機械学習ライブラリScikit-learn
前回、手書き数字のデータセットのための機械学習モデルを何にしたらよいか、アルゴリズム・チートシートで確認しました。
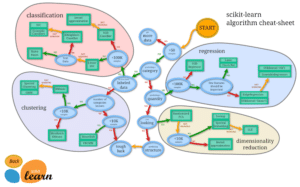
その結果、まずはLinearSVCを試してみるのが良さそうだという結論に至りました。
ということで今回は手書き数字のデータセットを使って、LinearSVCモデルを試してみることにしましょう。
まずはデータの読み込みから。
<セル1>
from sklearn.datasets import load_digits
digits = load_digits(as_frame=True)
digits.frame
実行結果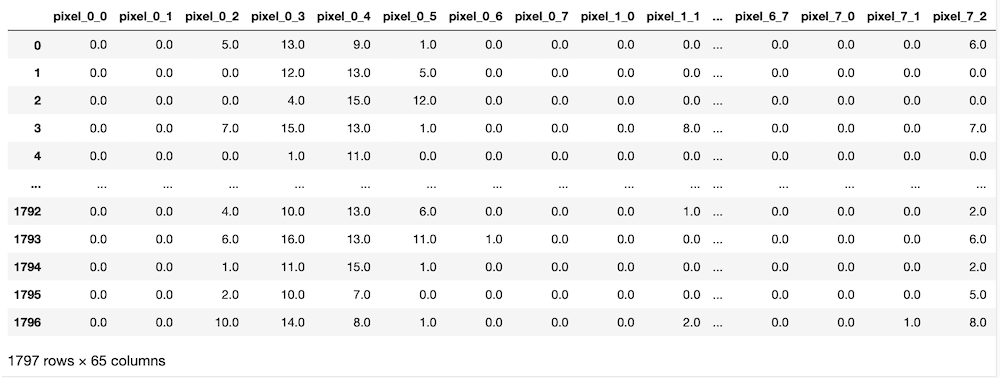
前に手書き数字のデータセットの内容を確認した際、as_frameというオプションを使うことで、Pandasのデータフレームとして読み込めるとのことだったので、今回はそのオプションを使ってみました。
これでデータの読み込みが完了しました。
学習データと解答をリストに格納
学習させるデータをリストxと、その解答をリストyに格納していきましょう。
先ほどのデータフレームを見ると、最後の列が「target」、つまり解答になっています。
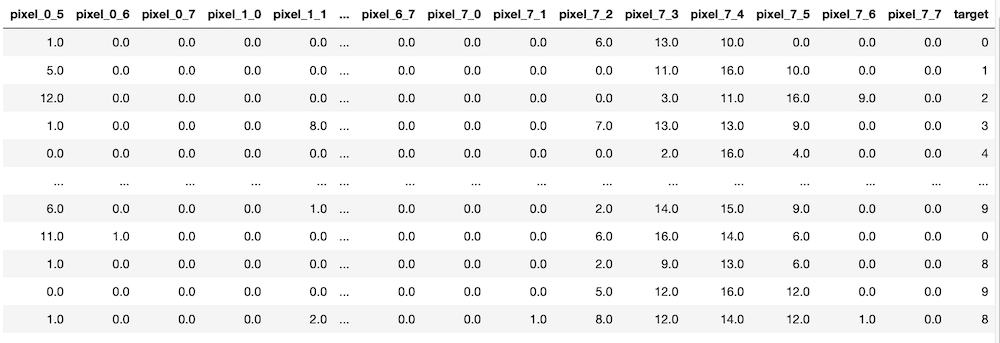
ということで、最初から最後の一つ前までの列をxに、最後の1列をyに格納していきましょう。
<セル2>
x = digits.frame.iloc[:, 0:-1]
y = digits.frame.iloc[:, -1]
実行結果実行しても何も表示されませんが、それで大丈夫です。
「.iloc[A:B, C:D]」とするとA行からB行までで、C列からD列までのデータを取得するとなります。
つまり「digits.frame.iloc[:, 0:-1]」だとdigits.frameのデータフレームのうち、「:」行、つまりは全ての行で、[0:-1]列、つまりは最初から最後の一つ前までの行を取得するということになります。
また「digits.frame.iloc[:, -1]」では、digits.frameのデータフレームのうち、「:」行なので、こちらも全ての行で、「-1」列、つまり最後の行を取得するということです。
これでデータの格納が終わりました。
次はいよいよ機械学習に入っていきます。
LinearSVCで機械学習してみる
今回使う機械学習のモデルは「LinearSVC」。
まずはこちらのモデルのインポートとデータを学習用とテスト用に分割する「train_test_split」のインポート、そしてスコア計算の関数のインポートを行います。
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score上からLinearSVCのインポート、train_test_splitのインポート、スコア計算の関数のインポートです。
ただスコアの計算法はこれまで使っていた「r2_score」ではありません。
r2_scoreは回帰モデル用のスコアで今回のような分類用のスコアではありません。
そこで分類用のスコアである「accuracy_score」を使っています。
Scikit learnのこちらのページを見ると色々なスコア計算の関数が載っています。
あとは実はいつも通り、データを学習用とテスト用に分割し、モデルを読み込み、学習させ、テスト用データで評価するという流れです。
ということでこんな感じです。
<セル3>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC()
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.9666666666666667
/opt/anaconda3/lib/python3.7/site-packages/sklearn/svm/_base.py:977: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations.
"the number of iterations.", ConvergenceWarning)Accuracy_scoreも1に近いほど正解率が高いので、0.96666はかなり高い正解率であると言えるでしょう。
しかし何やら警告が出ています。
「increase the number of iterations」と書かれているので、前にLassoモデルの時に解説した「max_iter」の値を増やせば良さそうです。
試してみましょう。
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=1000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.9638888888888889今度は警告が出ずに終了しました。
しかしスコアがここまで高いとなると、今度は自分で書いた数字もちゃんと分類してくれるのではないかと期待されます。
ということで次回から自分で数字の画像を準備して、データとして読み込ませ、この機械学習データで分類させてみましょう。
次回はまずは画像の準備に関して進めていきます。
ではでは今回はこんな感じで。
コメント