機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnの糖尿病患者のデータセットを使い、LinearRegressionモデルのオプションを試してみました。
今回はLassoモデルのオプションを見ていきましょう。
ということでまずはデータの読み込みから。
<セル1>
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df["target"] = diabetes.target
df
実行結果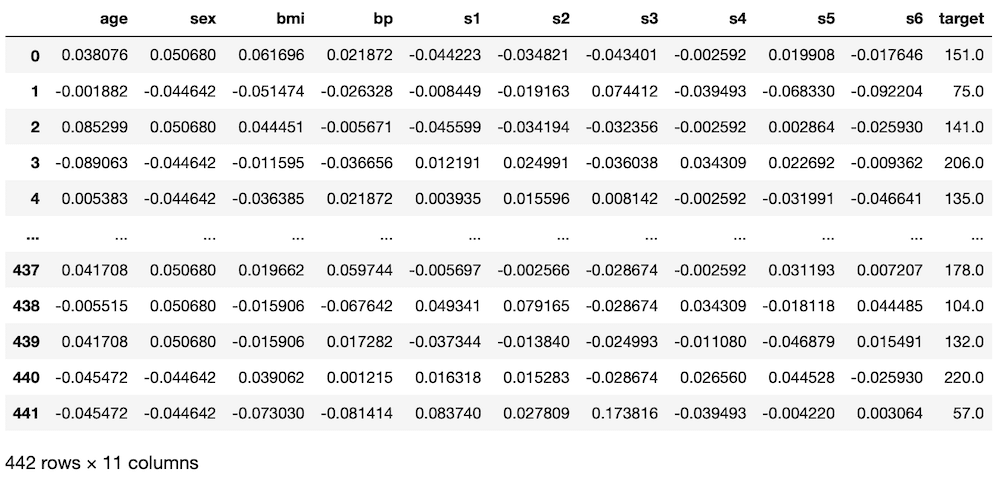
次に機械学習に用いる特徴量とターゲットをそれぞれ変数xとyに格納します。
(後で気付いたのですが、前の記事では「s6」も関連性がありそうということでしたが、忘れてしまいました。他の記事でも上記の組み合わせで行っているものもありますが、忘れたんだなぁと思って読んでください。)
<セル2>
x = df.loc[:, ["bmi", "s5", "bp", "s4", "s3"]]
y = df.loc[:, "target"]
実行結果そしてLassoモデルを読み込んで、いつも通り100回試行した後、そのスコアの平均値を表示します。
また前回同様、過学習になっていないか確認するため、テスト用データでのスコアだけでなく、学習用データでのスコアも計算します。
<セル3>
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Lasso
from sklearn.metrics import r2_score
import numpy as np
trial = 100
pred_lasso_score = []; pred_lasso_train_score = []
for i in range(trial):
x_train_ori, x_test_ori, y_train_ori, y_test_ori = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_lasso = Lasso()
model_lasso.fit(x_train_ori, y_train_ori)
pred_lasso_ori = model_lasso.predict(x_test_ori)
pred_lasso_score.append(r2_score(y_test_ori, pred_lasso_ori))
pred_lasso_ori_train = model_lasso.predict(x_train_ori)
pred_lasso_train_score.append(r2_score(y_train_ori, pred_lasso_ori_train))
pred_lasso_ave = np.average(np.array(pred_lasso_score))
pred_lasso_train_ave = np.average(np.array(pred_lasso_train_score))
print(pred_lasso_ave, pred_lasso_train_ave)
実行結果
0.3405268873920379 0.3584998010903779また所々に「_ori」とつけていますが、これはこのオプションなしで使ったデータをoriginalとして、オプションありのデータと合わせてグラフにプロットするためにつけています。
今回のスコアは「0.34053」と結構低いですが、これが今回の基準になります。
ついでに前回同様、最後の学習で得られたデータをグラフ表示しておきましょう。
<セル4>
from matplotlib import pyplot as plt
fig=plt.figure(figsize=(8,6))
plt.clf()
plt.scatter(y_test_ori, pred_lasso_ori)
実行結果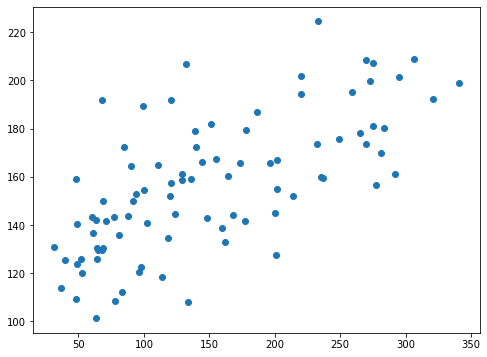
X軸方向が正解値、Y軸方向がLassoモデルで機械学習して予想した値です。
左下から右上への直線に近いものほど、正解値と予想値が近いということになります。
ということで基本の型ができました。
これでLassoモデルのオプションをいじっていきましょう。
Lassoモデルのヘルプ
と、その前にLassoモデルではどのようなオプションが設定できるのか、ヘルプを見て確認しておきましょう。
<セル5>
help(Lasso())
実行結果
Help on Lasso in module sklearn.linear_model._coordinate_descent object
(中略)
|
| Parameters
| ----------
| alpha : float, default=1.0
| Constant that multiplies the L1 term. Defaults to 1.0.
| ``alpha = 0`` is equivalent to an ordinary least square, solved
| by the :class:`LinearRegression` object. For numerical
| reasons, using ``alpha = 0`` with the ``Lasso`` object is not advised.
| Given this, you should use the :class:`LinearRegression` object.
|
| fit_intercept : bool, default=True
| Whether to calculate the intercept for this model. If set
| to False, no intercept will be used in calculations
| (i.e. data is expected to be centered).
|
| normalize : bool, default=False
| This parameter is ignored when ``fit_intercept`` is set to False.
| If True, the regressors X will be normalized before regression by
| subtracting the mean and dividing by the l2-norm.
| If you wish to standardize, please use
| :class:`sklearn.preprocessing.StandardScaler` before calling ``fit``
| on an estimator with ``normalize=False``.
|
| precompute : 'auto', bool or array-like of shape (n_features, n_features), default=False
| Whether to use a precomputed Gram matrix to speed up
| calculations. If set to ``'auto'`` let us decide. The Gram
| matrix can also be passed as argument. For sparse input
| this option is always ``True`` to preserve sparsity.
|
| copy_X : bool, default=True
| If ``True``, X will be copied; else, it may be overwritten.
|
| max_iter : int, default=1000
| The maximum number of iterations
|
| tol : float, default=1e-4
| The tolerance for the optimization: if the updates are
| smaller than ``tol``, the optimization code checks the
| dual gap for optimality and continues until it is smaller
| than ``tol``.
|
| warm_start : bool, default=False
| When set to True, reuse the solution of the previous call to fit as
| initialization, otherwise, just erase the previous solution.
| See :term:`the Glossary <warm_start>`.
|
| positive : bool, default=False
| When set to ``True``, forces the coefficients to be positive.
|
| random_state : int, RandomState instance, default=None
| The seed of the pseudo random number generator that selects a random
| feature to update. Used when ``selection`` == 'random'.
| Pass an int for reproducible output across multiple function calls.
| See :term:`Glossary <random_state>`.
|
| selection : {'cyclic', 'random'}, default='cyclic'
| If set to 'random', a random coefficient is updated every iteration
| rather than looping over features sequentially by default. This
| (setting to 'random') often leads to significantly faster convergence
| especially when tol is higher than 1e-4.Lassoモデルでは、「alpha」、「fit_intercept」、「normalize」、「precompute」、「copy_x」、「max_iter」、「tol」、「warm_start」、「positive」、「random_state」、「selection」というオプションがあるようです。
ちなみに同様の解説はこちらのページでも読めますので、確認してみてください。

「copy_x」、「fit_intercept」、「normalize」に関しては前回解説していますので割愛します。
今回は残りのオプションの中でも予想結果に影響を与えそうで、かつ今後もよくいじりそうな「alpha」、「max_iter」、「tol」に関して色々と試していこうと思います。
alpha
alpha: Lassoモデルでは正則化と呼ばれるパラメータの学習に制限をかけ、過学習を防ぐ仕組みがある。alphaはその制限をかけるための係数。
float値(小数)、デフォルト値は1.0
デフォルトが1.0なので、制限を強くかける方としてalphaを10に、制限を緩くする方としてalphaを0.1にしてみましょう。
それぞれ「model_lasso = Lasso(alpha=10)」、「model_lasso = Lasso(alpha=0.1)」として機械学習モデルを作成し、学習させます。
ということでまずはalpha=10から。
<セル6 alphe=10>
trial = 100
pred_lasso_score = []; pred_lasso_train_score = []
for i in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_lasso = Lasso(alpha=10)
model_lasso.fit(x_train, y_train)
pred_lasso = model_lasso.predict(x_test)
pred_lasso_score.append(r2_score(y_test, pred_lasso))
pred_lasso_train = model_lasso.predict(x_train)
pred_lasso_train_score.append(r2_score(y_train, pred_lasso_train))
pred_lasso_ave = np.average(np.array(pred_lasso_score))
pred_lasso_train_ave = np.average(np.array(pred_lasso_train_score))
print(pred_lasso_ave, pred_lasso_train_ave)
実行結果
-0.013278722989199205 0.0なんとパラメータの学習に制限を強くかけるalpha=10では予想精度は0になってしまいました。
グラフも表示させてみましょう。
<セル7 alpha=10>
fig=plt.figure(figsize=(8,6))
plt.clf()
plt.scatter(y_test_ori, pred_lasso_ori)
plt.scatter(y_test, pred_lasso)
実行結果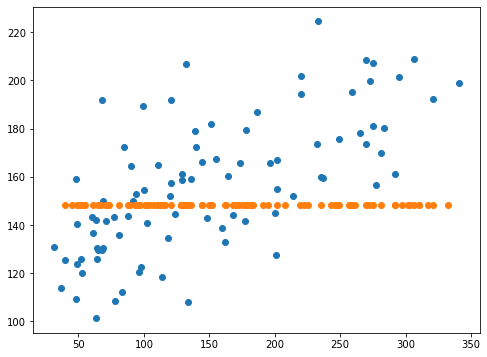
青点がalphaの設定なし、橙点がalpha=10の結果です。
どうやら制限を強くかけすぎて、予想した値が全て1点に集中してしまったようです。
ではパラメータの学習の制限をゆるくするalpha=0.1ではどうでしょうか?
<セル6 alpha=0.1>
trial = 100
pred_lasso_score = []; pred_lasso_train_score = []
for i in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_lasso = Lasso(alpha=0.1)
model_lasso.fit(x_train, y_train)
pred_lasso = model_lasso.predict(x_test)
pred_lasso_score.append(r2_score(y_test, pred_lasso))
pred_lasso_train = model_lasso.predict(x_train)
pred_lasso_train_score.append(r2_score(y_train, pred_lasso_train))
pred_lasso_ave = np.average(np.array(pred_lasso_score))
pred_lasso_train_ave = np.average(np.array(pred_lasso_train_score))
print(pred_lasso_ave, pred_lasso_train_ave)
実行結果
0.46205185344435434 0.49267932530430864かなり予想精度が向上したようです。
こちらもグラフを表示させてみましょう。
<セル7 alpha=0.1>
fig=plt.figure(figsize=(8,6))
plt.clf()
plt.scatter(y_test_ori, pred_lasso_ori)
plt.scatter(y_test, pred_lasso)
実行結果
alphaの設定がない青点とalpha=0.1にした橙点で両方とも同じようにばらつきました。
ただよくみてみると、橙点の方がY軸方向、つまり予想した値のばらつきが大きくなっているのが分かります。
alphaのデフォルトが1.0なので、パラメータの学習に多少なりとも制限がかかり、ばらつきが少なくなっているのではないかなと思います。
ちなみに気をつける点は、alphaを0にしないことです。
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html
alpha = 0is equivalent to an ordinary least square, solved by theLinearRegressionobject.
alphaを0 にするとLinearRegressionと同じになる、つまりLassoモデルの意味がなくなってしまうということです。
確かにalphaを0.1にするとスコアが「0.46205」と前回試したLinearRegressionの「0.46250」と近くなっていることが分かります。
このことからもLassoモデルはLinearRegressionモデルに近いものだと分かりますね。
max_iter、tol
「max_iter」と「tol」は同時に使うことが予想されるオプションです。
max_iter: 学習の試行の最大数。この試行数かtolで指定した値よりもスコアの向上値が小さくなるのが続いたら、学習が終了する。
int値(整数)、デフォルト値は1000
tol: 学習のスコアが収束したか判断するための値。この値よりもスコアの向上値が小さくなるのが続いた際、学習が終了する。
float値(小数)、デフォルト値は1e-4
分かりにくいですが、Lassoモデルでは内部で何度も学習を行い、各パラメータの調整をするようです。
その終了の合図を回数で指定するのが「max_iter」、収束値で指定するのが「tol」ということです。
ではでは試してみましょう。
まずはmax_iterを10、tolを1e-1にして、あまり学習をさせないモデルとしてみます。
<セル8 max_iter=10, tol=1e-1>
trial = 100
pred_lasso_score = []; pred_lasso_train_score = []
for i in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_lasso = Lasso(max_iter=10, tol=1e-1)
model_lasso.fit(x_train, y_train)
pred_lasso = model_lasso.predict(x_test)
pred_lasso_score.append(r2_score(y_test, pred_lasso))
pred_lasso_train = model_lasso.predict(x_train)
pred_lasso_train_score.append(r2_score(y_train, pred_lasso_train))
pred_lasso_ave = np.average(np.array(pred_lasso_score))
pred_lasso_train_ave = np.average(np.array(pred_lasso_train_score))
print(pred_lasso_ave, pred_lasso_train_ave)
実行結果
0.34380739431106944 0.3605698175652248特に予測精度が落ちたということはないですが、時と場合によるのかもしれません。
とりあえずグラフ表示をしてみましょう。
<セル9 max_iter=10, tol=1e-1>
fig=plt.figure(figsize=(8,6))
plt.clf()
plt.scatter(y_test_ori, pred_lasso_ori)
plt.scatter(y_test, pred_lasso)
実行結果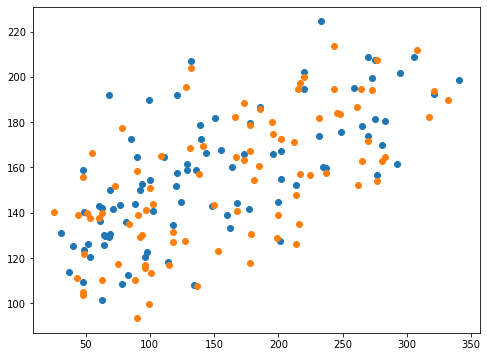
グラフからもオプションなし(青点)と「max_iter=10、tol=1e-1」を指定したデータ(橙点)ではあまり差がないように見えます。
次はmax_iter=10、tol=1e-10として、精度を求めるのに、試行回数を抑えたモデルを試してみます。
<セル8 max_iter=10, tol=1e-10>
trial = 100
pred_lasso_score = []; pred_lasso_train_score = []
for i in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_lasso = Lasso(max_iter=10, tol=1e-10)
model_lasso.fit(x_train, y_train)
pred_lasso = model_lasso.predict(x_test)
pred_lasso_score.append(r2_score(y_test, pred_lasso))
pred_lasso_train = model_lasso.predict(x_train)
pred_lasso_train_score.append(r2_score(y_train, pred_lasso_train))
pred_lasso_ave = np.average(np.array(pred_lasso_score))
pred_lasso_train_ave = np.average(np.array(pred_lasso_train_score))
print(pred_lasso_ave, pred_lasso_train_ave)
実行結果
/opt/anaconda3/lib/python3.7/site-packages/sklearn/linear_model/_coordinate_descent.py:531: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Duality gap: 0.09175244462676346, tolerance: 0.00021715330594900846
positive)
/opt/anaconda3/lib/python3.7/site-packages/sklearn/linear_model/_coordinate_descent.py:531: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Duality gap: 0.9634376938920468, tolerance: 0.0002131064266288952
positive)
/opt/anaconda3/lib/python3.7/site-packages/sklearn/linear_model/_coordinate_descent.py:531: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Duality gap: 0.1916793768759817, tolerance: 0.00019753652067988669
(以下略)警告がいっぱい出てきました。
中身を読んでみると、試行回数が全然足りていないから、増やした方がいいぞという警告のようです。
それでは試行回数を100000増やして試してみましょう。
<セル8 max_iter=100000, tol=1e-10>
trial = 100
pred_lasso_score = []; pred_lasso_train_score = []
for i in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_lasso = Lasso(max_iter=100000, tol=1e-10)
model_lasso.fit(x_train, y_train)
pred_lasso = model_lasso.predict(x_test)
pred_lasso_score.append(r2_score(y_test, pred_lasso))
pred_lasso_train = model_lasso.predict(x_train)
pred_lasso_train_score.append(r2_score(y_train, pred_lasso_train))
pred_lasso_ave = np.average(np.array(pred_lasso_score))
pred_lasso_train_ave = np.average(np.array(pred_lasso_train_score))
print(pred_lasso_ave, pred_lasso_train_ave)
実行結果
0.3378548740194407 0.3643436303614395今回は警告が出ずに計算終了できました。
こちらもグラフを表示してみましょう。
<セル9 max_iter=100000, tol=1e-10>
fig=plt.figure(figsize=(8,6))
plt.clf()
plt.scatter(y_test_ori, pred_lasso_ori)
plt.scatter(y_test, pred_lasso)
実行結果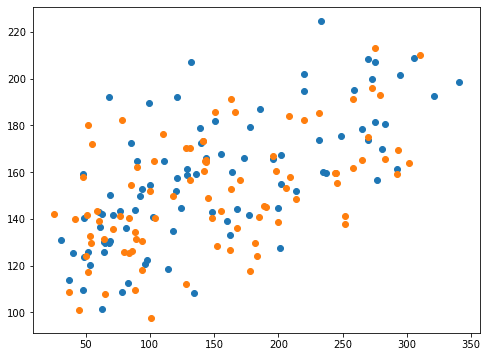
青点がオプションなし、橙点が「max_iter=100000, tol=1e-10」ですが、数値的にもグラフ的にもあまり変わったという感じはありません。
今回はあまり差が見られなかったですが、データによってはこのオプションを設定する必要が出てくるのかなと思います。
とりあえずLassoモデル特有で予想結果に影響のありそうなオプションはこんな感じだと思います。
次回はElasticNetのオプションを見ていきたいと思います。
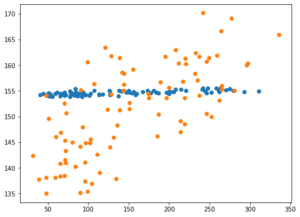
ではでは今回はこんな感じで。
コメント