データ解析支援ライブラリPandas
前回、データ解析支援ライブラリPandasを使って、CSVファイルの読み込み方法を解説しました。
今回は読み込んだデータを表示する方法を解説していきます。
まずは前回のおさらいから。
使用するデータは、自作のダミーデータ作成プログラムで作ったこちら。
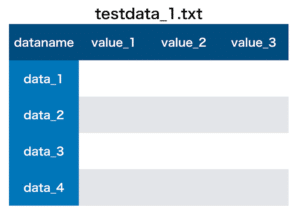
今回は「dataname」の列をインデックス名として用いたいので、こんな感じでデータを読み込んでおきます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df
実行結果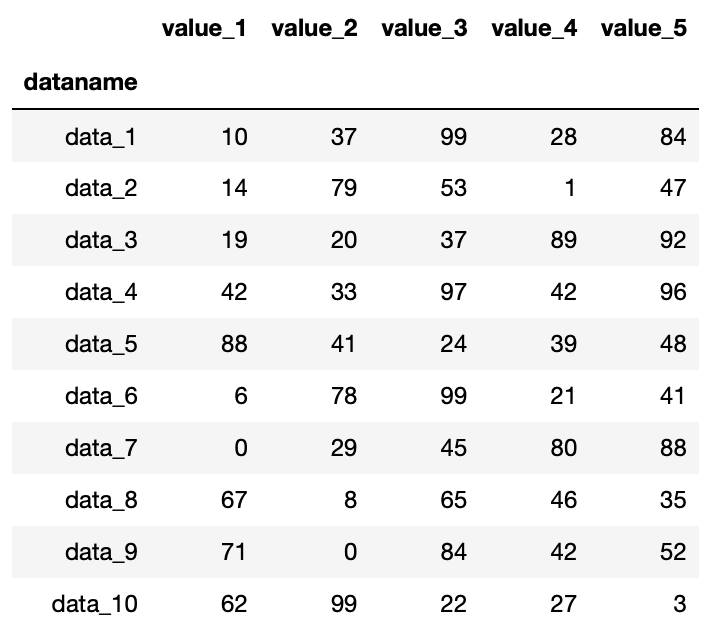
自分が勉強してみて一番最初につまづいたのが、行とか列の取得方法です。
その理由としては、取得方法が色々ありすぎるから。
ということで3PySciでは自分が後で見て分かるように解説していきたいと思います。
行、列を一度に解説すると結構ごちゃごちゃしてしまうので、まずは行から解説していきます。
リスト形式で行を取得する方法
多分一番分かりやすいのは、今まで使ってきたリスト形式で行を指定する方法でしょう。
つまりこんな感じです。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df[0:5]
実行結果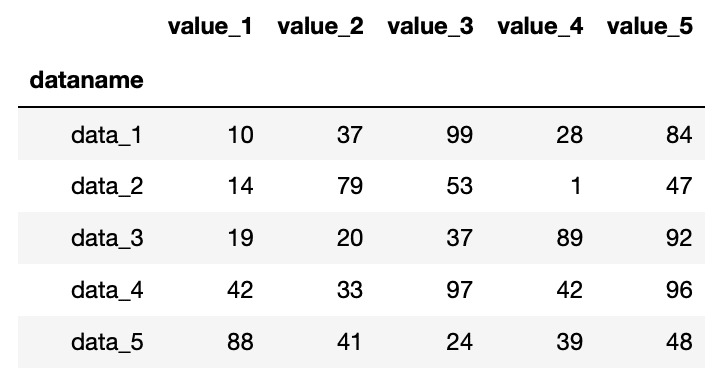
ここで気をつけて欲しいのは、df[X:Y]でXは含み、Yは含まないということです。
今回の場合インデックスとして0(つまり1行目)を含み、インデックスとして5(つまり6行目)は含まないということです。
リストのインデックス指定方法と同じということで、こんなことも可能です。
df[:3]で「最初からインデックス2まで」という指定
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df[:3]
実行結果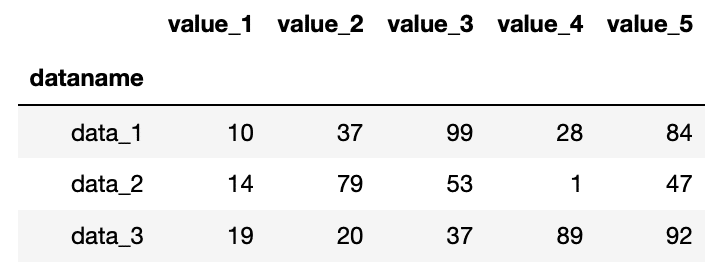
df[7:]でインデックス7から最後までという指定
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df[7:]
実行結果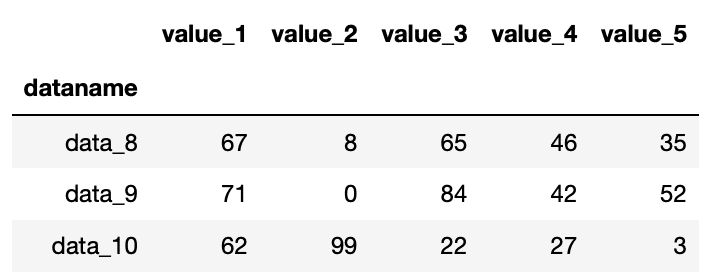
df[3:-4] で前からのインデックス3と後ろからのインデックス4までという指定
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df[3:-4]
実行結果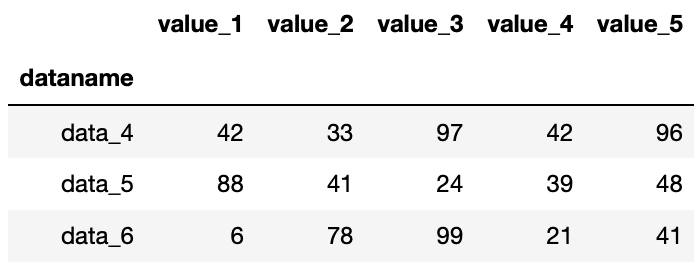
ただここで注意したいのは、1行だけでは指定できないということ。
つまりdf[X]は使えません。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df[5]
実行結果
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
2896 try:
-> 2897 return self._engine.get_loc(key)
2898 except KeyError:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 5
(以下略)1行だけ指定する方法は後ほど解説します。
リスト形式で「インデックス名」を使って取得する方法
通常リスト形式で要素を取得するには、先ほどのようにインデックス番号を使って要素を取得します。
しかしPandasの特徴として、インデックス名を使ってもリスト形式で要素を取得することができます。
ということでこんな感じ。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df["data_1":"data_5"]
実行結果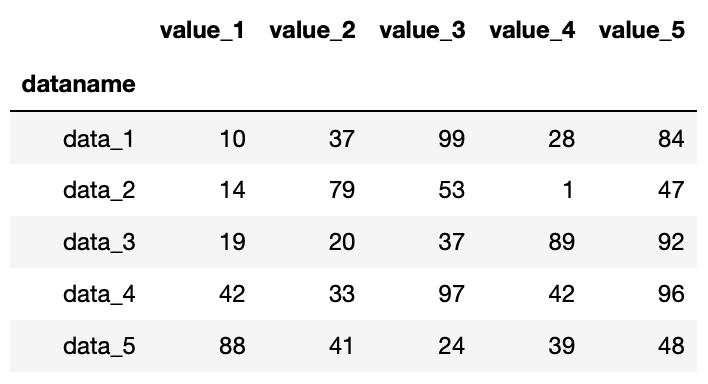
先ほどのように「最初からインデックスXまで」とか「インデックスXから最後まで」といった取得方法もできますが、今回は割愛します。
そしてこのインデックス名を使って要素を取得する方法でも、1行だけ指定するということはできません。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df["data_1"]
実行結果
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
2896 try:
-> 2897 return self._engine.get_loc(key)
2898 except KeyError:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 'data_1'
(以下略)1行だけ指定する方法:.iloc[インデックス]と.loc[インデックス名]
しかし1行だけ指定したいという時もあることでしょう。
その場合は、.iloc、または.locというコマンドを使います。
何故二つあるかというと、.ilocは「インデックス」を指定して行を取得する場合、.locは「インデックス名」を指定して行を取得する場合に用います。
.iloc[インデックス]の場合
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[1]
実行結果
value_1 14
value_2 79
value_3 53
value_4 1
value_5 47
Name: data_2, dtype: int64.loc[“インデックス名”]の場合
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc["data_2"]
実行結果
value_1 14
value_2 79
value_3 53
value_4 1
value_5 47
Name: data_2, dtype: int64ただしこの場合は表形式ではなく、リストと辞書として取得されます。
つまりさらに次のインデックスを指定すると、今度は列を指定できるというわけです。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[1][2]
実行結果
53この場合では最初にインデックス2の要素、つまり「data_2の行」を取得し、次にその中のインデックス2の要素、つまり「value_3」の要素を取得したというわけです。
この場合にもヘッダー名を指定して、列の要素を取得することもできます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[1]["value_3"]
実行結果
53もちろんiloc関数だけでなく、loc関数でも同じです。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc["data_2"]["value_3"]
実行結果
53iloc、loc関数を使って、連続した複数行を取得する方法
iloc関数、またloc関数を使って、複数行を取得することもできます。
ただしその際、少し制限があるので注意が必要です。
とりあえず取得方法を先に解説しましょう。
インデックスを使用して複数行を取得するには、.iloc[インデックス1:インデックス2]とします。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[1:4]
実行結果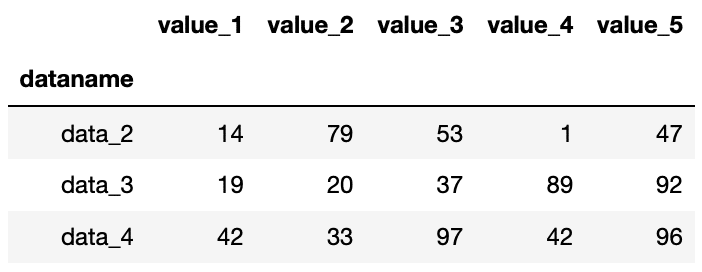
次にインデックス名を使用して、複数行を取得するには、.loc[“インデックス名1″;”インデックス名2”]とします。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc["data_1":"data_4"]
実行結果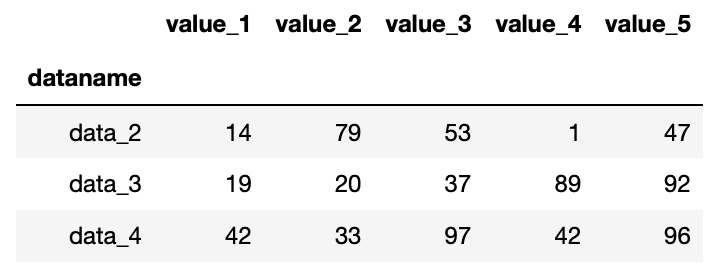
制限というのは、あくまでも連続した複数行しか取得できないということです。
つまり.iloc[インデックス1,インデックス2]や.loc[“インデックス名1″,”インデックス名2”]は使えないということです。
試してみましょう。
.iloc[インデックス1,インデックス2]の場合
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[1,4]
実行結果
47この場合は、.iloc[“インデックス”, “カラム”]と認識されてしまい、上の例では1行目、4列目のデータが表示されることになります。
.loc[“インデックス名1″,”インデックス名2”]
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc["data_2","data_4"]
実行結果
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
2896 try:
-> 2897 return self._engine.get_loc(key)
2898 except KeyError:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 'data_4'
(以下略).iloc[“インデックス”, “カラム”]だったように、.loc[“インデックス名”, “列名”]と認識され、上記の場合は「data_4」 というカラム名がないため、エラーとなります。
試しに存在するカラム名を指定してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc["data_2","value_5"]
実行結果
47確かに一つの値が表示され、.loc[“インデックス名”, “列名”]と認識されていることが分かります。
iloc、loc関数を使って、連続しない複数行を取得する方法
では連続していない複数行を取得したかったらどうしたらいいでしょうか。
その場合は.iloc[[インデックス1,インデックス2]]や.loc[[“インデックス名1″,”インデックス名2”]]とします。
.iloc[インデックス,列]や.loc[“インデックス名”,”列名”]となってしまうため、.iloc[[インデックス1, インデックス2],列]や.loc[[“インデックス名1″,”インデックス名2″],”列名”]とするというわけです。
ただし全部の列を指定する場合、列や”列名”は省略できるため、.iloc[[インデックス1,インデックス2]]や.loc[[“インデックス名1″,”インデックス名2”]]となるというわけです。
試してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[[1, 5]]
実行結果
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc[["data_2", "data_6"]]
連続していない複数行を取得することができました。
データの最初からX行を取得:head()
データを確認するのに全部見るのは大変ですが、上からとか下からちょっと見るなんてこともできます、
データの上から何行かを取得するのには、head()を用います。
例えば最初から5行を取得するにはdf.head(5)とします。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.head(5)
実行結果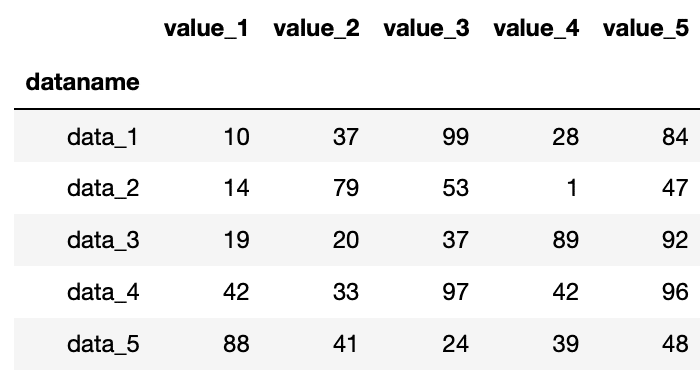
データの最後からX行を取得:tail()
逆にデータの最後から何行か取得するには、tail()を使います。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.tail(5)
実行結果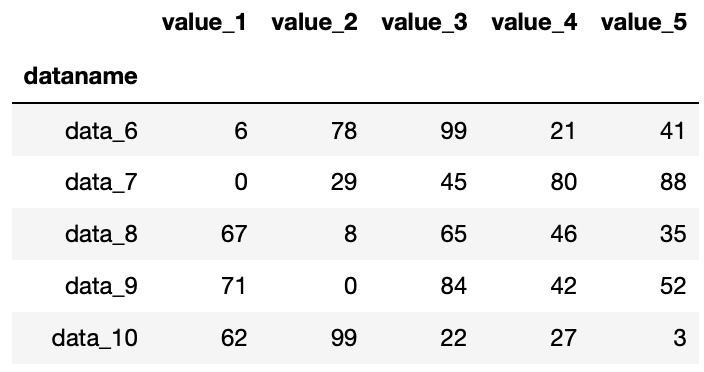
列名を指定して1つの列のデータを取得
次に列を指定してデータを取得する方法を解説していきます。
Pandasで列を取得するのは、行を取得するのと比べて、少しややこしいです。
また1列だけ取得する方が簡単なので、まずは1列だけ取得する方法を解説していきます。
1つの列のデータを取得するには、列名を使い、df[“列名”]とします。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df["value_3"]
実行結果
dataname
data_1 99
data_2 53
data_3 37
data_4 97
data_5 24
data_6 99
data_7 45
data_8 65
data_9 84
data_10 22
Name: value_3, dtype: int64またかぎ括弧を使わずに、df.列名という書き方も可能です。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.value_3
実行結果
dataname
data_1 99
data_2 53
data_3 37
data_4 97
data_5 24
data_6 99
data_7 45
data_8 65
data_9 84
data_10 22
Name: value_3, dtype: int64そしてこの方法で複数の列を取得することはできません。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df["value_2", "value_5"]
実行結果
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
2896 try:
-> 2897 return self._engine.get_loc(key)
2898 except KeyError:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: ('value_2', 'value_5')
(以下略)ここからがややこしくなってくるので、なるべく場合分けして解説していきます。
全ての行、特定の列のデータを取得:.iloc[:, 列]、.loc[:, “列名”]
まずは全ての行、特定の列のデータの取得方法です。
これは先ほどのdf[“列名”]やdf.列名と同じ意味ですが、今後の解説のためにまずはここから解説します。
列番号を使う.iloc[:, 列]と列名を使う.loc[:, “列名”]があります。
「.iloc[:, 列]」を試してみるとこんな感じです。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[:, 3]
実行結果
dataname
data_1 28
data_2 1
data_3 89
data_4 42
data_5 39
data_6 21
data_7 80
data_8 46
data_9 42
data_10 27
Name: value_4, dtype: int64「.loc[:, “列名”]」ではこうなります。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc[:, "value_4"]
実行結果
dataname
data_1 28
data_2 1
data_3 89
data_4 42
data_5 39
data_6 21
data_7 80
data_8 46
data_9 42
data_10 27
Name: value_4, dtype: int64これは前回少し出てきたように.iloc[X,Y]だったり、df.loc[X, Y]ではX行目のY列目のデータを取得すると認識されることから、Xに「:(コロン)」を使うことで、X行全てと指定することができるというわけです。
全ての行、連続した複数の列のデータを取得:.iloc[:, 列1:列2]、.loc[:, “列名1″:”列名2”]
次に全ての行、連続した列のデータの取得方法です、
この場合は、.iloc[:, 列1:列2]、.loc[:, “列名1″:”列名2”]という記述方法ができます。
まずは.iloc[:, 列1:列2]を試してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[:, 1:4]
実行結果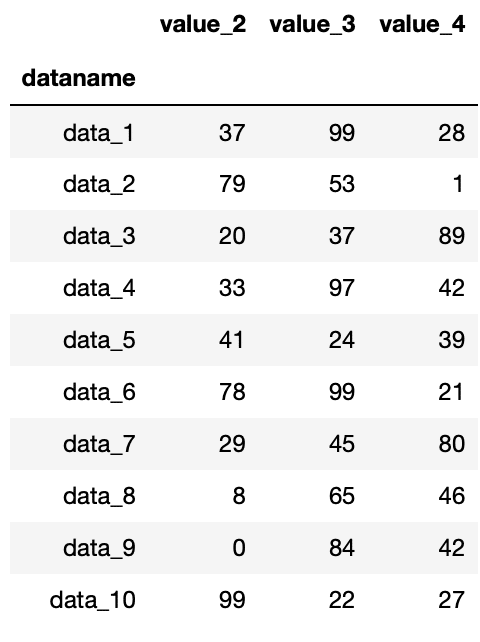
次に.loc[:, “列名1″:”列名2”]を試してみます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc[:,"value_2":"value_4"]
実行結果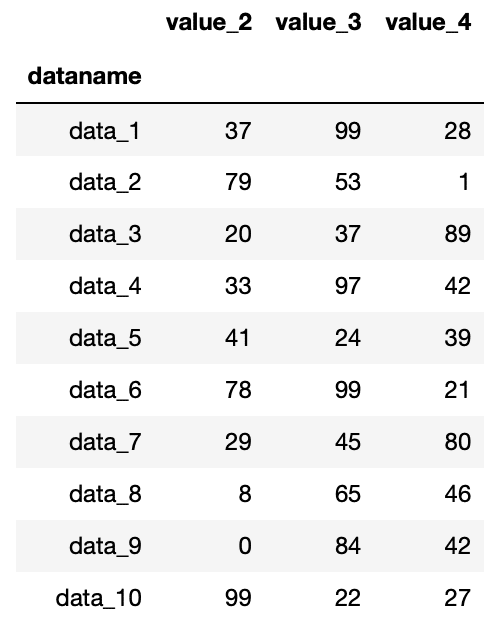
全ての行、連続していない複数の列のデータを取得:.iloc[:, [列1,列2]]、.loc[:, [“列名1”,”列名2″…]]
連続していない複数の列のデータを取得するのは、前回解説した「連続しない複数行を取得する方法」と似ています。
連続しない複数行を取得する場合、.iloc[[インデックス1, インデックス2],列]や.loc[[“インデックス名1″,”インデックス名2″],”列名”]とすると解説しました。
しかし全部の列を指定する場合、列や”列名”は省略できるため、.iloc[[インデックス1,インデックス2]]や.loc[[“インデックス名1″,”インデックス名2”]]とも解説しました。
つまり基本は.iloc[インデックス,列]や.loc[“インデックス名”,”列名”]で、インデックス、またはインデックス名を全てを示す「:(コロン)」にします。
そして.iloc[:, [列1,列2…]]、.loc[:, [“列名1”,”列名2″…]]とするわけです。
ということで試してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[:,[1, 4]]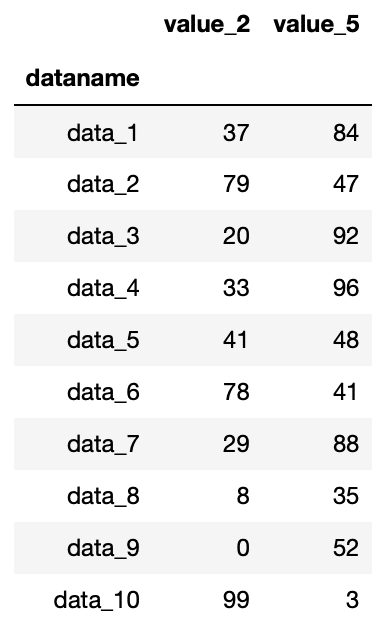
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc[:,["value_2", "value_5"]]
実行結果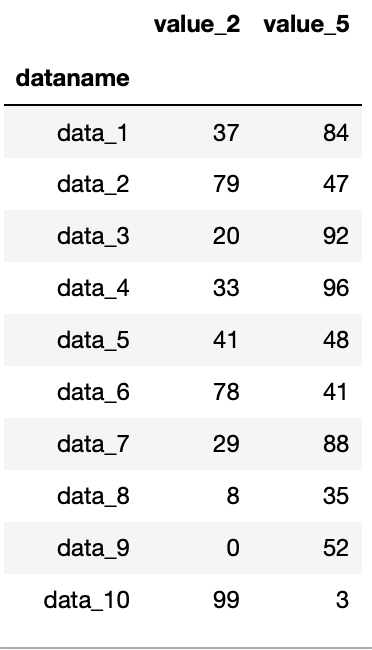
特定の列、特定の行を指定してデータを取得
次に列と行の両方を指定してデータを取得する方法を紹介します。
ここからはなかなかややこしいので、先にやることをリスト化してみます。
- 行:連続した複数、列:連続した複数
- 行:連続した複数、列:連続しない複数
- 行:連続しない複数、列:連続した複数
- 行:連続しない複数、列:連続しない複数
重要なのは取得するデータが連続しているか、していないかということです。
またそれぞれに行数(インデックス)や列数(カラム)で指定する場合と名前で指定する場合があります。
少しずつ解説していきましょう。
連続した複数行、連続した複数列を取得する方法
まずは行も列も連続している場合で、行数や列数で指定する場合です。
この場合は.iloc[行数1:行数2, 列数1:列数2]と指定します。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[1:3, 2:5]
実行結果
行名や列名で指定する場合は、.loc[行名1:行名2, 列名1:列名2]とします。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc["data_2":"data_3", "value_3":"value_5"]
実行結果
どちらの場合も、行数や列数と行名や列名を混ぜて指定することはできません。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[1:3, "value_3":"value_5"]
実行結果
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-171-b733f8541a46> in <module>
3 df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
4
----> 5 df.iloc[1:3, "value_3":"value_5"]
(以下略)import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc[1:3, "value_3":"value_5"]
実行結果
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-176-9cd6ed5894ad> in <module>
3 df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
4
----> 5 df.loc[1:3, "value_3":"value_5"]
(以下略)連続した複数行、連続しない複数列を取得する方法
次は行は連続していて、列は連続していない場合です。
この場合で列数、行数で指定するには.iloc[行数1:行数2, [列数1, 列数2…]]とします。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[0:3, [0,2,4]]
実行結果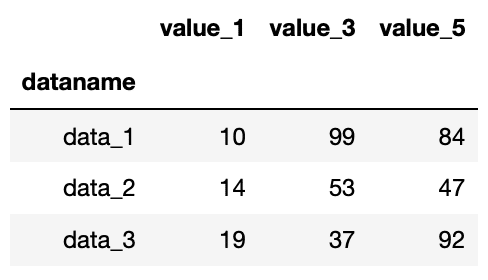
名前で指定する場合は、.loc[行名1:行名2, [列名1, 列名2…]]となります。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc["data_1":"data_3", ["value_1", "value_3", "value_5"]]
実行結果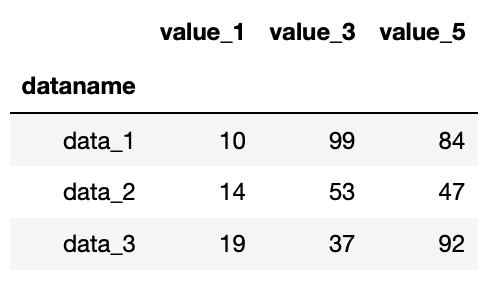
連続しない複数行、連続した複数列を取得する方法
次は行は連続していなくて、列は連続している場合です。
行数、列数で取得する場合は、iloc[[行数1, 行数2…], 列数1:列数2]となります。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[[0, 2, 4], 2:5]
実行結果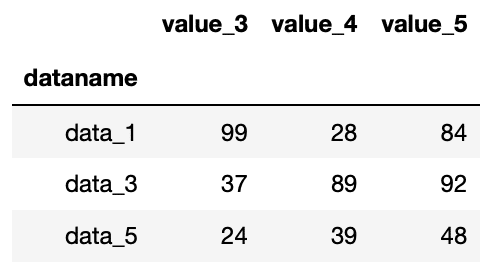
そして行名、列名で取得する場合は、.loc[[行名1, 行名2…], 列名1:列名2]です。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc[["data_1", "data_3", "data_4"], "value_3":"value_5"]
実行結果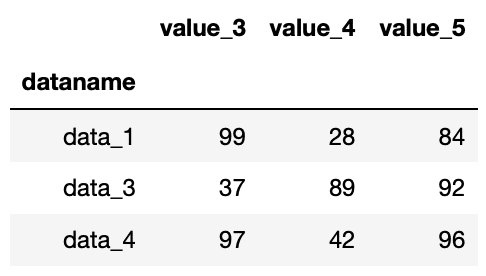
連続しない複数行、連続しない複数列を取得する方法
ということで最後に行も列も連続しない箇所を指定して取得する方法です。
この場合を行数、列数で取得する場合は、iloc[[行数1, 行数2…], [列数1, 列数2…]]となります。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[[0, 3, 6], [0, 2, 4]]
実行結果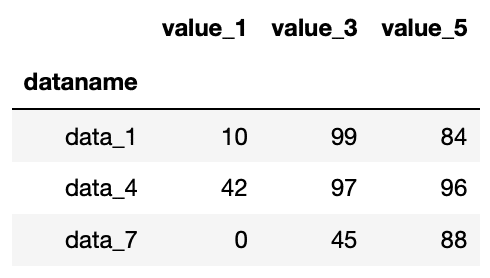
行名、列名で取得する場合は、.loc[[行名1, 行名2…], [列名1, 列名2…]]となります。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.loc[["data_1", "data_4", "data_7"], ["value_1", "value_3", "value_5"]]
実行結果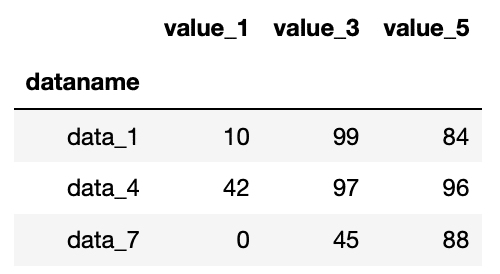
ややこしい例を紹介
ここまででPandasで行や列を指定してデータを取得する方法は理解が進んできたと思います。
というよりも私自身の理解が進みました。
でもせっかくなのでもう一つその理解を壊して、また分からなくする例を紹介したいと思います。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[2:5]["value_2"]
実行結果
dataname
data_3 20
data_4 33
data_5 41
Name: value_2, dtype: int64行数や列数を指定してデータを取得する.ilocですが、何故か最後に[“value_2”] と列名で指定しているにも関わらず、ちゃんと処理できています。
では列名は複数指定できるのでしょうか?
まずは連続した列名にしてみます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[2:5]["value_2":"value_4"]
実行結果
エラーは出なかったものの、思ったような処理にはなっていません。
では次に連続していない場合です。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[2:5]["value_2", "value_4"]
実行結果
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
2896 try:
-> 2897 return self._engine.get_loc(key)
2898 except KeyError:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: ('value_2', 'value_4')
(以下略)こちらはエラーになりました。
ちなみに列名ではなく、列数では指定できるのでしょうか?
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[2:5][1]
実行結果
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
2896 try:
-> 2897 return self._engine.get_loc(key)
2898 except KeyError:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 1
(以下略).ilocに列数で指定したのに、エラーとなってしまいました。
なんでこうなるか考えてみましょう。
df.iloc[2:5][“value_2”]のみ処理が成功しています。
多分、df.iloc[2:5]までで新しいテーブルができていて、それに対して前回説明した1つの列を取得するdf[“列名”]という処理がされているのでしょう。
その証拠に「df.iloc[2:5].value_2」という指定方法も可能です。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df.iloc[2:5].value_2
実行結果
dataname
data_3 20
data_4 33
data_5 41
Name: value_2, dtype: int64一応紹介してみましたが、個人的には列数や行数と列名、行名が混ぜこぜになってしまい、分かりにくいので使用しないと思います。
基本的には、
- .iloc[行数, 列数]
- .loc[行名, 列名]
そして両方ともリストと同じ指定方法が可能、つまり
- [X, Y, Z]でX、Y、Zを取得
- [X:]でX以降最後まで取得
- [:Y]で最初からYまで取得(ilocではYを含まず、locではYを含む)
- [X:Y]でXからYまで取得(ilocではYを含まず、locではYを含む)
ということを覚えておけばいいのかなと思っています。
何とかデータの取得方法が分かったところで、次回は列名や行名、また列数や行数を取得する方法を解説していきたいと思います。
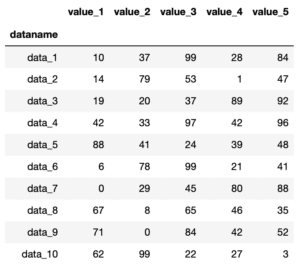
ということで今回はこんな感じで。
コメント