データ解析支援ライブラリPandas
前回はデータ解析支援ライブラリPandasで欠損値nanを平均値や中央値で置き換える方法を解説しました。
今回は欠損値nanを含む行や列を削除する方法を解説していきます。
まずは準備から。
今回は前回用いたデータと、そのデータを少し修正したデータを用います。
何が違うかを確認してみましょう。
まずは両方のデータを読み込んだ上で、前回用いたデータを表示してみます。
import pandas as pd
df1 = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df2 = pd.read_csv("python-pandas-17_data1.txt", index_col = 0)
df1
実行結果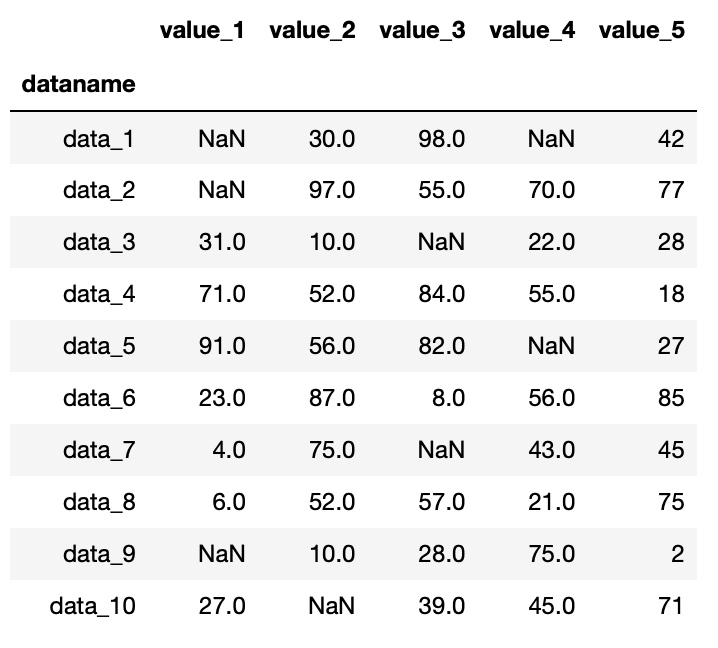
次に修正したデータを表示してみます。
import pandas as pd
df1 = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df2 = pd.read_csv("python-pandas-17_data1.txt", index_col = 0)
df2
実行結果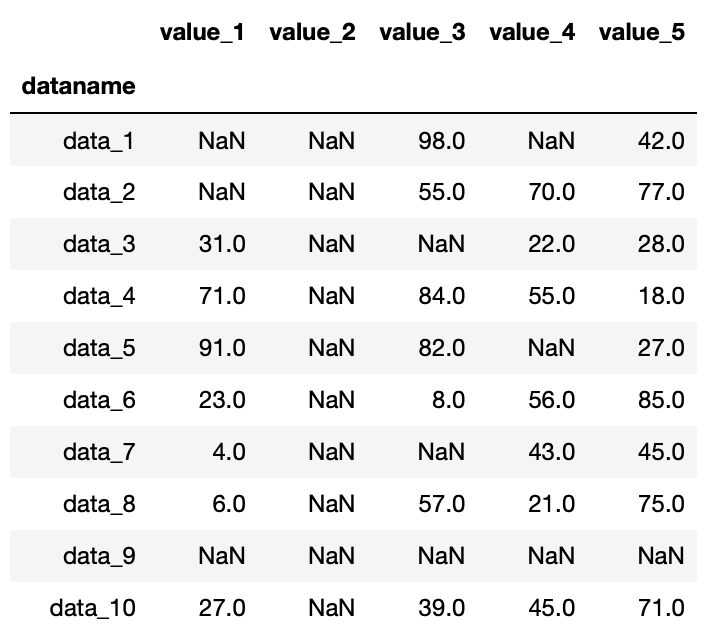
修正したデータで変わっているのは「value_2」の列と「data_9」の行で、全ての値が欠損値nanになっている点です。
ではでは解説を始めていきましょう。
欠損値nanが一つでも入っている行、列を削除する方法
まずは欠損値nanが一つでも入っている行、列を削除してみます。
ここでは修正前のデータ、つまりdf1を使っていきます。
欠損値nanが一つでも入っている行、列を削除するには「.dropna()」を用います。
import pandas as pd
df1 = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df2 = pd.read_csv("python-pandas-17_data1.txt", index_col = 0)
df1.dropna()
実行結果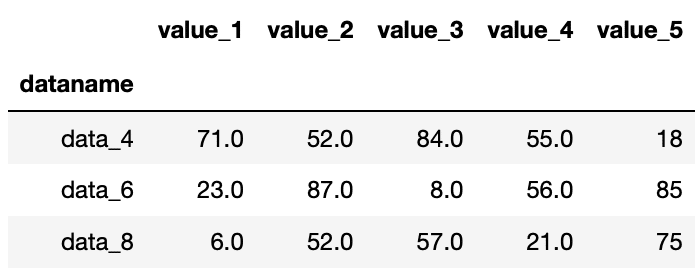
単に「.dropna()」とすると欠損値nanが一つでも含まれる行が削除されます。
ちなみに行、列を指定するにはオプションで「axis」を追加します。
その場合、「axis=0」、または「axis=”index”」とすると行を「axis=1」、または「axis=”columns”」とすると列を指定できます。
ということで、まずは「axis=0」と指定してみましょう。
import pandas as pd
df1 = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df2 = pd.read_csv("python-pandas-17_data1.txt", index_col = 0)
df1.dropna(axis=0)
実行結果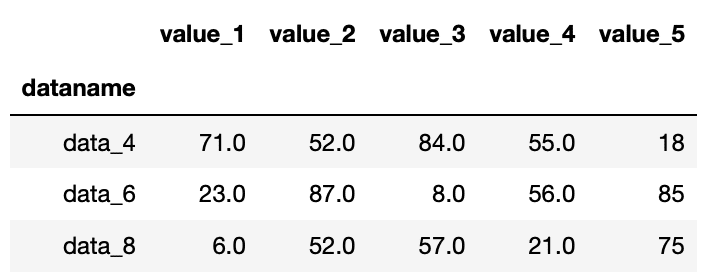
オプションを追加しなかった場合と同様、欠損値nanを含む行が削除されました。
次に「axis=1」 をオプションで指定してみましょう。
import pandas as pd
df1 = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df2 = pd.read_csv("python-pandas-17_data1.txt", index_col = 0)
df1.dropna(axis=1)
実行結果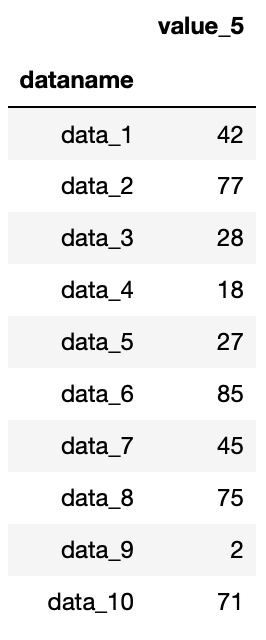
今度は欠損値nanを一つでも含む列が削除されました。
全ての値が欠損値nanである行、列を削除する方法
次に全ての値が欠損値nanである行、列のみを削除する方法を試してみましょう。
この場合は、修正したデータ、つまりdf2を使って解説していきます。
全ての値が欠損値nanである行、列を削除するには、先ほどの「axis」に加え、「how」というオプションを追加します。
「how」で指定できる値は「all」と「any」があります。
全ての値が欠損値nanだった時、その行、列を削除するには「how=”all”」とします。
まずは行(axis=0)から試してみましょう。
import pandas as pd
df1 = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df2 = pd.read_csv("python-pandas-17_data1.txt", index_col = 0)
df2.dropna(axis=0, how="all")
実行結果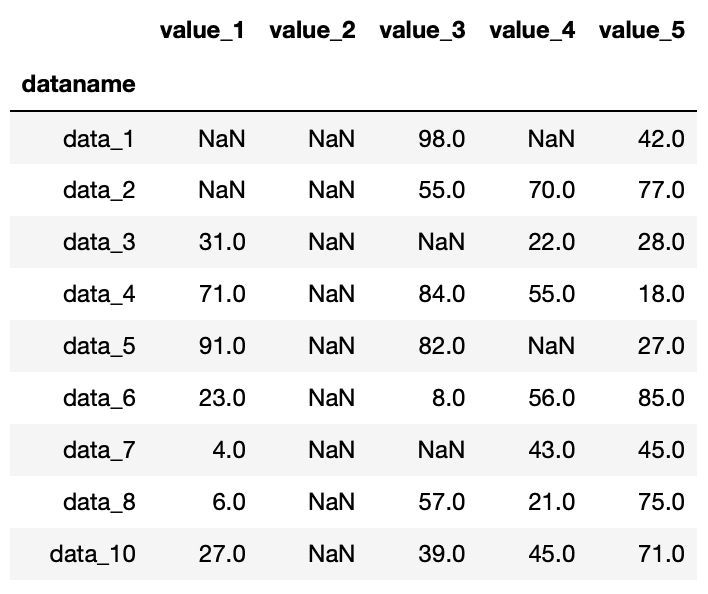
全ての値が欠損値nanである行、つまり「data_9」の行のみ削除されました。
次に列(axis=1)を試してみます。
import pandas as pd
df1 = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df2 = pd.read_csv("python-pandas-17_data1.txt", index_col = 0)
df2.dropna(axis=1, how="all")
実行結果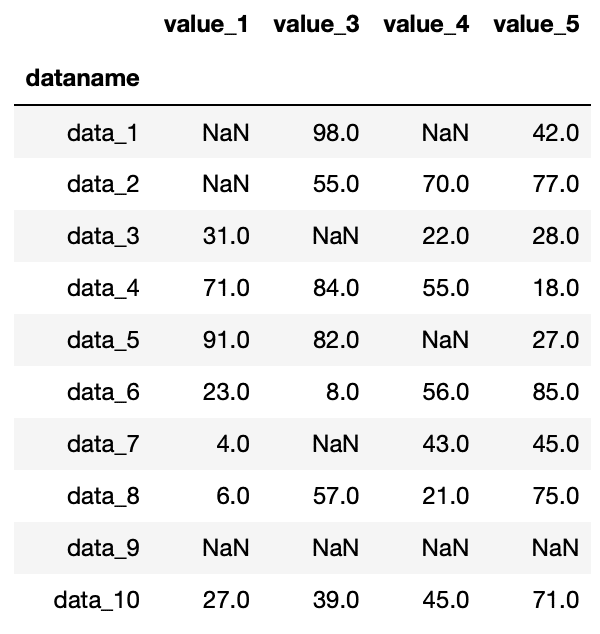
今度は全ての値が欠損値nanである列、つまり「value_2」の列のみ削除されました。
.dropna(how=”any”)だとどうなるか?
次にhowのオプションに”any”を指定してみます。
まずは行(axis=0)から試してみましょう。
import pandas as pd
df1 = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df2 = pd.read_csv("python-pandas-17_data1.txt", index_col = 0)
df2.dropna(axis=0, how="any")
実行結果
全ての行が削除されてしまいました。
howのオプションに「”any”」 を指定すると、一つでも欠損値nanが入っている行、列を削除するということです。
ちなみに「how」を指定しないと、デフォルトではこの「”any”」が指定されるようになっています。
ついでに列(axis=1)でも試しておきましょう。
import pandas as pd
df1 = pd.read_csv("python-pandas-14_data1.txt", index_col = 0)
df2 = pd.read_csv("python-pandas-17_data1.txt", index_col = 0)
df2.dropna(axis=1, how="any")
実行結果
今度は全ての列が削除されました。
これで欠損値nanが入っている場合、前に解説したように何かの値で置き換える、またはその行、列を削除するという対策ができるようになりました。
とりあえず欠損値nanが入っている時はどちらかで対応すると思うので、これでとりあえずは欠損値nanに関しては終了かなと。
次回はそろそろPandasにも慣れてきたので、データフレームを自分で作成してみるということにチャレンジしてみたいと思います。
ではでは今回はこんな感じで。
コメント