Pandas
前回、PythonのPandasで行名や列名を一括で変更する方法を紹介しました。
今回はPandasでデータフレームからデータを抽出し、concatを使って連結させる場合に注意することを紹介します。
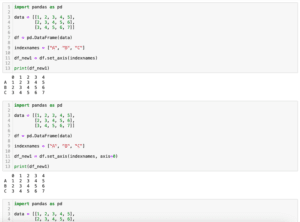
まずはデータフレームを2つこんな感じで準備してみました。
import pandas as pd
columnnames = ["a", "b", "c", "d" , "e"]
data1 = [[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7]]
data2 = [[10, 20, 30, 40 ,50],
[20, 30, 40, 50, 60],
[30, 40, 50, 60, 70]]
df1 = pd.DataFrame(data1, columns=columnnames)
df2 = pd.DataFrame(data2, columns=columnnames)
print(df1)
print("")
print(df2)
実行結果
a b c d e
0 1 2 3 4 5
1 2 3 4 5 6
2 3 4 5 6 7
a b c d e
0 10 20 30 40 50
1 20 30 40 50 60
2 30 40 50 60 70これをconcat([データフレーム1, データフレーム2])を使って縦に連結させてみるとこうなります。
import pandas as pd
columnnames = ["a", "b", "c", "d" , "e"]
data1 = [[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7]]
data2 = [[10, 20, 30, 40 ,50],
[20, 30, 40, 50, 60],
[30, 40, 50, 60, 70]]
df1 = pd.DataFrame(data1, columns=columnnames)
df2 = pd.DataFrame(data2, columns=columnnames)
df3 = pd.concat([df1, df2], axis=0)
print(df3)
実行結果
a b c d e
0 1 2 3 4 5
1 2 3 4 5 6
2 3 4 5 6 7
0 10 20 30 40 50
1 20 30 40 50 60
2 30 40 50 60 70concatについてはこれらの記事でも紹介していますので、よかったらどうぞ。
行名が被ってしまっているところもあるので、人によっては再インデックスしたくなることでしょう。
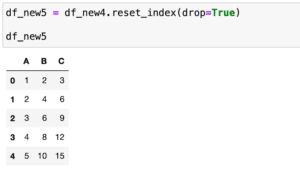
import pandas as pd
columnnames = ["a", "b", "c", "d" , "e"]
data1 = [[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7]]
data2 = [[10, 20, 30, 40 ,50],
[20, 30, 40, 50, 60],
[30, 40, 50, 60, 70]]
df1 = pd.DataFrame(data1, columns=columnnames)
df2 = pd.DataFrame(data2, columns=columnnames)
df3 = pd.concat([df1, df2], axis=0)
df3_re = df3.reset_index(drop=True)
print(df3_re)
実行結果
a b c d e
0 1 2 3 4 5
1 2 3 4 5 6
2 3 4 5 6 7
3 10 20 30 40 50
4 20 30 40 50 60
5 30 40 50 60 70ここまではおさらい。
それでは始めていきましょう。
データフレームから抽出したデータを連結させる場合
先ほどのように単純に2つのデータフレームを連結させる場合、concatとそのオプション引数である「axis」を使えば思い通りに連結できます。
問題はデータフレームからデータを抽出し、それぞれを連結させる場合に起こります。
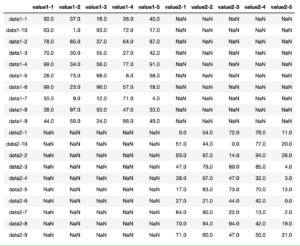
例えば先ほどの1つ目のデータフレーム「df1」の1行目(インデックスとして0)と2つ目のデータフレーム「df2」の1、2行目(インデックスとして1、2)を抽出し、縦方向に連結してみましょう。
import pandas as pd
columnnames = ["a", "b", "c", "d" , "e"]
data1 = [[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7]]
data2 = [[10, 20, 30, 40 ,50],
[20, 30, 40, 50, 60],
[30, 40, 50, 60, 70]]
df1 = pd.DataFrame(data1, columns=columnnames)
df2 = pd.DataFrame(data2, columns=columnnames)
print(df1.iloc[0])
print("")
print(df2.iloc[0:2])
print("")
df4 = pd.concat([df1.iloc[0], df2.iloc[0:2]], axis=0)
print(df4)
実行結果
a 1
b 2
c 3
d 4
e 5
Name: 0, dtype: int64
a b c d e
0 10 20 30 40 50
1 20 30 40 50 60
0 a b c d e
a 1.0 NaN NaN NaN NaN NaN
b 2.0 NaN NaN NaN NaN NaN
c 3.0 NaN NaN NaN NaN NaN
d 4.0 NaN NaN NaN NaN NaN
e 5.0 NaN NaN NaN NaN NaN
0 NaN 10.0 20.0 30.0 40.0 50.0
1 NaN 20.0 30.0 40.0 50.0 60.0先ほど2つのデータフレームを連結するのと同じように連結させたのにも関わらず、縦方向の連結となっていません。
これは抽出した段階で、片方(1行だけ抽出した方)がシリーズ(Series)になってしまっているのが原因です。
import pandas as pd
columnnames = ["a", "b", "c", "d" , "e"]
data1 = [[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7]]
data2 = [[10, 20, 30, 40 ,50],
[20, 30, 40, 50, 60],
[30, 40, 50, 60, 70]]
df1 = pd.DataFrame(data1, columns=columnnames)
df2 = pd.DataFrame(data2, columns=columnnames)
print(type(df1.iloc[0]))
print(type(df2.iloc[0:2]))
実行結果
<class 'pandas.core.series.Series'>
<class 'pandas.core.frame.DataFrame'>シリーズをconcatで連結させると今回のように意図しない動きをするので、注意しましょう。
対応策
対応策としては1行だけ抽出した段階でシリーズになってしまうので、再度データフレームに戻してやることが挙げられます。
その場合「シリーズ.to_frame()」とすることでデータフレームに変換することができます。
import pandas as pd
columnnames = ["a", "b", "c", "d" , "e"]
data1 = [[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7]]
data2 = [[10, 20, 30, 40 ,50],
[20, 30, 40, 50, 60],
[30, 40, 50, 60, 70]]
df1 = pd.DataFrame(data1, columns=columnnames)
df2 = pd.DataFrame(data2, columns=columnnames)
print(df1.iloc[0].to_frame())
print(type(df1.iloc[0].to_frame()))
実行結果
0
a 1
b 2
c 3
d 4
e 5
<class 'pandas.core.frame.DataFrame'>これでデータフレームに戻すことができましたが、問題はもう一つあります。
データフレームから1行抽出し、シリーズとなったものを再度データフレームに変換すると行と列が入れ替わった形になってしまいます。
そこで最後に転置(.transpose()か.T)する必要があります。
import pandas as pd
columnnames = ["a", "b", "c", "d" , "e"]
data1 = [[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7]]
data2 = [[10, 20, 30, 40 ,50],
[20, 30, 40, 50, 60],
[30, 40, 50, 60, 70]]
df1 = pd.DataFrame(data1, columns=columnnames)
df2 = pd.DataFrame(data2, columns=columnnames)
print(df1.iloc[0].to_frame().T)
print(type(df1.iloc[0].to_frame().T))
実行結果
a b c d e
0 1 2 3 4 5
<class 'pandas.core.frame.DataFrame'>これで連結させる準備ができましたので、実際に連結させてみましょう。
import pandas as pd
columnnames = ["a", "b", "c", "d" , "e"]
data1 = [[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7]]
data2 = [[10, 20, 30, 40 ,50],
[20, 30, 40, 50, 60],
[30, 40, 50, 60, 70]]
df1 = pd.DataFrame(data1, columns=columnnames)
df2 = pd.DataFrame(data2, columns=columnnames)
df6 = pd.concat([df1.iloc[0].to_frame().T, df2.iloc[0:2]], axis=0)
print(df6)
実行結果
a b c d e
0 1 2 3 4 5
0 10 20 30 40 50
1 20 30 40 50 60これで2つのデータフレームから抽出したデータを縦方向に正しく連結させることができました。
ちなみに横方向の連結の場合でも1列のみ抽出するとシリーズになってしまうので、データフレームへの変換が必要になります。
ただこの場合は転置は必要ありません。
import pandas as pd
columnnames = ["a", "b", "c", "d" , "e"]
data1 = [[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7]]
data2 = [[10, 20, 30, 40 ,50],
[20, 30, 40, 50, 60],
[30, 40, 50, 60, 70]]
df1 = pd.DataFrame(data1, columns=columnnames)
df2 = pd.DataFrame(data2, columns=columnnames)
df7 = pd.concat([df1.iloc[:,0].to_frame(), df2.iloc[:,1:4]], axis=1)
print(df7)
実行結果
a b c d
0 1 20 30 40
1 2 30 40 50
2 3 40 50 60今回は多分ですがデータフレームを色々弄るようになると直面するだろう抽出したデータの連結に関して注意すること、その対応策をお話ししました。
次回はSciPyでSavitzky-Golay法を使ってデータの平滑化、一次微分、二次微分の方法を紹介します。
ではでは今回はこんな感じで。
コメント