DX(デジタルトランスフォーメーション)
前回、Pythonで始めるなんちゃってDXのおまけとして、ヘッダーをもつデータをランダムで作るプログラムを紹介しました。
今回はそれぞれの行がタグづけされているデータを変換するプログラムを紹介します。
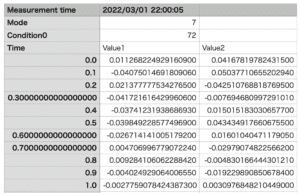
どういうデータかというと、前回のデータはこんな感じでした。
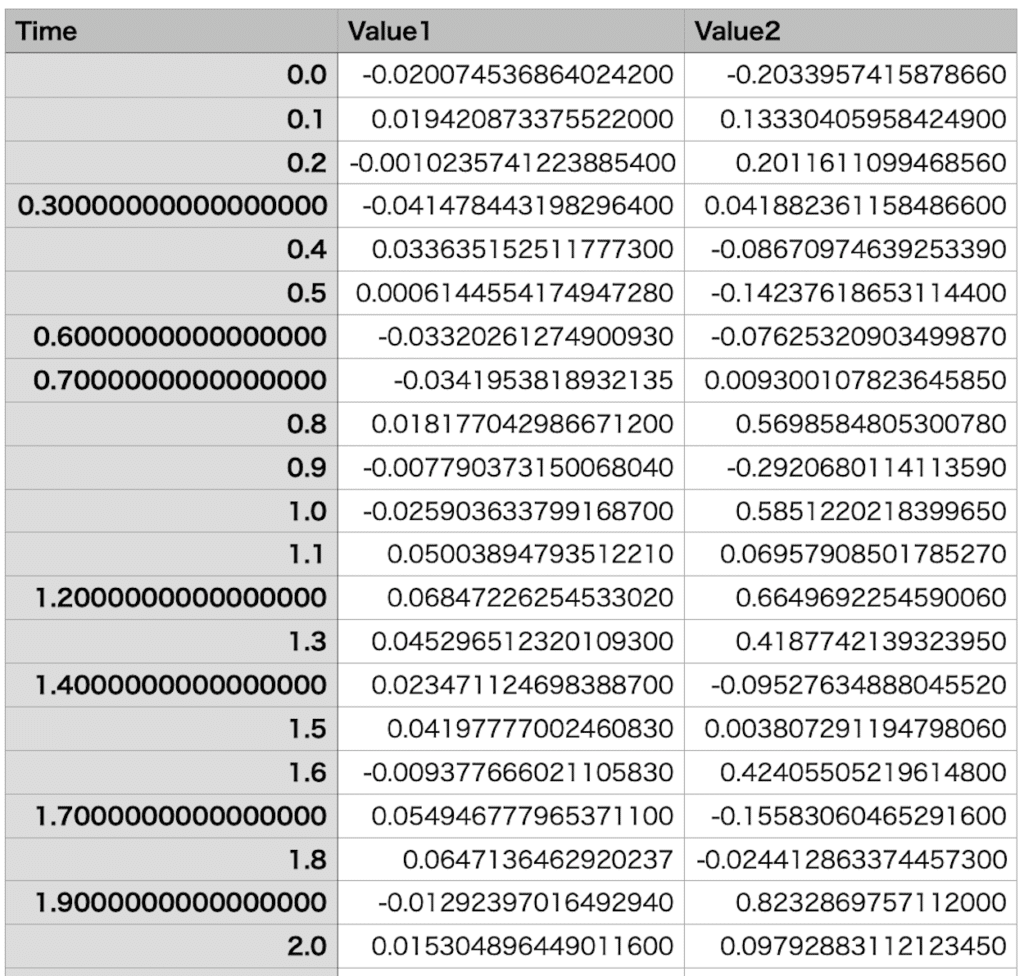
そして今回扱うデータはこんな感じです。
上の方はほぼ同じなのですが、数値データからは各列の名前の先頭に「Name」が、数値データの先頭に「Data」が付加されています。
計測器から出力されたデータはこういう形のものも結構あるので、今回はこのフォーマットのデータをグラフ変換プログラムで読み込めるよう変換するプログラムを作成していきましょう。
このプログラムでできること
このプログラムでできることは「付加情報が含まれていて、数値データがタグ付けされているCSVファイルから数値データを抜き出すこと」です。
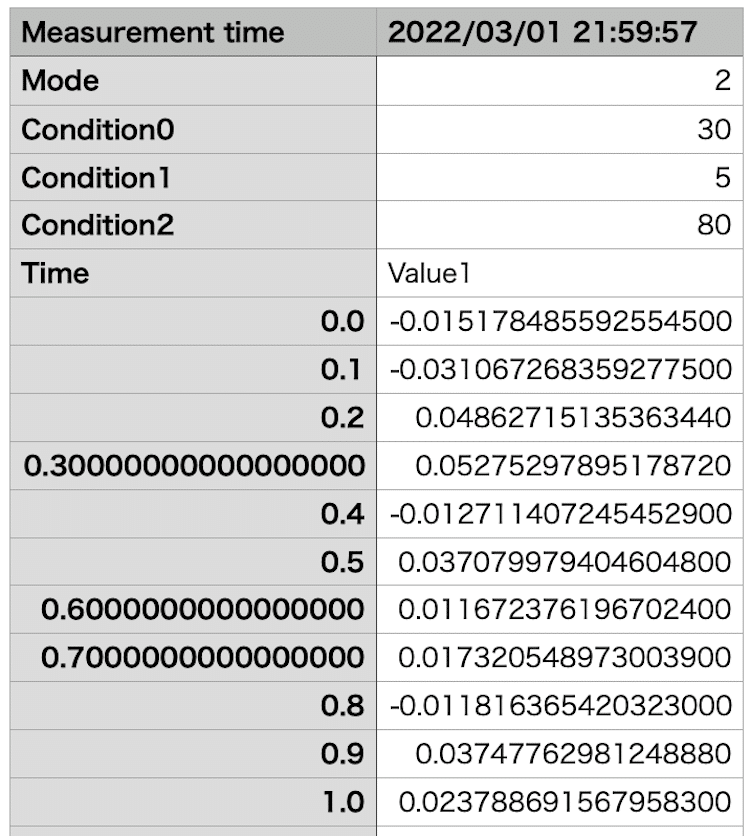
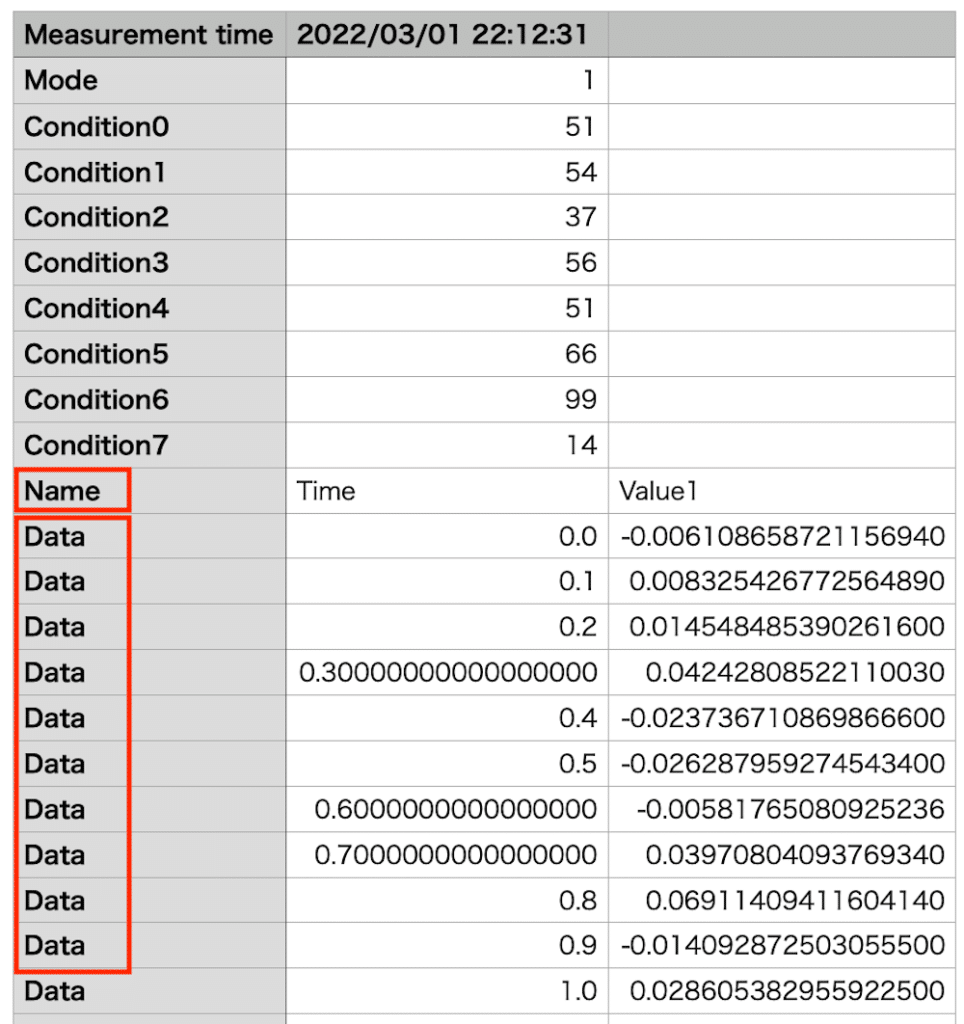
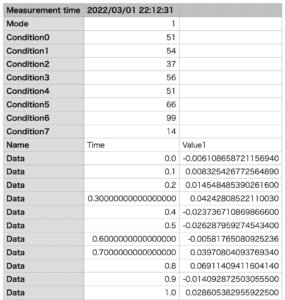
準備するデータはこんな感じです。
(CSVファイルなので、テキストエディタで開くとカンマ区切りです)
最初に「Measurement time」として測定日時があり、「Mode」とか「Condition」とかが付加的な情報(ここではダミーですが)です。
そしてグラフ作成に必要なデータとしては、「Name Time Value1」以降のデータになります。
ということで出てくるデータとしてはこんな感じです。
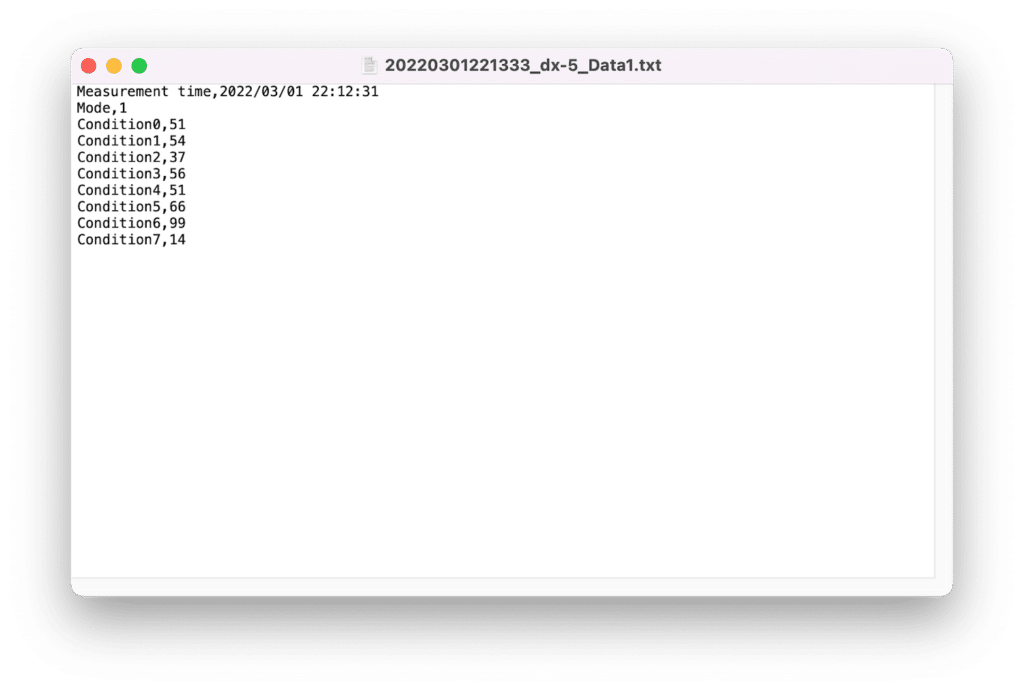
また前回同様、ヘッダー部分は別のファイルとして出力されます。
ここまでできれば、前に作成したグラフ作成プログラムに読み込ませ、グラフを表示することができるというわけです。
使い方
まずはこちらのファイルをダウンロードして、展開してください。
展開すると「dx-5_FileConvertor2.py」と「dx-5_settings.txt」というファイルが出てきます。
この二つのファイルを処理したいファイル(下の例ではdx-5_Data1.csvとdx-5_Data2.csv)と同じフォルダに置いてください。
次に「dx-5_settings.txt」を開きます。
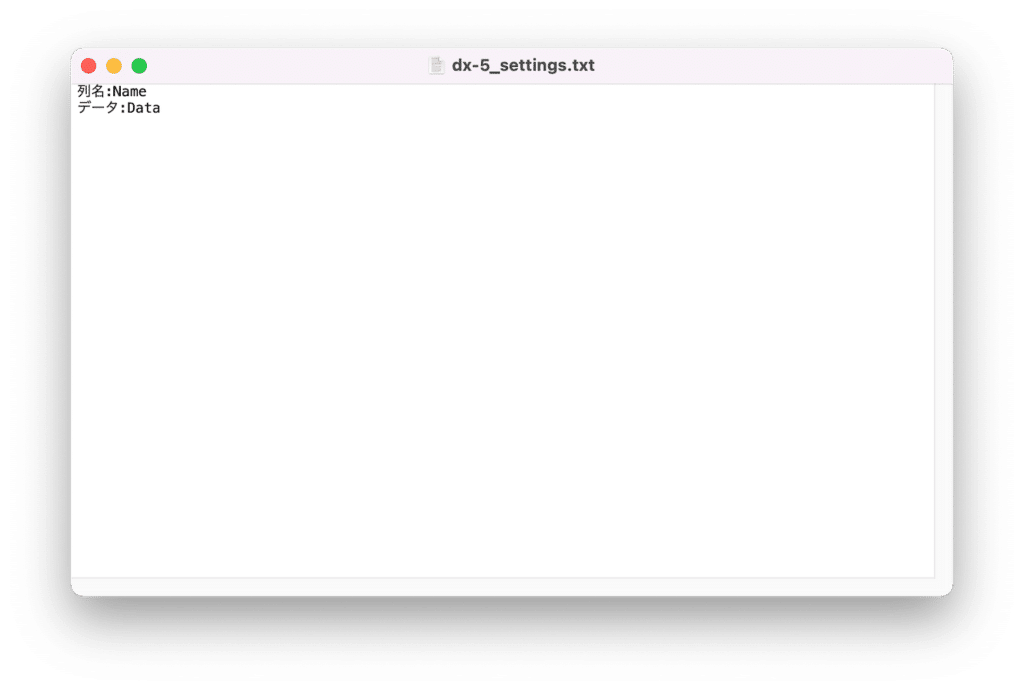
「列名:」の後ろに数値データの列名のタグを、「データ:」の後ろにデータ行のタグを入力します。
例えば下の例ではそれぞれ「Name」と「Data」になります。
これで設定は完了ですが、処理したいファイルの名前に制限があり、ファイル名の最初に「dx-5_」をつけてください。
「dx-5_」が付いていないと処理されません。
準備ができたら、「dx-5_FileConvertor2.py」を実行します。
ダブルクリックで実行してもいいですし、ターミナルやコマンドプロンプトからこちらのコマンドを実行してもいいです。
python dx-5_FileConvertor2.py実行するとこんな感じになります。
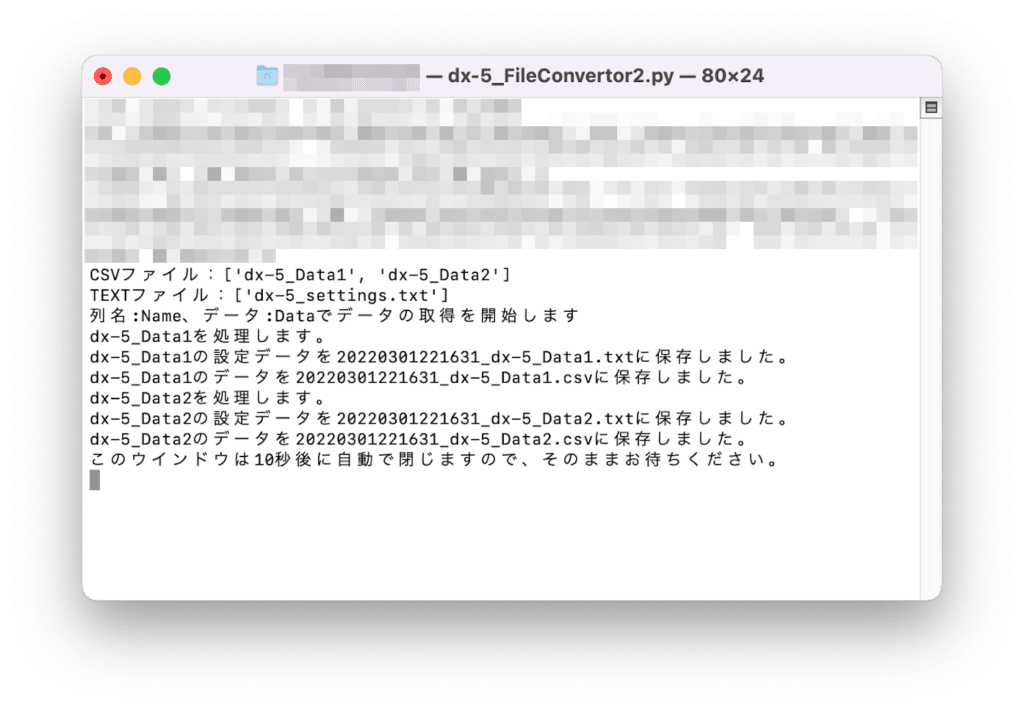
ちなみに「このウインドウは10秒後に自動で閉じますので、そのままお待ちください。」とありますが、Macでは自動で閉じないようです。
ここら辺はご愛嬌ということで、各自で閉じてください。
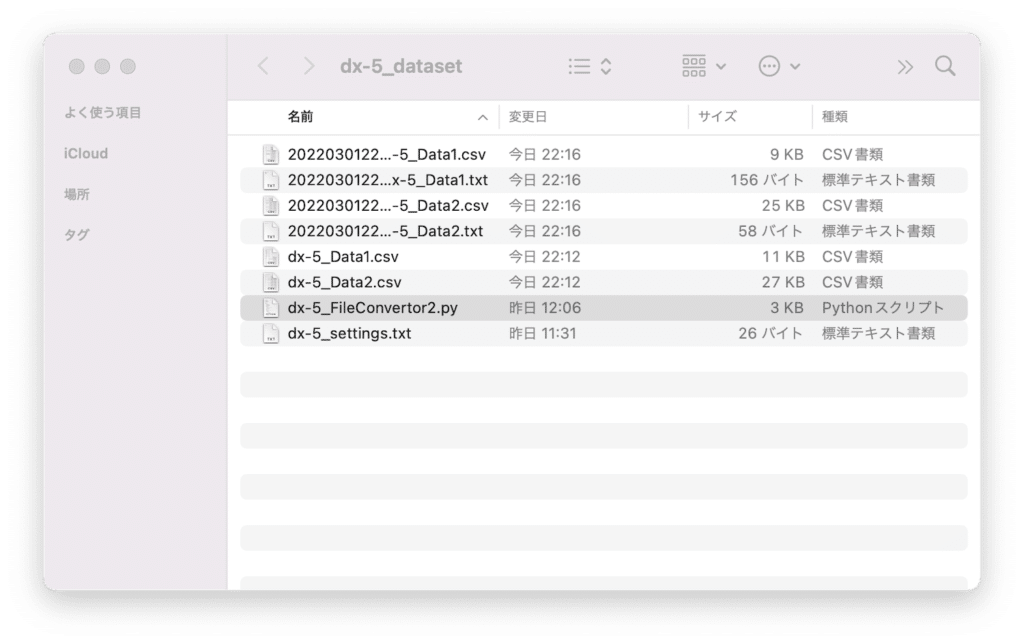
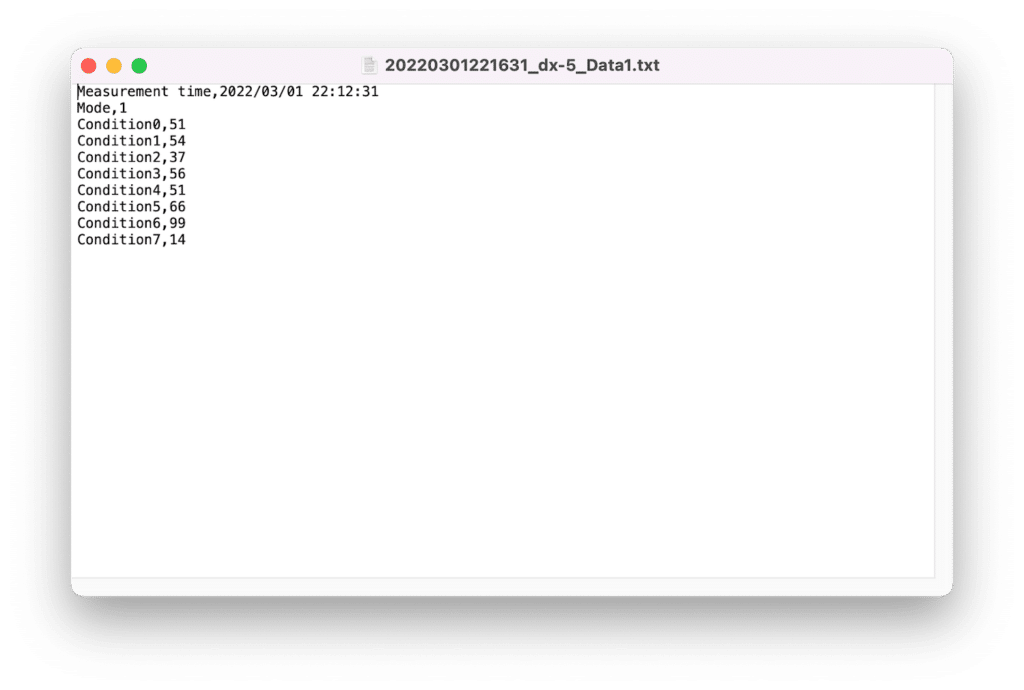
これで最初に同じフォルダに置いたデータそれぞれに対し、「日時_ファイル名.txt」と「日時_ファイル名.csv」が生成されます。
「日時_ファイル名.txt」は元のファイルの付加情報の部分です。
先ほど「dx-5_settings.txt」でタグを設定しなかった部分がこちらに出力されます。
「日時_ファイル名.csv」が数値データのファイルです。
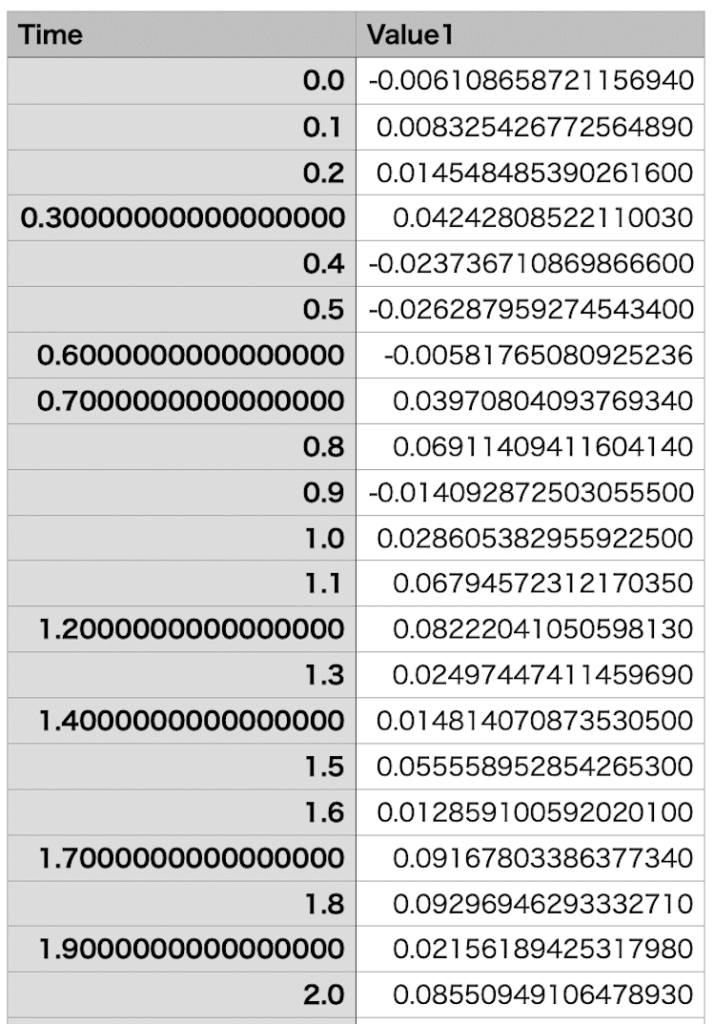
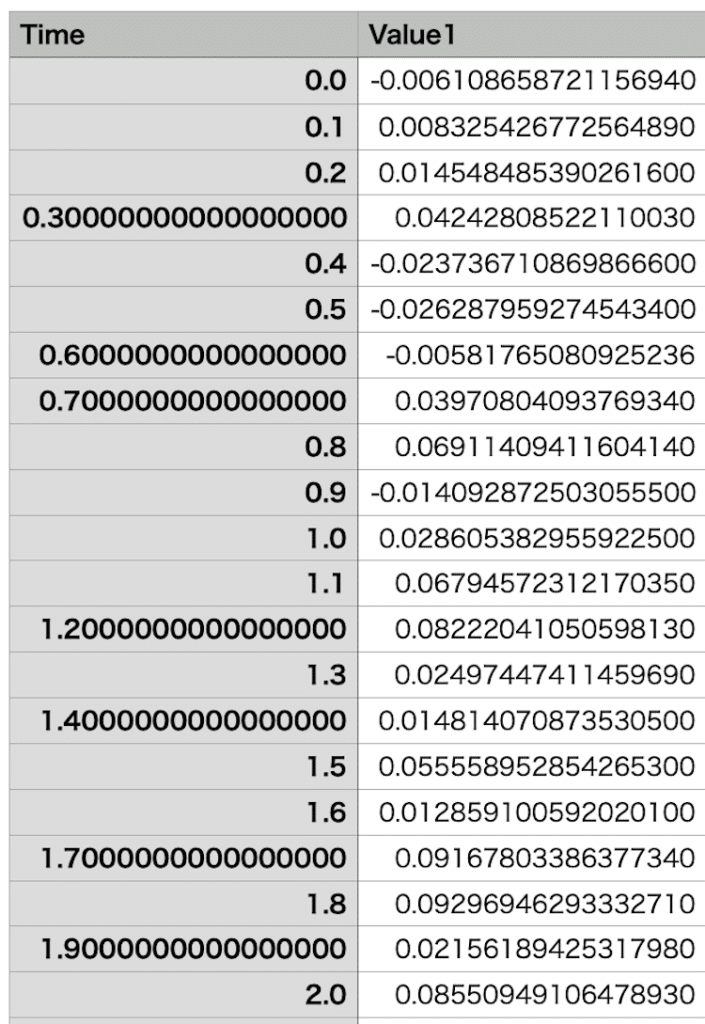
上記の例では値は2列ですが、3列でももしくはそれ以上でも抽出することができます。
例えばY値が二つあるこちらのデータも処理できます。
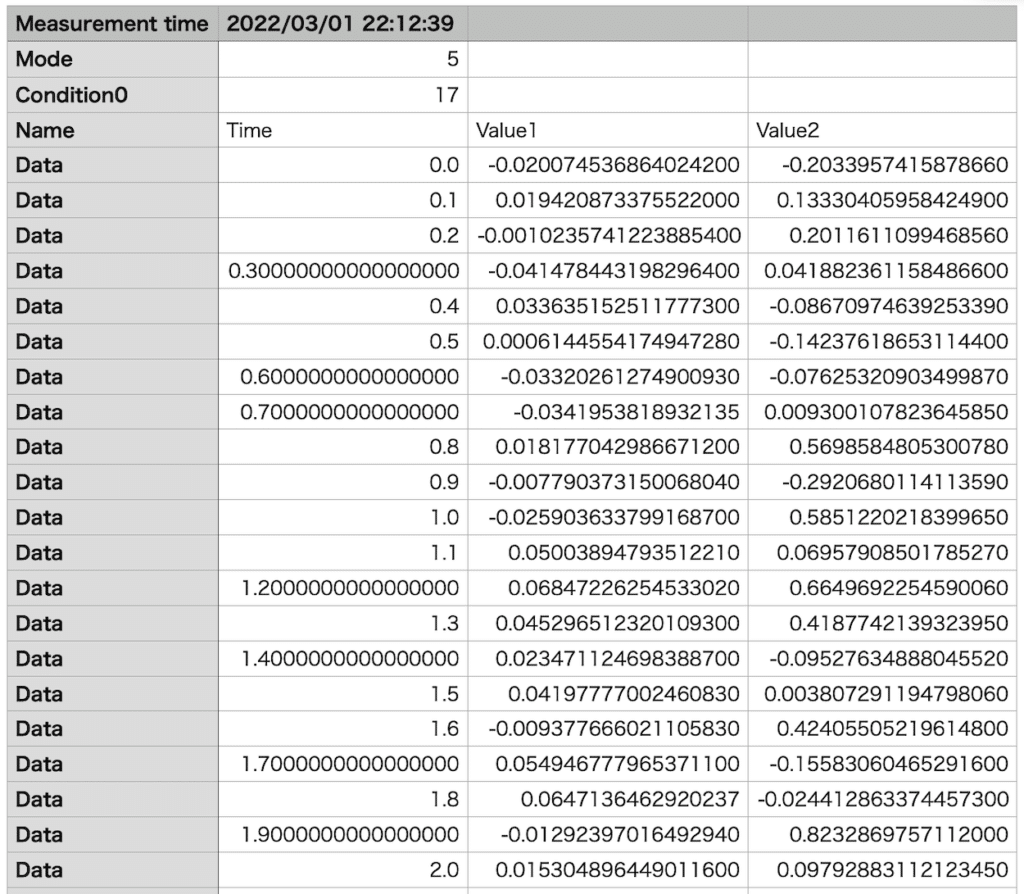
処理するとこんな感じになります。
プログラムの解説
プログラム全体
それではプログラムの解説をしていきます。
プログラム全体としてはこんな感じです。
import os
import csv
import datetime
import time
def filenameGet():
csv_list = []; text_list =[]
for filename in os.listdir('./'):
if filename.startswith('dx-5_'):
if filename.endswith('.csv'):
csv_list.append(filename[:-4])
elif filename == 'dx-5_settings.txt':
text_list.append(filename)
return csv_list, text_list
def fileProcess(csv_list, text_list, timenow):
columnname_label = ''; data_label = ''
for text in text_list:
with open(f'./{text}') as f_in:
for row in f_in:
if '列名:' in row:
columnname_label = row.split(':')[1].replace('\n','')
if 'データ:' in row:
data_label = row.split(':')[1].replace('\n','')
if columnname_label == '':
print('列名ラベルの文字列がありません。')
print('dx-5_settings.txtの「列名:」に列名ラベルを記入してください。')
print('処理を中止します。')
if data_label == '':
print('データラベルの文字列がありません。')
print('dx-5_settings.txtの「データ:」にデータラベルを記入してください。')
print('処理を中止します。')
else:
print(f'列名:{columnname_label}、データ:{data_label}でデータの取得を開始します')
for csv in csv_list:
settings_data = []; value_data = []
print(f'{csv}を処理します。')
with open(f'./{csv}.csv', 'r') as f_in:
for row in f_in:
if data_label == row.split(',')[0] or columnname_label == row.split(',')[0]:
data = ''
for value in row.split(',')[1:]:
data = data + value + ','
value_data.append(data.rstrip(','))
else:
settings_data.append(row)
with open(f'{timenow}_{csv}.txt', 'w') as f_out:
for row in settings_data:
f_out.write(row)
print(f'{csv}の設定データを{timenow}_{csv}.txtに保存しました。')
with open(f'{timenow}_{csv}.csv', 'w') as f_out:
for row in value_data:
f_out.write(row)
print(f'{csv}のデータを{timenow}_{csv}.csvに保存しました。')
def main():
timenow = timenow = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
csv_list, text_list = filenameGet()
print(f'CSVファイル:{csv_list}')
print(f'TEXTファイル:{text_list}')
fileProcess(csv_list, text_list, timenow)
print('このウインドウは10秒後に自動で閉じますので、そのままお待ちください。')
time.sleep(10)
if __name__ == '__main__':
main()前の「データ変換プログラム1」の時にやったプログラムとかなり似通っていますので、今回は大きく違う部分だけ解説します。
fileProcess関数
fileProcess関数 その1:データ取得用タグの取得
fileProcess関数 その1は「dx-5_settings.txt」からデータ取得用タグを取得する部分です。
columnname_label = ''; data_label = ''
for text in text_list:
with open(f'./{text}') as f_in:
for row in f_in:
if '列名:' in row:
columnname_label = row.split(':')[1].replace('\n','')
if 'データ:' in row:
data_label = row.split(':')[1].replace('\n','')前回は1行目だけ取得してそれを区切り位置として使用していましたが、今回は「列名:」、「データ:」の2列ありますので、まずはこれらの文字列が含まれている行を取得しています(「if ‘列名:’ in row:」、「if ‘データ:’ in row:」)。
そして取得した行を「:」で分割した後、改行を削除しています(row.split(‘:’)[1].replace(‘\n’,”))
fileProcess関数 その2:データの抽出
もう1箇所違うのは、データを抽出する部分です。
for csv in csv_list:
settings_data = []; value_data = []
print(f'{csv}を処理します。')
with open(f'./{csv}.csv', 'r') as f_in:
for row in f_in:
if data_label == row.split(',')[0] or columnname_label == row.split(',')[0]:
data = ''
for value in row.split(',')[1:]:
data = data + value + ','
value_data.append(data.rstrip(','))
else:
settings_data.append(row)この中で数値データを取得するこの部分が前のプログラムと大きく異なります。
for row in f_in:
if data_label == row.split(',')[0] or columnname_label == row.split(',')[0]:
data = ''
for value in row.split(',')[1:]:
data = data + value + ','
value_data.append(data.rstrip(','))「dx-5_settings.txt」から取得したタグを頼りに列名と数値データの行を取得していきますが、列名と数値データのタグの行とその他の行という条件分岐をしています(if data_label == row.split(‘,’)[0] or columnname_label == row.split(‘,’)[0]:)。
そして重要なのがこの部分。
data = ''
for value in row.split(',')[1:]:
data = data + value + ','行を「,(カンマ)」で分割して、最初のタグの部分以外の部分で、再度カンマ区切りのデータを構築しています。
ちなみに後で思ったのは「lstrip」を使って、タグの部分だけ削ってもよかったなと思いました。
例えばこんな感じ。
row.lstrip(f'{data_label},')試してないのでちゃんと動くか分かりませんが、もう少しスマートなやり方があると思います。
注意すべき点
注意すべき点は以下の通りです。
- 処理できるのはCSVファイルのみ
- CSVファイルの形式が制限
- WindowsとMacでは改行コード(Macでは「\n」)が違う可能性
これはほぼ今まで通りの内容で、特に変わりはありません。
これで2種類のフォーマットを処理して、グラフ作成プログラムに送ることができるようになりました。
また何か他のフォーマットを見つけたら、対応してきたいと思います。
次回は今回使用したデータを作成するプログラムを紹介します。
ではでは今回はこんな感じで。
コメント