機械学習ライブラリScikit-learn
前回、前々回はちょっと寄り道してMatplotlibで円グラフを表示する方法を解説しました。
今回から再度、機械学習ライブラリScikit-learnに戻り、新しいデータセットに挑戦していこうと思います。
ということで今回から「手書き数字」のデータセットをいじっていきましょう。
「手書き数字」ということは、そう!待ちに待った画像を使った機械学習です。
画像を使った機械学習ができるようになれば、例えば写真で自分が写っている写真を抽出したり、表情から気分を予想したり、はたまた道端でとった花の写真から名前を予想するなんてことができるようになるんじゃないかと思います。
ということでその第一歩の「手書き数字」のデータセット。
今回はデータセットの中身を確認していくことにしましょう。
手書き数字のデータセット
今回から使っていく「手書き数字」のデータセットもScikit-learn内に含まれているデータセットです。
ということでいつものように読み込んでみましょう。
from sklearn.datasets import load_digits
digits = load_digits()
print(digits.keys())
実行結果
dict_keys(['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR'])このデータセットの中には、data、target、frame、feature_names、target_names、images、DESCRが含まれています。
これまでのデータセット同様、DESCRが解説書になるので、まずはこちらを開いてみます。
print(digits.DESCR)
実行結果
.. _digits_dataset:
Optical recognition of handwritten digits dataset
--------------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 5620
:Number of Attributes: 64
:Attribute Information: 8x8 image of integer pixels in the range 0..16.
:Missing Attribute Values: None
:Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)
:Date: July; 1998
This is a copy of the test set of the UCI ML hand-written digits datasets
https://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
The data set contains images of hand-written digits: 10 classes where
each class refers to a digit.
Preprocessing programs made available by NIST were used to extract
normalized bitmaps of handwritten digits from a preprinted form. From a
total of 43 people, 30 contributed to the training set and different 13
to the test set. 32x32 bitmaps are divided into nonoverlapping blocks of
4x4 and the number of on pixels are counted in each block. This generates
an input matrix of 8x8 where each element is an integer in the range
0..16. This reduces dimensionality and gives invariance to small
distortions.
(以下略)データセットの解説文の中で重要そうなところだけ抜き出してみました。
「Number of Instances: 5620」:実例が5620件
「Number of Attributes: 64」:特徴量の数が64個
「Attribute Information: 8×8 image of integer pixels in the range 0..16.」:特徴量の情報で、8x8ピクセルのイメージでそれぞれのピクセルの色の濃さが16段階で格納されている。
「Missing Attribute Values: None」:欠損値はなし。
こうみると画像そのものを使うというよりも、画像を数値データに置き換えたものを使うという感じですね。
(もちろん写真がデジタルデータとしパソコン何に存在するので、絶対に数値データなのですが、イメージ的にということで)
これだけでは感覚が掴めないので、データに関しても見ていきましょう。
data
まずは「data」から。
こちらにはその名の通り、データが格納されていることでしょう。
どんなデータが可能されているのか確認してみましょう。
print(digits.data)
実行結果
[[ 0. 0. 5. ... 0. 0. 0.]
[ 0. 0. 0. ... 10. 0. 0.]
[ 0. 0. 0. ... 16. 9. 0.]
...
[ 0. 0. 1. ... 6. 0. 0.]
[ 0. 0. 2. ... 12. 0. 0.]
[ 0. 0. 10. ... 12. 1. 0.]]リスト形式でいくつかの例が格納されているようです。
幾つのデータが格納されているのか確認してみます。
print(len(digits.data))
実行結果
1797データが1797個格納されているようですが、「Number of Instances: 5620」と数が合いません。
ミスなのでしょうか?
とりあえず一つデータを見てみましょう。
print(digits.data[0])
print(len(digits.data[0]))
実行結果
[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3.
15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0.
0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12.
0. 0. 0. 0. 6. 13. 10. 0. 0. 0.]
64一つのデータには64個の数字が含まれています。
これが先ほどの「Number of Attributes: 64」、つまり特徴量ということです。
target
次は「target」を見てみましょう。
print(digits.target)
実行結果
[0 1 2 ... 8 9 8]targetには数字がリスト形式で格納されているようです。
このリストに含まれる要素の数をカウントしてみます。
print(len(digits.target))
実行結果
1797先ほどのdataに含まれるデータの数と一致します。
つまり、dataに含まれるデータの答えがtargetというわけです。
frame
次は「frame」です。
名前からはどんなデータなのか分かりませんが、とりあえず表示してみましょう。
print(digits.frame)
実行結果
None何も入っていない…そんなことあるのでしょうか。
こういう時はSci-kit learnの公式ウェブサイトを確認するに限ります。
frame: DataFrame of shape (1797, 65)
Only present when
as_frame=True. DataFrame withdataandtarget.New in version 0.23.
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html
どうやらPandasのデータフレーム形式でdigits.dataが格納されているようです。
しかしデータセットを読み込む際に「as_frame=True」というオプションが必要とのこと。
from sklearn.datasets import load_digits
digits = load_digits(as_frame=True)
digits.frame
実行結果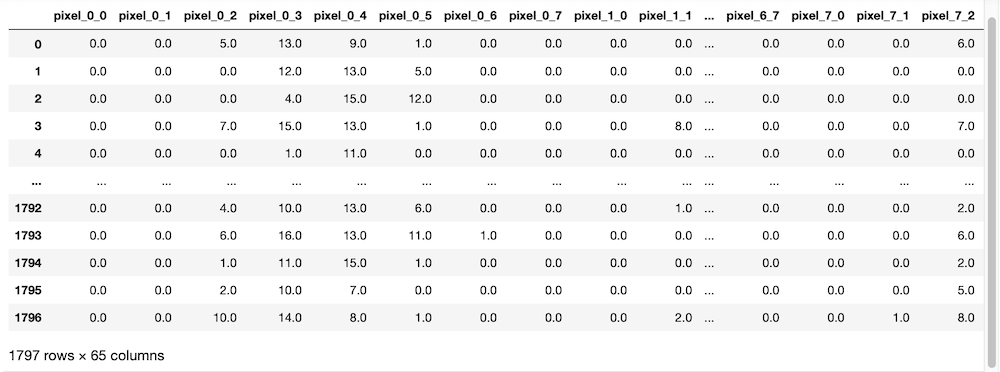
今度は確かにデータフレーム形式で表示されました。
feature_names, target_names
次はfeature_namesとtarget_namesの二つを一緒に見ていきましょう。
print(digits.feature_names)
実行結果
['pixel_0_0', 'pixel_0_1', 'pixel_0_2', 'pixel_0_3', 'pixel_0_4', 'pixel_0_5', 'pixel_0_6', 'pixel_0_7', 'pixel_1_0', 'pixel_1_1', 'pixel_1_2', 'pixel_1_3', 'pixel_1_4', 'pixel_1_5', 'pixel_1_6', 'pixel_1_7', 'pixel_2_0', 'pixel_2_1', 'pixel_2_2', 'pixel_2_3', 'pixel_2_4', 'pixel_2_5', 'pixel_2_6', 'pixel_2_7', 'pixel_3_0', 'pixel_3_1', 'pixel_3_2', 'pixel_3_3', 'pixel_3_4', 'pixel_3_5', 'pixel_3_6', 'pixel_3_7', 'pixel_4_0', 'pixel_4_1', 'pixel_4_2', 'pixel_4_3', 'pixel_4_4', 'pixel_4_5', 'pixel_4_6', 'pixel_4_7', 'pixel_5_0', 'pixel_5_1', 'pixel_5_2', 'pixel_5_3', 'pixel_5_4', 'pixel_5_5', 'pixel_5_6', 'pixel_5_7', 'pixel_6_0', 'pixel_6_1', 'pixel_6_2', 'pixel_6_3', 'pixel_6_4', 'pixel_6_5', 'pixel_6_6', 'pixel_6_7', 'pixel_7_0', 'pixel_7_1', 'pixel_7_2', 'pixel_7_3', 'pixel_7_4', 'pixel_7_5', 'pixel_7_6', 'pixel_7_7']feature_namesには特徴量の名前、今回は画像データとしてのピクセルの場所を名前として用いているようです。
print(digits.target_names)
実行結果
[0 1 2 3 4 5 6 7 8 9]target_namesには答えなので、0〜9までの数字が格納されています。
つまり8x8の画像データが0〜9のうちどの数値のことか機械学習で読み取るということですね。
images
DESCRは最初に解説したので、次のimagesが最後です。
こちらもまずは表示してみましょう。
print(digits.images)
実行結果
[[[ 0. 0. 5. ... 1. 0. 0.]
[ 0. 0. 13. ... 15. 5. 0.]
[ 0. 3. 15. ... 11. 8. 0.]
...
[ 0. 4. 11. ... 12. 7. 0.]
[ 0. 2. 14. ... 12. 0. 0.]
[ 0. 0. 6. ... 0. 0. 0.]]
[[ 0. 0. 0. ... 5. 0. 0.]
[ 0. 0. 0. ... 9. 0. 0.]
[ 0. 0. 3. ... 6. 0. 0.]
...
(以下略)また数字のリストが出てきました。
要素数を確認してみましょう。
print(len(digits.images))
実行結果
1797どうやらdataやtargetと同じ要素数のようです。
imagesの最初のリストの中身を確認してみます。
print(digits.images[0])
実行結果
[[ 0. 0. 5. 13. 9. 1. 0. 0.]
[ 0. 0. 13. 15. 10. 15. 5. 0.]
[ 0. 3. 15. 2. 0. 11. 8. 0.]
[ 0. 4. 12. 0. 0. 8. 8. 0.]
[ 0. 5. 8. 0. 0. 9. 8. 0.]
[ 0. 4. 11. 0. 1. 12. 7. 0.]
[ 0. 2. 14. 5. 10. 12. 0. 0.]
[ 0. 0. 6. 13. 10. 0. 0. 0.]]どこかでこの数字の羅列をみたような気がしませんか?
そう、dataの一番最初のリストを表示させた時にみた気がします。
ということでもう一度dataの最初のリストを見てみましょう。
print(digits.data[0])
実行結果
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
2645 try:
-> 2646 return self._engine.get_loc(key)
2647 except KeyError:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 0
(以下略)なぜかエラーになってしまいました。
実はさっきframeをTrueにしたことが影響していました。
つまり「as_frame=True」とするとdataとtargetもリスト形式ではなく、データフレーム形式になってしまうため、リスト形式で呼び出そうとするとエラーになるということです。
ということで確認。
from sklearn.datasets import load_digits
digits = load_digits()
print(digits.data[0])
実行結果
[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3.
15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0.
0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12.
0. 0. 0. 0. 6. 13. 10. 0. 0. 0.]先ほどの「digits.images[0]」と比べてみると確かに一致しています。
つまりimagesにはピクセルの位置を2次元リストとして格納しているというわけです。
これで中身の確認は終わりました。
しかし手書き数字のデータセットなのに、今回は画像が出てきませんでした。
先ほどimagesをみた通り、画像データは数値データに変換されてしまっているのです。
ということで次回はせっかくなので、数値データから画像を表示してみるということをやってみましょう。

ではでは今回はこんな感じで。
コメント