機械学習ライブラリScikit-learn
前回、Matplotlibのimshowに関して解説を行いました。
今回からはScikit-learnの手書き数字のデータセットの機械学習を進めていきたいと思います。
と言っても、手書き数字のデータ、つまりは画像の機械学習になります。
そのため、これまでの数値の予想で使ってきた「回帰」とはまた違った機械学習モデルが必要になります。
ということで今回は手書き数字のデータを扱うのに、どの機械学習モデルを検討すべきか考えていきましょう。
アルゴリズム・チートシート
前に紹介した機械学習モデルのマップ「アルゴリズム・チートシート」から、手書き数字のデータセットに良さそうなモデルを探していきましょう。
ちなみに前の記事はこちらです。
良かったら、こちらも読んでみてください。
そしてアルゴリズム・チートシートはこちら。
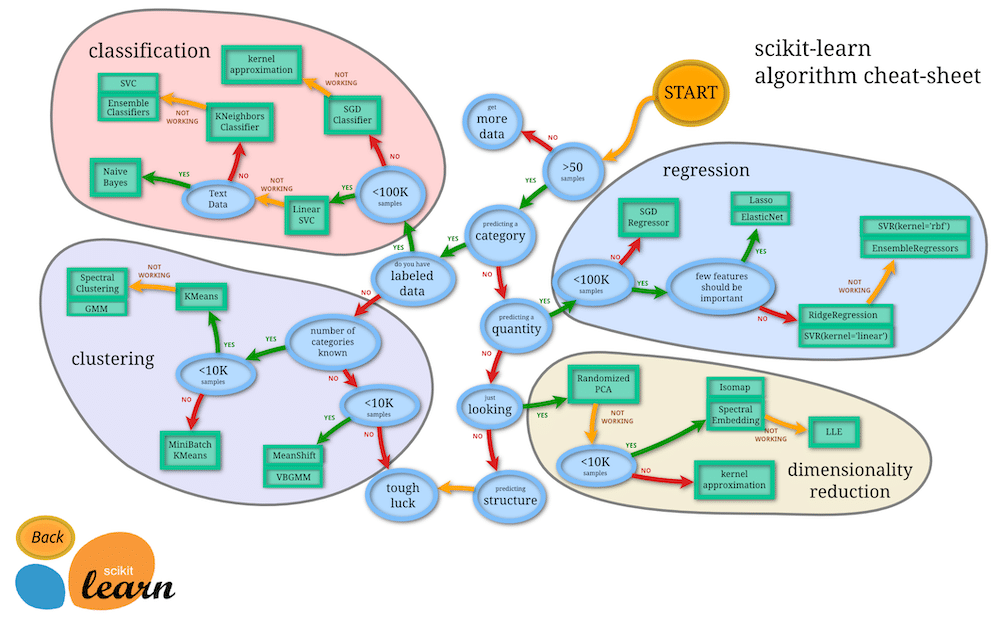
元の画像はこちらのサイトにあります。
「START」から順に見ていきましょう。
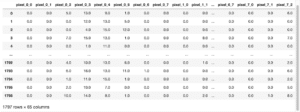
最初の質問は「50サンプルよりデータが多くあるかどうか」です。
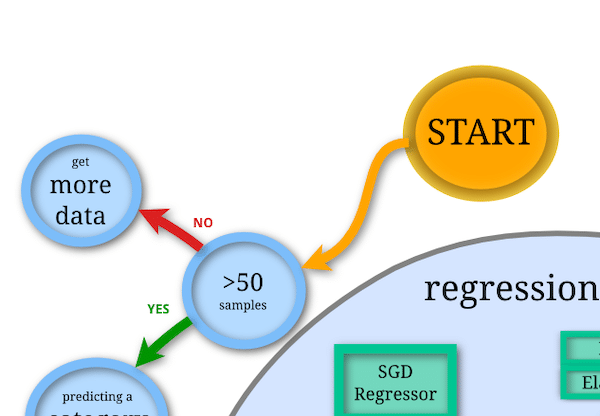
手書き数字のデータセットの中身を確認した際、データは1797個あったので、ここは「Yes」です。
次の質問は「カテゴリーを予想するものかどうか」です。
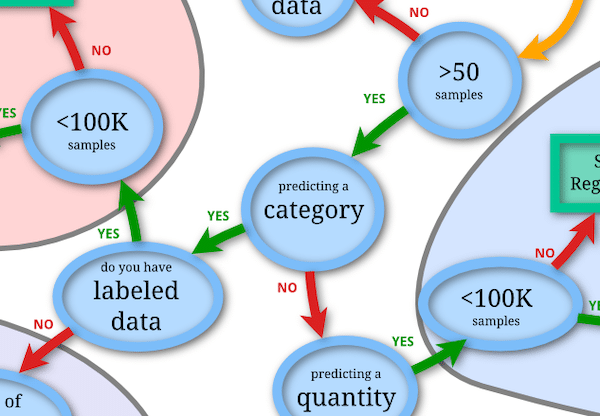
手書きで書かれた数字を0から9までの数字にカテゴリー化すると考えると「Yes」ですね。
次の質問は「ラベルされたデータがあるか」、つまり答えが分かっているデータを持っているかどうかということです。
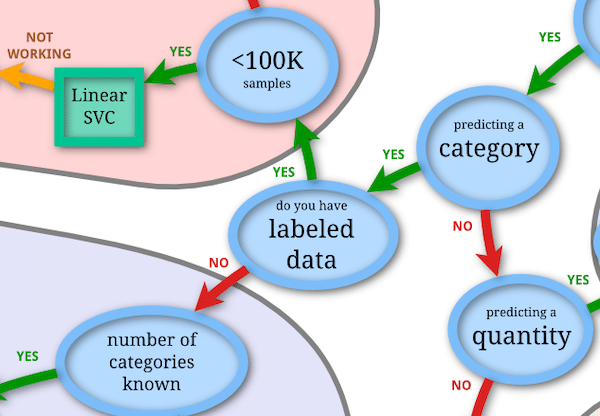
手書き数字のデータセットには答えも含まれているので「Yes」です。
そうしてたどり着いたのが「classification:分類」です。
Classification:分類
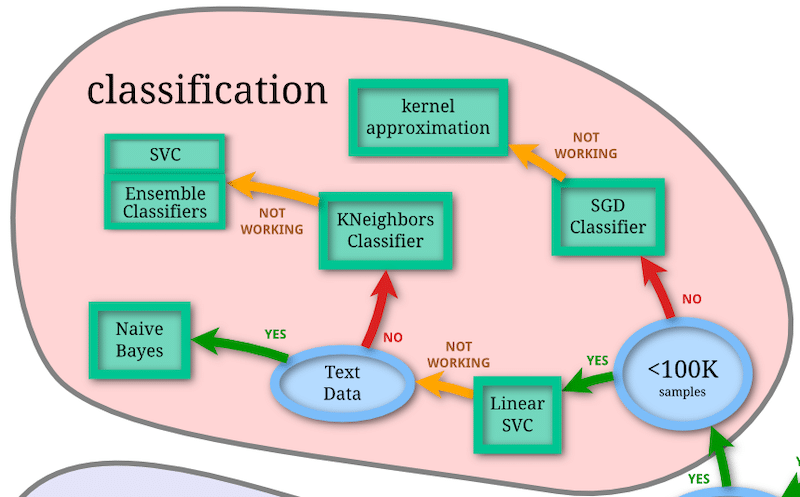
今度は「Classification:分類」の中を見ていきましょう。
最初は「データ数が100K(10万)より少ないかどうか」です。
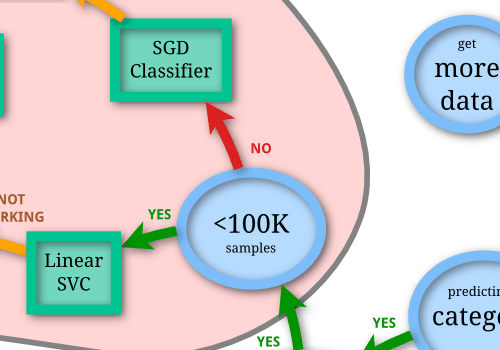
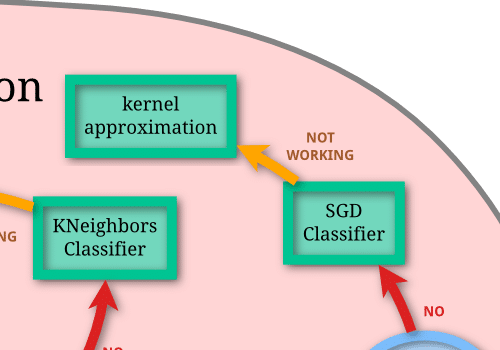
10万以上データがある場合は「No」に進み、「SGD Classifier」という機械学習モデルが第一候補となります。
また「SGD Classifier」でよい予想精度とならなかった場合、「kernel approximation」という機械学習モデルを試すという流れになるようです。
最初の分岐点で、逆にデータ数が10万以上ない場合は「Yes」に進み、「LinearSVC」 を試してみるのがいいようです。
そして「LinearSVC」で上手くいかなかった場合、テキストデータ(文章データということでしょう)なら「Naive Bayes」を試してみる。
テキストデータ出なければ、「KNeighbors Classifier」を試し、それでもダメなら「SVC」、「Ensemble Classifiers」を試すという流れになるようです。
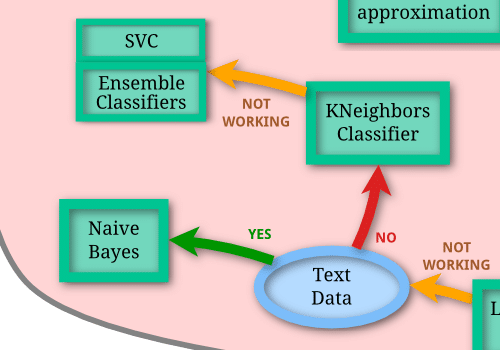
今回の手書き数字のデータセットでは、データ数は1797個なので、まずは「LinearSVC」を試し、ダメなら「KNeighbors Classifier」、さらにダメなら「SVC」、「Ensemble Classifier」を試すのが良さそうですね。
ということで次回は第一候補の「LinearSVC」を試してみることにしましょう。
ではでは今回はこんな感じで。
コメント