機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnのボストンの住宅価格を予想するのにデータを標準化、正規化をした時の予想値と正解値をプロットし、標準化、正規化の効果を可視化してみました。
今回は前回浮かんだ疑問、標準化と正規化の両方をやったらどうなるのか?ということを試してみたいと思います。
もちろんやっていいことなのか、やっていけないことなのか理論はあるのでしょうが、現状ではまだまだ理解が進んでいないので、こういう場合はやってみるのが一番です。
ということで今回もデータのインポートから。
<セル1>
from sklearn.datasets import load_boston
import pandas as pd
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df["MEDV"] = boston.target
df
実行結果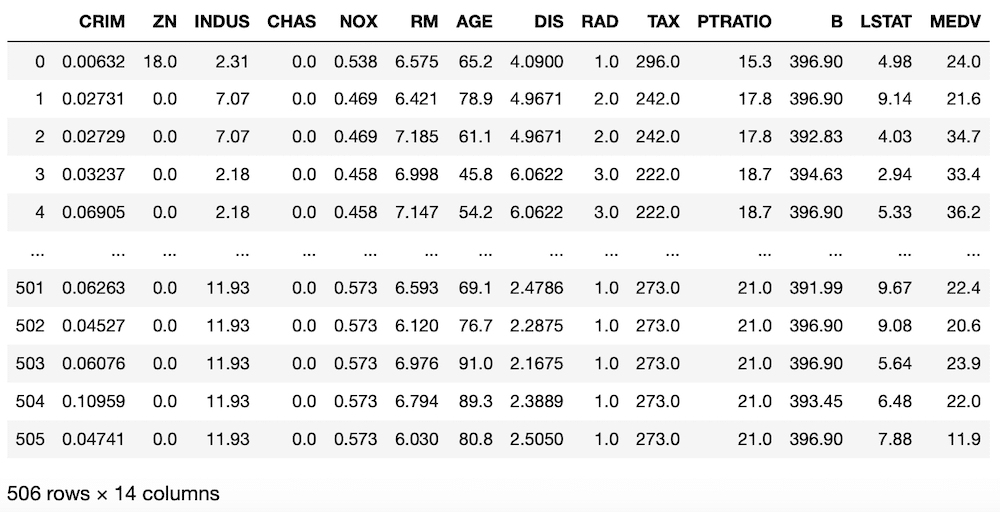
今回は標準化、正規化のやり方を変えていくので事前準備はここまでです。
標準化→正規化、正規化→標準化
ということで標準化と正規化をしていきますが、最初はそれぞれ別に使うプログラムから書いていきましょう。
使うライブラリは標準化と正規化のためのこちらの2つ。
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler次に機械学習させるデータとその結果のデータを変数xとyに格納します。
x = df.loc[:, ["CRIM", "RM", "LSTAT"]]
y = df.loc[:, "MEDV"]機械学習で使うデータはこれまでと同様「CRIM(犯罪率)」、「RM(平均部屋数)」、「LSTAT(低所得者層の割合)」の3つです。
そして標準化、正規化していきます。
std_model = StandardScaler()
x_std = std_model.fit_transform(x)
norm_model = MinMaxScaler()
x_norm = norm_model.fit_transform(x)最後に使いやすいようpandasのデータフレームに変換します。
std = pd.DataFrame(x_std, columns=["CRIM_std", "RM_std", "LSTAT_std"])
norm = pd.DataFrame(x_norm, columns=["CRIM_norm", "RM_norm", "LSTAT_norm"])ここまでは標準化、正規化をしただけのもの。
次に標準化→正規化、逆に正規化→標準化し、こちらもpandasのデータフレームに変換します。
x_std_norm = norm_model.fit_transform(x_std)
x_norm_std = std_model.fit_transform(x_norm)
std_norm = pd.DataFrame(x_std_norm, columns=["CRIM_std_norm", "RM_std_norm", "LSTAT_std_norm"])
norm_std = pd.DataFrame(x_norm_std, columns=["CRIM_norm_std", "RM_norm_std", "LSTAT_norm_std"])これで標準化したもの、正規化したもの、標準化→正規化したもの、正規化→標準化したものの4種類のデータが得られました。
全体としてはこんな感じです。
<セル2>
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
x = df.loc[:, ["CRIM", "RM", "LSTAT"]]
y = df.loc[:, "MEDV"]
std_model = StandardScaler()
x_std = std_model.fit_transform(x)
norm_model = MinMaxScaler()
x_norm = norm_model.fit_transform(x)
x_std_norm = norm_model.fit_transform(x_std)
x_norm_std = std_model.fit_transform(x_norm)
std = pd.DataFrame(x_std, columns=["CRIM_std", "RM_std", "LSTAT_std"])
norm = pd.DataFrame(x_norm, columns=["CRIM_norm", "RM_norm", "LSTAT_norm"])
std_norm = pd.DataFrame(x_std_norm, columns=["CRIM_std_norm", "RM_std_norm", "LSTAT_std_norm"])
norm_std = pd.DataFrame(x_norm_std, columns=["CRIM_norm_std", "RM_norm_std", "LSTAT_norm_std"])グラフ表示してみる
それぞれどう違うのかグラフ表示してみましょう。
まずは「matplotlib」のインポートとマジックコマンドを記述します。
from matplotlib import pyplot as plt
%matplotlib inlineそしてグラフエリアの設定とクリア。
fig=plt.figure(figsize=(8,6))
plt.clf()それぞれのデータのうち”CRIM(犯罪率)”を散布図として表示してみます。
plt.scatter(y, std["CRIM_std"], label="CRIM_std")
plt.scatter(y, norm["CRIM_norm"], label="CRIM_norm")
plt.scatter(y, std_norm["CRIM_std_norm"], label="CRIM_std_norm")
plt.scatter(y, norm_std["CRIM_norm_std"], label="CRIM_norm_std")
plt.legend()ということでこんな感じになります。
<セル3>
from matplotlib import pyplot as plt
%matplotlib inline
fig=plt.figure(figsize=(8,6))
plt.clf()
plt.scatter(y, std["CRIM_std"], label="CRIM_std")
plt.scatter(y, norm["CRIM_norm"], label="CRIM_norm")
plt.scatter(y, std_norm["CRIM_std_norm"], label="CRIM_std_norm")
plt.scatter(y, norm_std["CRIM_norm_std"], label="CRIM_norm_std")
plt.legend()
実行結果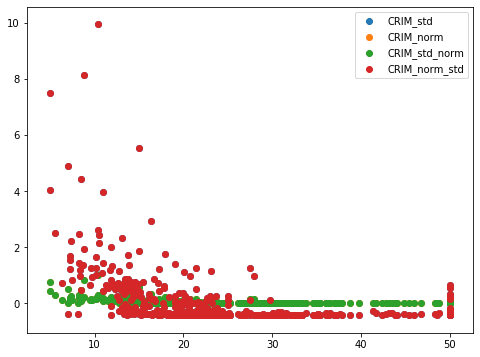
あれ?赤と緑の点しか見えません。
つまり標準化→正規化したデータ、正規化→標準化したデータの2種類しか見えていないということです。
一つ一つ見てみましょう。
まずは標準化したデータから。
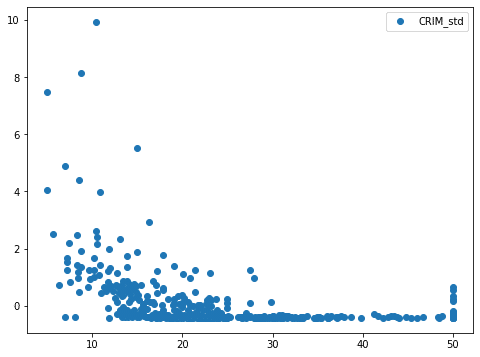
次に正規化したデータ。
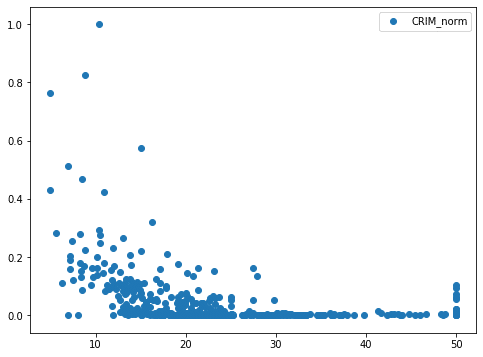
次に標準化→正規化したデータ。
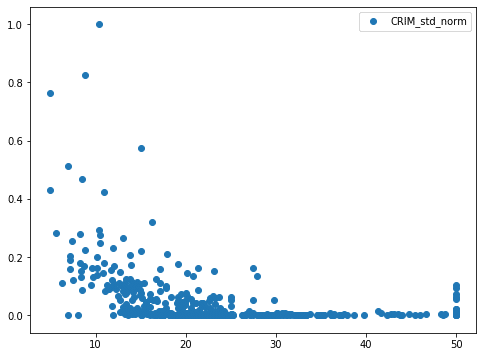
最後に正規化→標準化したデータ。
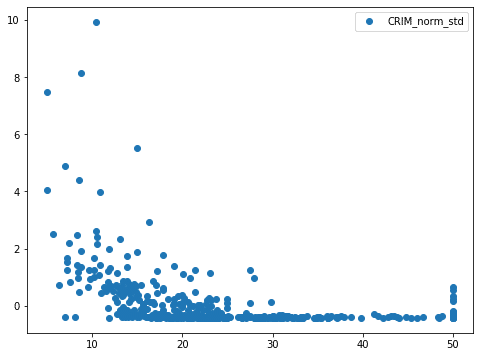
気づきましたでしょうか?
実は標準化したデータと正規化→標準化したデータは同じグラフになっています。
そして正規化したデータと標準化して正規化したデータが同じグラフになっています。
ということでそれぞれ2つずつグラフ化すると、1つのプロットしか見えなくなってしまっているわけです。
標準化したデータと正規化→標準化したデータ。

正規化したデータと標準化→正規化したデータ。
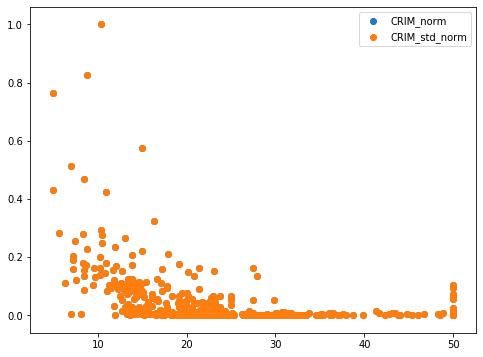
ちなみに”RM(平均部屋数)”でやっても、”LSTAT(低所得者層の割合)”でやっても同じでした。
本当はこの後、機械学習して予想値の精度を比較しようと考えていたのですが、同じになってしまったので、予想精度も同じになることでしょう。
ということで今回は残念ながら実験失敗となってしまいましたが、色々試していく上でこういうことは多々ありますし、こういった失敗を記事にするのも面白いかなと思います。
そろそろこのボストン住宅価格のデータセットも結構使ってきましたし、次回からは新しいデータセットを使って、さらに機械学習を学んでいきたいと思います。
ではでは今回はこんな感じで。
コメント
コメント一覧 (2件)
Python–>機械学習と学習しはじめたロートル・エンジニアです。入門者としてWEBをググり貴方の記事に当たり、Jupyterをインストールして「IRISの分類法」と「ボストンの住宅価格」の連載記事に倣い、勉強させていただいています。
具体的で詳細な記述内容なのでほとんどコピペで進められ、内容の理解度は抜群に進んだような気になっています。実践して示すという貴方の哲学を十分に感じとれます。しかし、さて、私のオリジナルテーマに取り組む際には、全く頓挫するのでしょうね。予想できます。
さて、質問です。私が読んだのはまだ「IRISの分類法」と「ボストンの住宅価格」の2つですが、結果として示されているのが正答率や結果グラフで終わっています。これらの機械学習の成果物である境界域を示す式や回帰式はどのような命令・コードで導き出されるのでしょうか?具体的にお教えいただけると助かります。(入門書によると、機械学習の結果の実行版「***.py」で使う?)
貴方の記事を全て当っていないので見落としがあるかもしれません。既に、この疑問を解決する記事があるのかもしれませんが、あるならその記事名をお教えください。早速、拝読させていただきます。
間さん、初めまして。
記事を読んでいただけていて、実践して示すという私が重要視していることを感じとってもらえてとても嬉しいです。
さてご質問頂いた「機械学習の成果物」に関してですが、まず私は機械学習の専門家でなく、少しかじっただけの素人であるということ、また現在は興味が他に移ってしまい、力を入れていないことを念頭に置いていただき、今回の回答を読んでいただくようお願いします。
(つまり間違ったことやおかしなことを言っていることは十二分にあるので、ご注意くださいませ)
この頃の私の頭の中では「機械学習の成果物=機械学習のモデル」であり、Kaggleのように自分で作成したモデルを使って導き出された値と実際の値がどれくらい合っているかしか考えていなかったです。
(多分これが入門書にあった「機械学習の結果の実行版「***.py」で使う」ということなのではないかなと思います)
そのため、その裏にある統計学的なことは理解しておらず、回帰式を出すということはやっていなかったです。
今、ちょっと調べてみたところ、他サイトですが下記の記事で回帰式の求め方が書いてあるようです(ざっとしか目を通していませんので、間違っていたらごめんなさい)。
https://pythondatascience.plavox.info/scikit-learn/線形回帰
境界に関してはmlxtendというライブラリを使ってグラフ化しています。
https://3pysci.com/python-sklearn-4/
なので、このライブラリの情報を掘ったら、境界を示す式が出てくるのではないかと思って、少し調べてみたのですが、すぐには見つかりませんでした。
また興味が機械学習に戻ったら、新たな記事を書いていきますが、その際にはもう少し統計学も勉強しなければいけないなと思っています。
あまり答えになっておらず申し訳ありませんが、とりあえず上記の内容で、現状での答えとさせていただきますm(_ _)m