
Name: value1-1, dtype: int64こちらも同じ列名のデータを別の列として呼び出すことができました。
ということで今回は同じ行名や列名をもつデータフレームでのデータの呼び出し方を解説してきました。
結構ややこしくなってしまうので、できれば違う名前にする方が無難だと思います。
ということで次回は行名、列名を変更する方法を解説したいと思います。
ではでは今回はこんな感じで。
コメント