DX(デジタルトランスフォーメーション)
前回、個人でDXやろうぜってことで、Pythonのインストールに関してお話ししました。
今回はなんちゃってDX初のプログラムということで、皆さんがよく使う表(テーブル)のためのプログラムを作ってみました。
ということでまずはどういうプログラムかを見ていきましょう。
このプログラムでできること
今回のプログラムでできることは「CSVファイルの列を抽出すること」です。
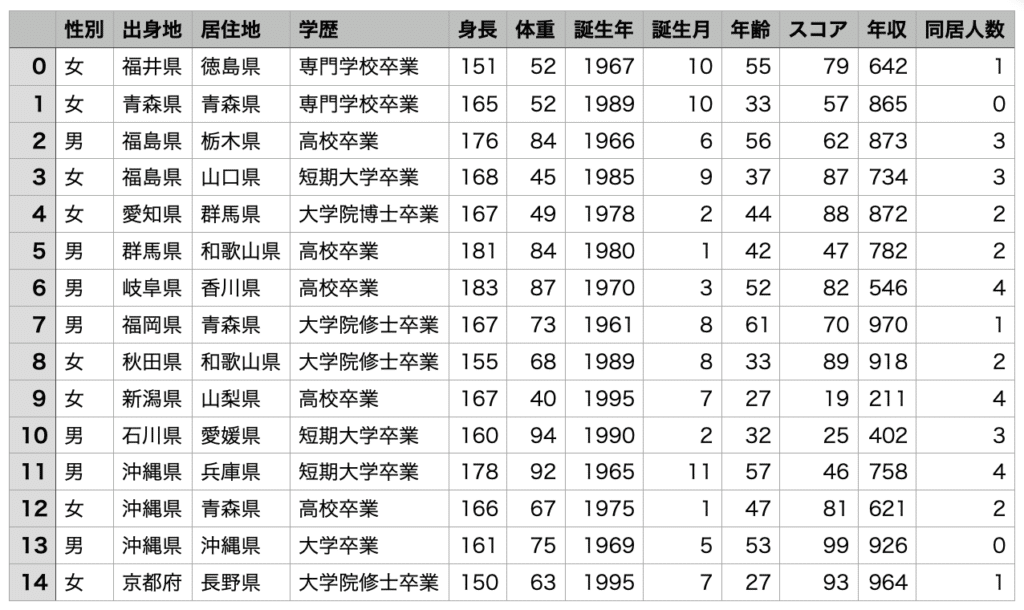
つまりこんな感じの表があった時に。。。(CSVファイルなのでテキストエディタで開くとカンマ区切りです)
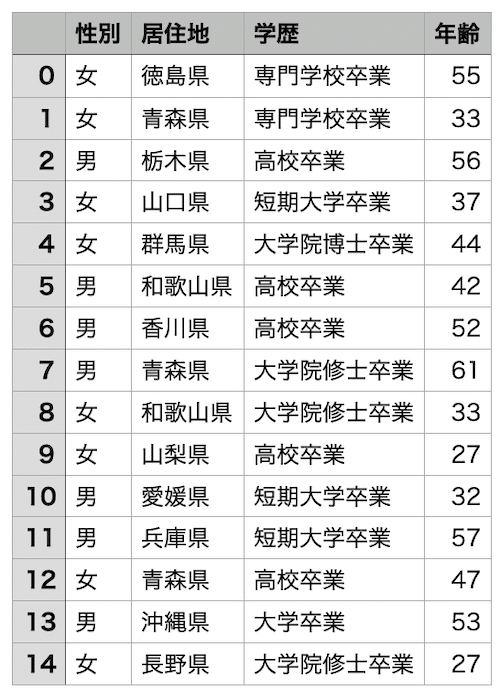
指定した列だけこうやって抽出するプログラムです。
こんなの別にエクセルで一列ずつ消していくとか、必要な項目だけ新しいシートにコピーするとかでいいじゃんという声も聞こえてきそうです。
でも列数が膨大にあったらどうしますか?
同じようなファイルが何十、何百もあったらどうしますか?
そんな時に便利かなと思って作ってみました。
使い方
まず外部ライブラリ(先に別途インストールが必要なプログラム)で「pandas」を使用するので、Macの方はターミナル、Windowsの方はコマンドプロンプトで下のコマンドを実行してください。
pip install pandasインストールが完了したら、こちらのファイルをダウンロードして、展開してください。
展開すると「dx-1_ExtractDataByHeader_CSV.py」というファイルが出てきます。
この「dx-1_ExtractDataByHeader_CSV.py」と、処理したいファイル(下の例ではdx-1_Data1.csv、dx-1_Data2.csv、dx-1_Data3.csv)を同じフォルダに入れてください。
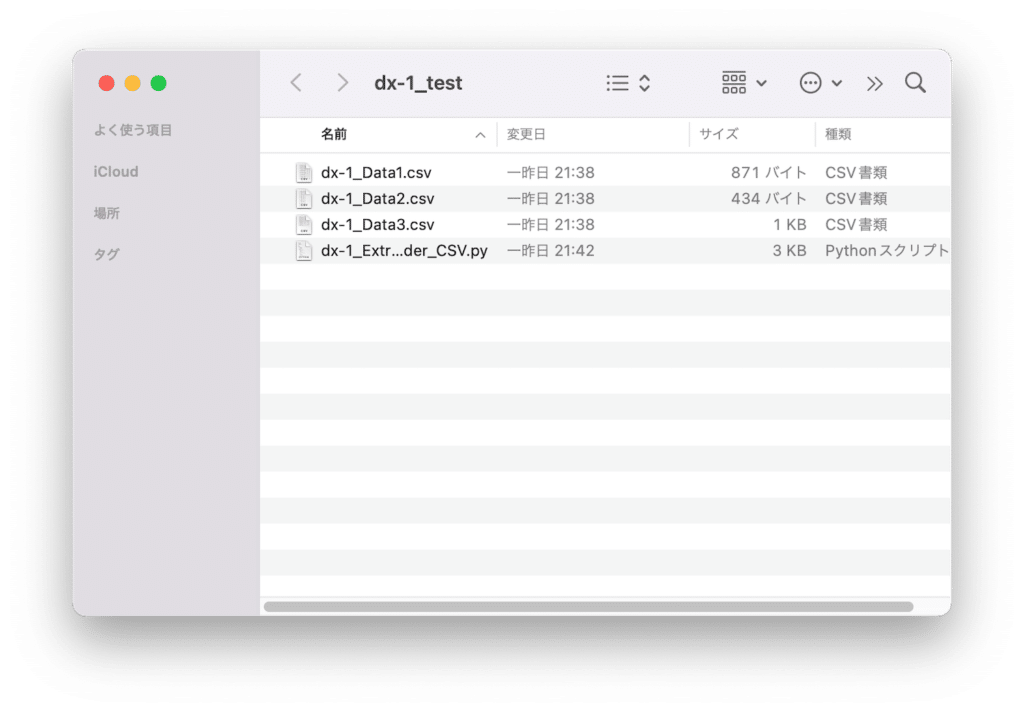
処理したいファイルの名前に制限があり、ファイル名の最初に「dx-1_」をつけてください。
「dx-1_」付いていないと処理されません。
準備ができたら、「dx-1_ExtractDataByHeader_CSV.py」を実行します。
ダブルクリックで実行してもいいですし、ターミナルやコマンドプロンプトからこちらのコマンドを実行してもいいです。
python dx-1_ExtractDataByHeader_CSV.py実行するとこんな感じになります。
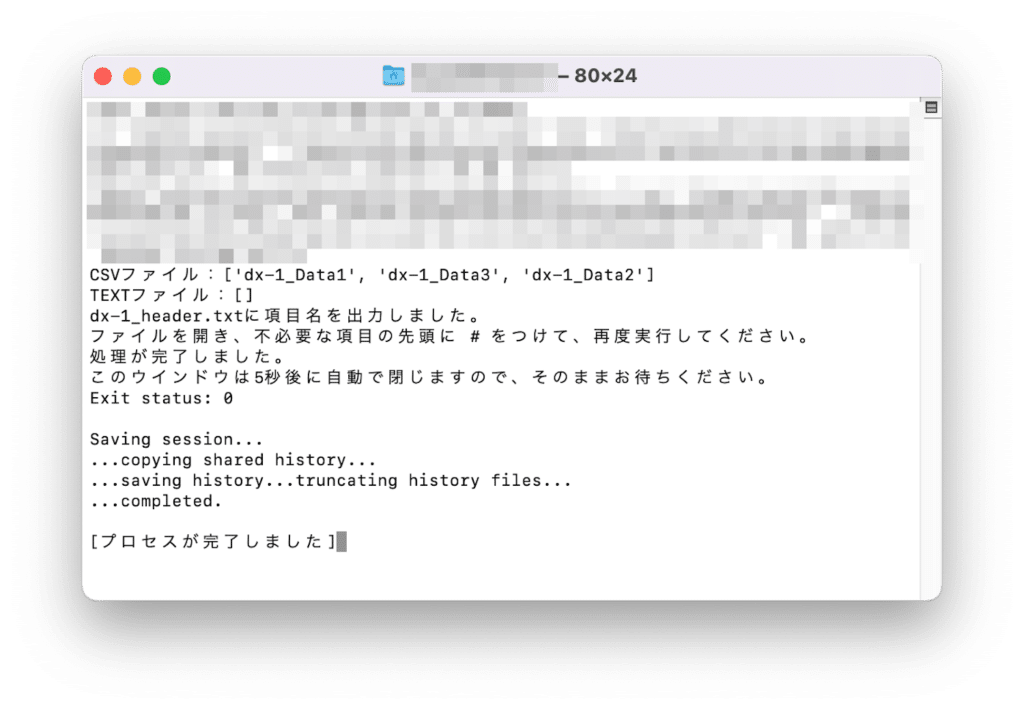
ちなみに「このウインドウは5秒後に自動で閉じますので、そのままお待ちください。」とありますが、Macでは自動で閉じないようです。
ここら辺はご愛嬌ということで、各自で閉じてください。
次は「dx-1_header.txt」というファイルが作成されているので、テキストエディタで開きます。

開くと読み込んだCSVファイルの列名が縦に並んでいます。
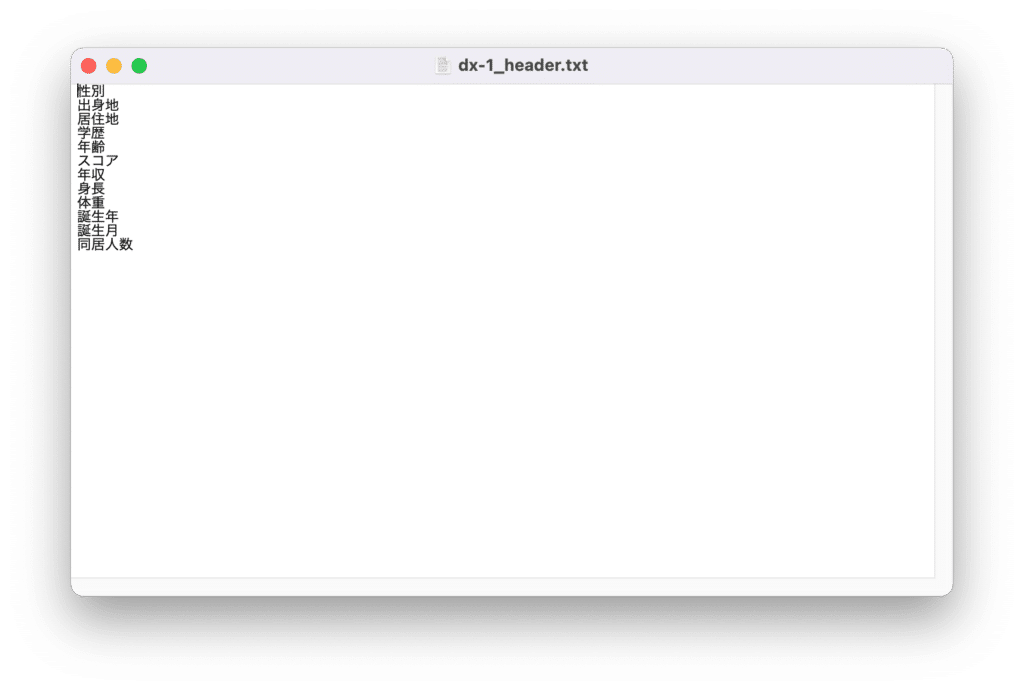
出力しない項目の先頭に「#」をつけて、保存します。
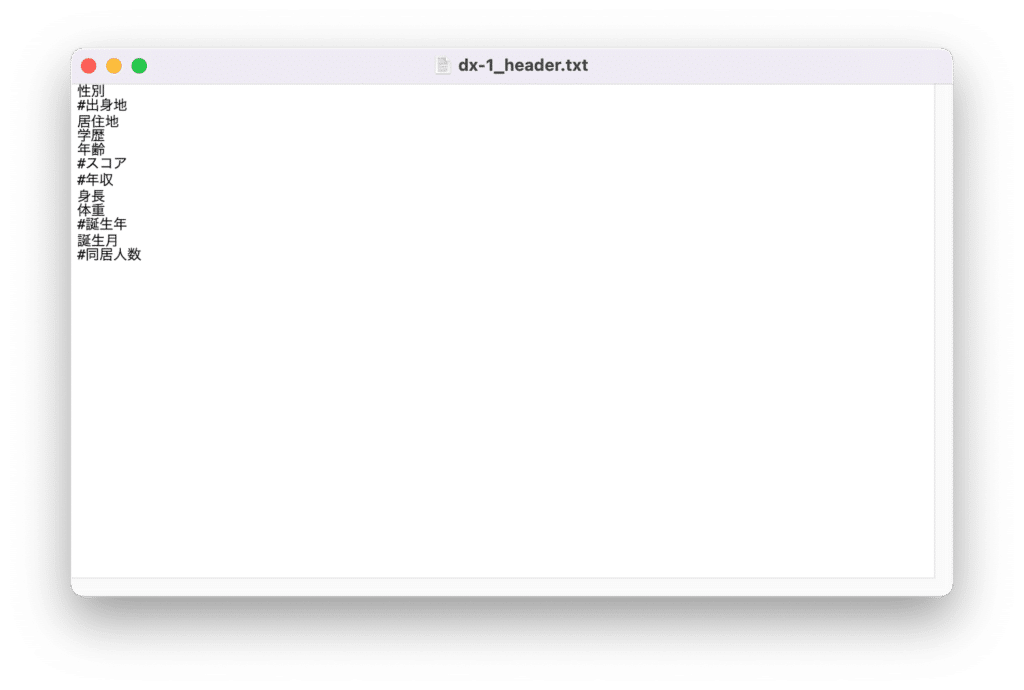
保存したら、「dx-1_ExtractDataByHeader_CSV.py」を再度実行します。
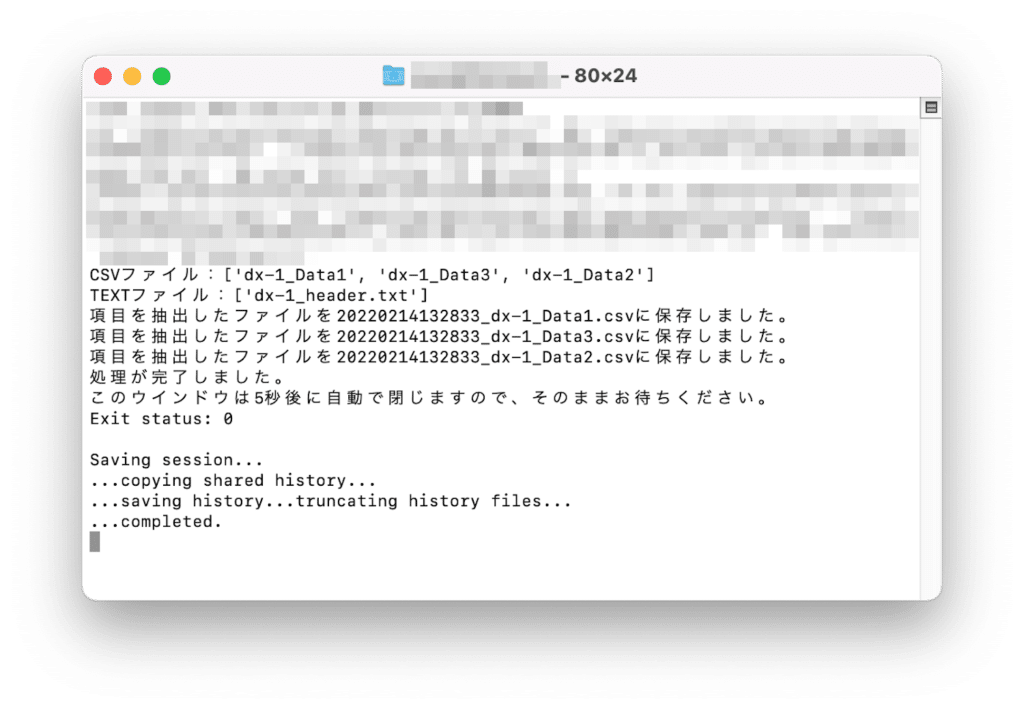
すると処理したファイルの数だけ新しいファイルが生成されます。
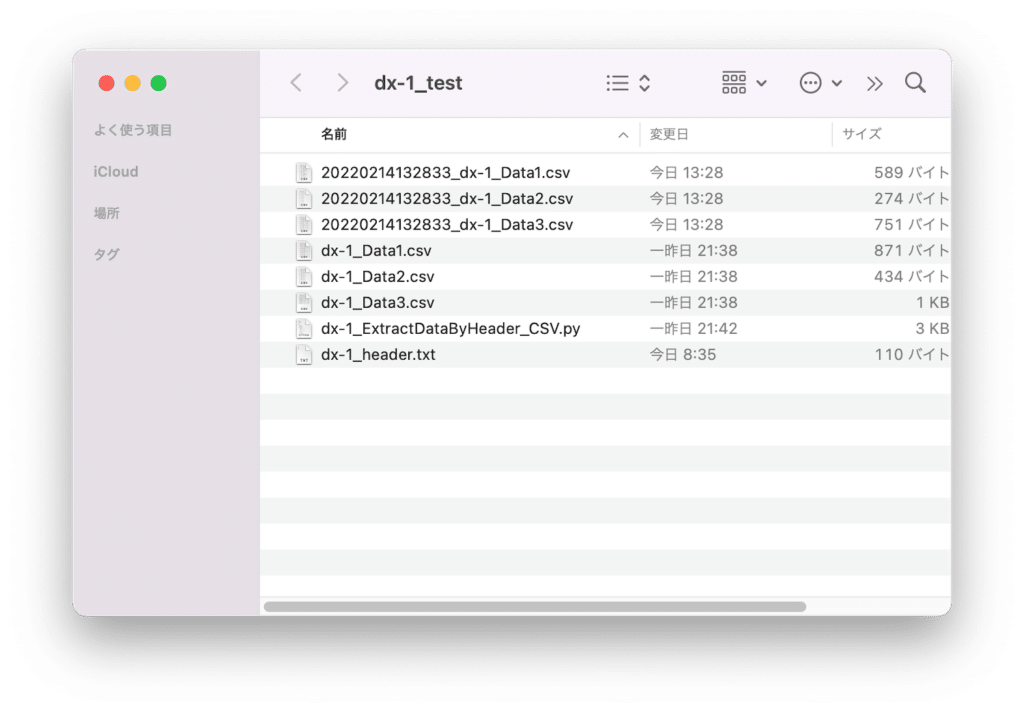
生成されたファイルの中身はこんな感じで、抽出されたデータです。
ちなみに列の項目名は同時に処理するファイル全てをまとめたものになります。
そのため、ファイルによっては抽出を選択した項目がない場合もありますが、その場合は単にその項目がスキップされます。
プログラムの解説
プログラム全体
それではプログラムの解説をしていきます。
プログラム全体としてはこんな感じです。
import os
import datetime
import time
import pandas as pd
def filenameGet():
csv_list = []; text_list =[]
for filename in os.listdir('./'):
if filename.startswith('dx-1_'):
if filename.endswith('.csv'):
csv_list.append(filename[:-4])
elif filename == 'dx-1_header.txt':
text_list.append(filename)
return csv_list, text_list
def fileProcess(csv_list, text_list, timenow):
if 'dx-1_header.txt' in os.listdir('./'):
extractkey_list = []
with open('./dx-1_header.txt', 'r') as f_in:
for row in f_in:
if not row.startswith('#'):
extractkey_list.append(row.replace('\n',''))
for csv in csv_list:
df = pd.read_csv(f'./{csv}.csv', encoding='utf-8', index_col=0)
df_new = pd.DataFrame()
for key in extractkey_list:
if key in df.keys():
df_new[key] = df[key]
output_filename = f'{timenow}_{csv}.csv'
df_new.to_csv(f'./{output_filename}', encoding='utf-8')
print(f'項目を抽出したファイルを{output_filename}に保存しました。')
else:
key_list = []
for csv in csv_list:
df = pd.read_csv(f'./{csv}.csv', encoding='utf-8', index_col=0)
for key in df.keys():
if not key in key_list:
key_list.append(key)
with open('dx-1_header.txt', 'w') as f_out:
for key in key_list:
f_out.write(f'{key}\n')
print('dx-1_header.txtに項目名を出力しました。')
print('ファイルを開き、不必要な項目の先頭に # をつけて、再度実行してください。')
def main():
timenow = timenow = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
csv_list, text_list = filenameGet()
print(f'CSVファイル:{csv_list}')
print(f'TEXTファイル:{text_list}')
fileProcess(csv_list, text_list, timenow)
print('処理が完了しました。')
print('このウインドウは5秒後に自動で閉じますので、そのままお待ちください。')
print('もし閉じない場合は、手動で閉じてください。')
time.sleep(5)
if __name__ == '__main__':
main()ライブラリのインポート
今回使用するライブラリは「os」、「datetime」、「time」、「pandas」です。
import os
import datetime
import time
import pandas as pd「pandas」だけは外部ライブラリなので、使用する前にインストールが必要です。
pip install pandasfilenameGet関数
処理するファイルのファイル名を取得するための関数です。
def filenameGet():
csv_list = []; text_list =[]
for filename in os.listdir('./'):
if filename.startswith('dx-1_'):
if filename.endswith('.csv'):
csv_list.append(filename[:-4])
elif filename == 'dx-1_header.txt':
text_list.append(filename)
return csv_list, text_listこの関数で取得するファイルは主に2種類。
一つ目は処理するファイルで、ファイル名の先頭に「dx-1_」、拡張子が「.csv」のファイルのファイル名を取得します。(それぞれ「if filename.startswith(‘dx-1_’):」と「if filename.endswith(‘.csv’):」)
二つ目は1回目の実行で生成される項目名が記載されているファイル(dx-1_header.txt)があれば、ファイル名を取得します。(「elif filename == ‘dx-1_header.txt’:」)
これらをリストに格納して、この関数の実行結果として返します。
fileProcess関数
ファイルを処理するための関数です。
前半と後半で処理の目的が大きく異なるので、別々に見ていきましょう。
fileProcess関数 前半:データの抽出と保存
fileProcess関数の前半は「dx-1_header.txt」から出力する項目を取得し、それぞれのCSVファイルを処理する部分です。
if 'dx-1_header.txt' in os.listdir('./'):
extractkey_list = []
with open('./dx-1_header.txt', 'r') as f_in:
for row in f_in:
if not row.startswith('#'):
extractkey_list.append(row.replace('\n',''))
for csv in csv_list:
df = pd.read_csv(f'./{csv}.csv', encoding='utf-8', index_col=0)
df_new = pd.DataFrame()
for key in extractkey_list:
if key in df.keys():
df_new[key] = df[key]
output_filename = f'{timenow}_{csv}.csv'
df_new.to_csv(f'./{output_filename}', encoding='utf-8')
print(f'項目を抽出したファイルを{output_filename}に保存しました。')最初に「dx-1_header.txt」があった場合として条件分岐をしています。(if ‘dx-1_header.txt’ in os.listdir(‘./’):)
その後、「dx-1_header.txt」を開きます。(with open(‘./dx-1_header.txt’, ‘r’) as f_in:)
先頭に「#」がない項目を抽出します。(if not row.startswith(‘#’):)
ただしこの際、それぞれの最後に改行コード(\n)がついているので削除し、リストに格納します。(extractkey_list.append(row.replace(‘\n’,”)))
次にCSVファイルの名前を一つずつ取得し、pandasのデータフレームとして読み込みます。(df = pd.read_csv(f’./{csv}.csv’, encoding=’utf-8′, index_col=0))
こうすることで「df.keys()」とするだけで、列名がリストとして取得可能になります。
同時に出力するためのデータフレームを作成します。(df_new = pd.DataFrame())
先ほど取得した抽出する項目のリスト(extractkey_list)を一つずつ取得し、さらに読み込んだCSVファイルの項目を一つずつ取得し、比較します。
同じ項目名があった場合のみ、出力用のデータフレームに列のデータをコピーします。(df_new[key] = df[key])
最後にデータフレームをCSVファイルとして出力します。(df_new.to_csv(f’./{output_filename}’, encoding=’utf-8′))
これで前半部分は終了です。
fileProcess関数 後半:項目ファイルの作成
fileProcess関数の後半は、項目ファイルである「dx-1_header.txt」を作成しています。
else:
key_list = []
for csv in csv_list:
df = pd.read_csv(f'./{csv}.csv', encoding='utf-8', index_col=0)
for key in df.keys():
if not key in key_list:
key_list.append(key)
with open('dx-1_header.txt', 'w') as f_out:
for key in key_list:
f_out.write(f'{key}\n')
print('dx-1_header.txtに項目名を出力しました。')
print('ファイルを開き、不必要な項目の先頭に # をつけて、再度実行してください。')こちらではfileProcess関数の前半部分で使用したコマンドばかりなので、多くは解説しません。
やっていることとしては、それぞれのCSVファイルを読み込み、列の項目名を抽出し、「dx-1_header.txt」に書き込んでいます。
main関数
main関数ではfilenameGet関数とfileProcess関数を実行しています。
def main():
timenow = timenow = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
csv_list, text_list = filenameGet()
print(f'CSVファイル:{csv_list}')
print(f'TEXTファイル:{text_list}')
fileProcess(csv_list, text_list, timenow)
print('処理が完了しました。')
print('このウインドウは5秒後に自動で閉じますので、そのままお待ちください。')
print('もし閉じない場合は、手動で閉じてください。')
time.sleep(5)
if __name__ == '__main__':
main()注意すべき点
注意すべき点としては、以下の通りです。
- 処理できるのはCSVファイルのみ
- WindowsとMacでは改行コード(Macでは「\n」)が違う可能性
ファイルとしては多くの方はエクセルファイルをお使いのことでしょう。
そのため、CSVファイルでしか処理できないのは、このプログラムの欠点かもしれません。
ちなみにエクセルファイルからCSVファイルへの変換方法はこちらの記事で解説しています。

エクセルファイルをCSVファイルに変換するプログラムなんかも今後作っていきたいものです。
改行コードはWindowsだと「\r\n」のようです。
もしWindowsお使いの方で、プログラムがうまく動かないという場合は、改行コード「\n」を「\r\n」に置換してみてください。
特に使えるかなと思うのは、インターネット上でダウンロードできる統計データです。
統計データは大量の列が含まれていて、見づらい場合もあるので、そんな時にこのプログラムがあると便利かなと思います。
良かったら、使ってみたり、いじってみたりしてください。
次回は、このプログラムを試すためのデータを作成したプログラムを紹介します。
ではでは今回はこんな感じで。
コメント