機械学習ライブラリScikit-learn
前回は機械学習ライブラリScikit-learnのiris(アヤメ)のデータセットの4種類の特徴量データを使って機械学習してみました。
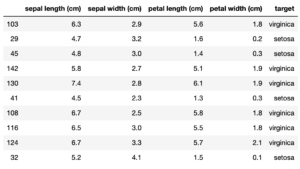
次に特徴量のデータ数を変えて、正解率にどのような影響があるのかを試していきたいのですが、その前にどのように分類を判定しているのか可視化してみましょう。
可視化のためには「mlxtend」というライブラリが必要なので、まずはインストールから行います。
とりあえずJupyter notebookを起動し、「pip install mlxtend」と入力し、実行します。
pip install mlxtend
実行結果
Collecting mlxtend
Downloading https://files.pythonhosted.org/packages/64/e2/1610a86284029abcad0ac9bc86cb19f9787fe6448ede467188b2a5121bb4/mlxtend-0.17.2-py2.py3-none-any.whl (1.3MB)
|████████████████████████████████| 1.3MB 1.6MB/s eta 0:00:01
Requirement already satisfied: scipy>=1.2.1 in /opt/anaconda3/lib/python3.7/site-packages (from mlxtend) (1.3.1)
Requirement already satisfied: scikit-learn>=0.20.3 in /opt/anaconda3/lib/python3.7/site-packages (from mlxtend) (0.21.3)
Requirement already satisfied: numpy>=1.16.2 in /opt/anaconda3/lib/python3.7/site-packages (from mlxtend) (1.17.2)
Requirement already satisfied: pandas>=0.24.2 in /opt/anaconda3/lib/python3.7/site-packages (from mlxtend) (0.25.1)
Requirement already satisfied: joblib>=0.13.2 in /opt/anaconda3/lib/python3.7/site-packages (from mlxtend) (0.13.2)
Requirement already satisfied: setuptools in /opt/anaconda3/lib/python3.7/site-packages (from mlxtend) (41.4.0)
Requirement already satisfied: matplotlib>=3.0.0 in /opt/anaconda3/lib/python3.7/site-packages (from mlxtend) (3.1.1)
Requirement already satisfied: pytz>=2017.2 in /opt/anaconda3/lib/python3.7/site-packages (from pandas>=0.24.2->mlxtend) (2019.3)
Requirement already satisfied: python-dateutil>=2.6.1 in /opt/anaconda3/lib/python3.7/site-packages (from pandas>=0.24.2->mlxtend) (2.8.0)
Requirement already satisfied: cycler>=0.10 in /opt/anaconda3/lib/python3.7/site-packages (from matplotlib>=3.0.0->mlxtend) (0.10.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/anaconda3/lib/python3.7/site-packages (from matplotlib>=3.0.0->mlxtend) (1.1.0)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /opt/anaconda3/lib/python3.7/site-packages (from matplotlib>=3.0.0->mlxtend) (2.4.2)
Requirement already satisfied: six>=1.5 in /opt/anaconda3/lib/python3.7/site-packages (from python-dateutil>=2.6.1->pandas>=0.24.2->mlxtend) (1.12.0)
Installing collected packages: mlxtend
Successfully installed mlxtend-0.17.2
Note: you may need to restart the kernel to use updated packages.「Successfully installed mlxtend-0.17.2」と表示されればインストール成功です。
最後の数字はバージョンなので違う場合があります。
最後に「Note: you may need to restart the kernel to use updated packages.」と書かれているので、Jupyter notebookを再起動しましょう。
前回のSVM機械学習のまとめて可視化の準備
まずは前回作成したSVMの機械学習のプログラムをまとめてしまいます。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df["target"] = iris.target
df["target"][df["target"] == 0] = "setosa"
df["target"][df["target"] == 1] = "versicolor"
df["target"][df["target"] == 2] = "virginica"
x = df.loc[:, ["sepal length (cm)", "sepal width (cm)", "petal length (cm)", "petal width (cm)"]]
y = df.loc[:, "target"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = SVC(gamma="auto")
model.fit(x_train, y_train)
pred_y = model.predict(x_test)
print(accuracy_score(y_test, pred_y))
実行結果
0.9666666666666667それぞれのコマンドの解説は前回の記事を参考にしてください。
この中で可視化するために変えておかなければいけない場所があります。
前回、ターゲット(アヤメの種類)をこちらのコマンドで数字から文字に変えました。
df["target"][df["target"] == 0] = "setosa"
df["target"][df["target"] == 1] = "versicolor"
df["target"][df["target"] == 2] = "virginica"しかし可視化するmlxtendではこのターゲットの値に文字は使えないようなので、数字のままにしておきます。
ということでこの3行は今回は#をつけてコメントアウトしておきます。
<セル1>
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df["target"] = iris.target
# df["target"][df["target"] == 0] = "setosa"
# df["target"][df["target"] == 1] = "versicolor"
# df["target"][df["target"] == 2] = "virginica"
x = df.loc[:, ["sepal length (cm)", "sepal width (cm)", "petal length (cm)", "petal width (cm)"]]
y = df.loc[:, "target"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = SVC(gamma="auto")
model.fit(x_train, y_train)
pred_y = model.predict(x_test)
print(accuracy_score(y_test, pred_y))
実行結果
0.9666666666666667まずはこれで準備は完了です。
データの分類を可視化
それではデータがどのように分類されているか「mlxtend」ライブラリをつかって可視化していきます。
まずはライブラリのインポートから。
グラフ表示ということでmatplotlib、mlxtendではplot_decision_regionsをインポートします。
またJupyter notebookで表示するためにマジックコマンド(%matplotlib inline)を入力しておきます。
from matplotlib import pyplot as plt
from mlxtend.plotting import plot_decision_regions
%matplotlib inline次に可視化するデータを準備します。
準備するデータは特徴量が格納されたデータと分類結果が格納されたデータです。
特徴量が格納されたデータには2種類の特徴量を格納します。
つまりX軸、Y軸がそれぞれ異なる特徴量となるようなデータとするわけです。
ということで「x_train」から特徴量のデータを2つ取得して、変数「x_decision」に格納しておきます。
分類結果が格納されたデータとして「y_train」をそのまま変数「y_decision」に格納しておきます。
x_decision = x_train.iloc[:, [0,1]].values
y_decision = y_train.valuesちなみに「x_train.iloc[:, [0,1]]」のデータは「sepal lengthとsepal width」に当たります。
それぞれの変数に格納するときに気をつけることは、Pandasのデータフレーム形式ではmlxtendで使用できないという点です。
そのためそれぞれ最後に「.values」とつけて、numpyのアレイ(配列)に変換しています。
データを格納したら、先ほど機械学習で使ったサポートベクターマシンのモデルで読み込み、学習させます。
model.fit(x_decision, y_decision)そして「plot_decision_region」を使ってデータをグラフに変換し、「plt.show()」で表示します。
plot_decision_regionの基本的な使い方は、plot_decision_region(X値のデータ、Y値のデータ、clf=モデル)です。
plot_decision_regions(x_decision, y_decision, clf=model)
plt.show()plot_decision_regionにも色々とオプションはありますので、また機会があれば解説したいと思います。
ということでプログラムをまとめてみたのがこちら。
<セル2>
from matplotlib import pyplot as plt
from mlxtend.plotting import plot_decision_regions
%matplotlib inline
x_decision = x_train.iloc[:, [0,1]].values
y_decision = y_train.values
model.fit(x_decision, y_decision)
plot_decision_regions(x_decision, y_decision, clf=model)
plt.show()
実行結果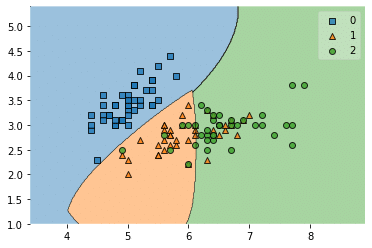
それぞれの領域が色づけされました。
このデータの場合、橙色の点が緑の領域に数個入ってしまっていますし、緑の点が橙色の領域に数個入ってしまっています。
上の例では「sepal lengthとsepal width」を使いましたが、次に違う特徴量の組み合わせ「petal lengthとpetal width」で試してみましょう。
from matplotlib import pyplot as plt
from mlxtend.plotting import plot_decision_regions
%matplotlib inline
x_decision = x_train.iloc[:, [2,3]].values
y_decision = y_train.values
model.fit(x_decision, y_decision)
plot_decision_regions(x_decision, y_decision, clf=model)
plt.show()
実行結果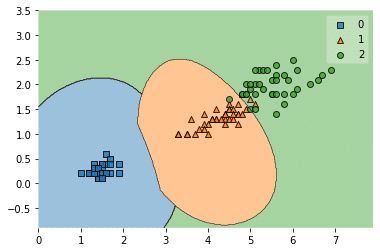
こちらの方がそれぞれの領域に違う点が入っていることが少ないようです。
つまりしっかりと分類できる可能性が高いというわけです。
これでデータ分類の可視化ができるようになりました。
ということで次回は4種全ての特徴量のデータを使った場合と、2種類(petal lengthとpetal width)の特徴量のデータを使った場合で機械学習の正解率にどう違いがでるのか試してみましょう。
ではでは今回はこんな感じで。
コメント