違う文字を探す脳トレ
Twitterを色々眺めているとたまに流れてくる脳トレとして、文字がたくさんある中から、一つだけ違う感じを探し出すゲーム。
例えばこんな感じ。
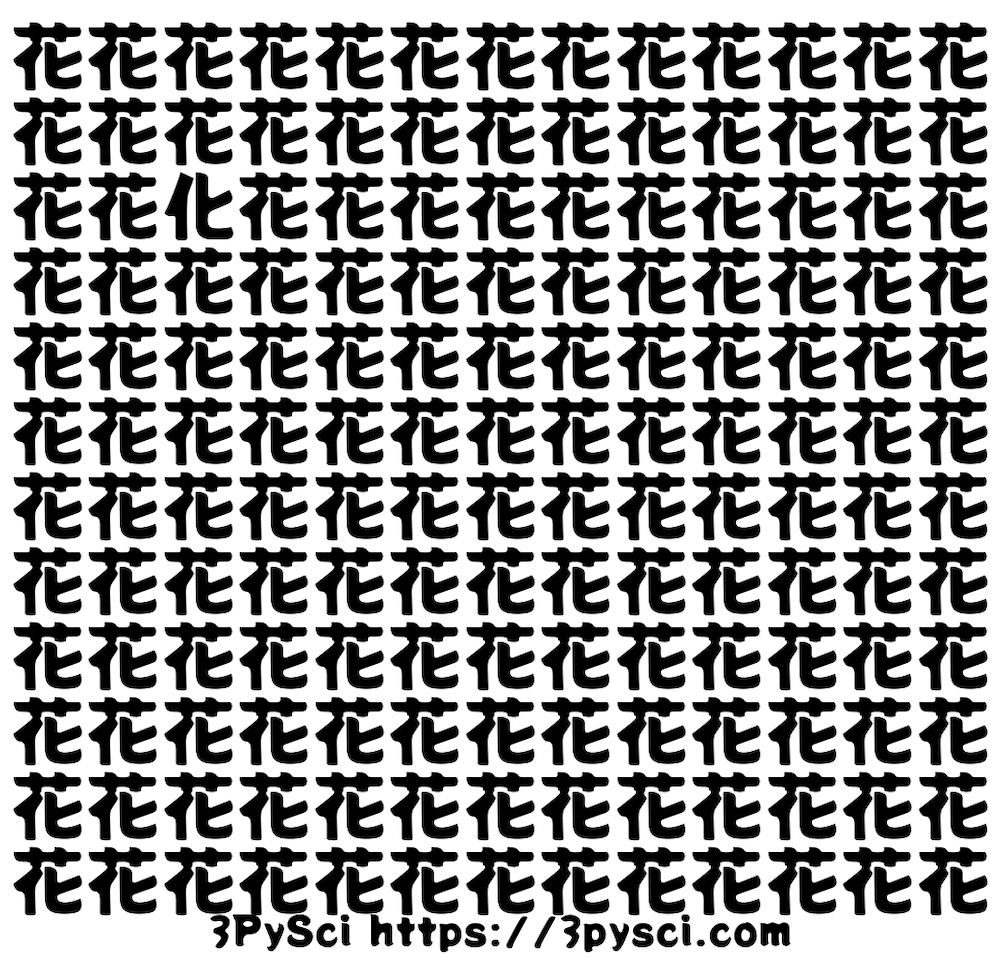
これってPythonで簡単に作れるんじゃないか?Pythonで作れたら自動化できるんじゃないか?と思ったのが今回の話のきっかけ。
実際、上の画像は自分でプログラミングPythonで作ったものなので、結果としてなかなかいい感じでできるが答えでした。
ということでせっかくなのでこのプログラムの作成方法を解説しておこうかなと思います。
それでは始めていきましょう。
問題のJSONファイル
まず問題をまとめたJSONファイルを作成します。
せっかく自動化するのなら、1問ずつ自分で文字を指定して作成するなんてのはもったいない。
使用する文字をまとめておいて、そこから定期的に文字をランダムに選択、画像を作成、そしてTwitterに定期的にアップロードというのが自動化としては目指すところなわけです。
ということで作成したJSONファイル「question.json」がこちら。
{
"1":["間","問"],
"2":["夫","大"],
"3":["辛","幸"],
"4":["巣","単"],
"5":["花","化"]
}とりあえず5つの漢字セットを準備してみました。
一つの漢字セットは「”1″:[“間”,”問”]」という形式で、「”問題番号”:[”埋め尽くす漢字”:”一つだけ違う漢字”]」です。
問題番号は本当はint型がよかったのですが、JSON形式ではキーにint型を使えないようなので、Str型になっています。
今後、どんどん漢字を追加していきますが、そこは私のオリジナリティも必要なので、ここでは公開しません。
皆さんは皆さんなりの漢字セットを追加していってください。
問題作成のプログラム
次に問題を作成するプログラムを作っていきます。
流れとしては、こんな感じ。
- 問題のJSONファイルを読み込んで、使用する文字セットを取得
- 縦横に並べる文字数をランダムに決めて、何番目を違う文字にするか決定
- 並べるための文字のリストを作成
今回は解説するためにJupyter notebookを使っていきますので、それぞれセル番号を書いておきます。
後ほどPython実行形式にして、そちらはGitHubにアップロードする予定です。

JSONファイルの読み込みと使用する文字セットの取得
まずは先ほど作成した問題のJSONファイルを読み込み、使用する文字セットを取得していきます。
プログラムとしてはこんな感じ。
<セル1>
import random
import json
with open('./question.json', 'r') as f_in:
question_list = json.load(f_in)
char_list = question_list[str(random.choice(list(question_list)))]
print(char_list)まずrandomモジュールとjsonライブラリを使用するため、インポートします。
import random
import jsonそしてJSONファイルを読み込みます。
ファイルの場所は適宜変更してください。
with open('./question.json', 'r') as f_in:
question_list = json.load(f_in)PythonでのJSONファイルの取り扱いに関してはこちらの記事で解説していますので、よかったらどうぞ。
ここまではこれまでにも何度か使っているので、それほど難しくはないことでしょう。
問題は取得したリストからどうやってランダムに文字セットを取得するかということでした。
その部分がこちら。
char_list = question_list[random.choice(list(question_list))]
print(char_list)まず読み込んだJSONファイルは辞書形式なので、「list()」を使ってリスト形式にします。
そしてリスト形式からランダムで一つ選択する「random.choice()」を使いました。
randomモジュールに関してはこちらの記事でも解説していますので、よかったらどうぞ。

こうすることで辞書形式のキー、つまり「”1″:[“間”,”問”]」の「”1″」の部分がint型として取得できます。
取得した問題番号はそのままリストのインデックスとして使用し、文字セットを取得しています。
先ほどのプログラムを実行するとこんな感じで文字セットが取得できます。
実行結果
['間', '問']文字数と違う文字の場所の決定
次に縦何文字、横何文字並べ、どこに違う文字を配置するかを決めていきます。
そのプログラムはこんな感じ。
<セル2>
cell_min = 10; cell_max = 20
vertical = random.randint(cell_min, cell_max)
horizontal = random.randint(cell_min, cell_max)
num_char = vertical*horizontal
diff_char_no = random.randint(1, num_char)
print(vertical, horizontal, num_char, diff_char_no)まず縦横に並べる文字の最小の個数と最大の個数を決めておき、そこからランダムで縦の文字数、横の文字数を決めています。
cell_min = 10; cell_max = 20
vertical = random.randint(cell_min, cell_max)
horizontal = random.randint(cell_min, cell_max)そしてランダムで決めた縦の文字数と横の文字数を掛け合わせることによって、全体の文字数を取得します。
num_char = vertical*horizontal次に全体の文字数を最大値とした中からランダムに一つ数字を取得し、これを異なる数字を配置する番号とします。
diff_char_no = random.randint(1, num_char)「random.randint(数字1, 数字2)」では数字1以上数字2以下の中からランダムな値を一つ取得します。
「random.randint(1, num_char)」で1からにしているのは、縦と横の文字数をかけた値で最小なのは1だからです。
またrandint()では数字2の値も”含む”ことから、最大の数は「num_char」にしています。
これを実行すると例えばこんな感じで数字が得られます。
実行結果
20 18 360 240それぞれ「縦の文字数」、「横の文字数」、「全体の文字数」、「違う文字を配置する番号」です。
文字のリストを作成
次に先ほど取得した「全体の文字数」と「違う文字を配置する番号」から文字のリストを作成していきます。
ということでこんな感じ。
<セル3>
output_list = []
for num in range(1, num_char+1):
if num == diff_char_no:
output_list.append(char_list[1])
else:
output_list.append(char_list[0])
print(output_list)for文とrange関数を使って、数字をループさせています。
そして通常は「文字セットのインデックス0の文字」をリストoutput_listに追加、「違う文字を配置する番号」になった時に「文字セットのインデックス1の文字」をリストoutput_listに追加しています。
注意する点はrange関数の範囲です。
先ほど「違う文字を配置する番号」を取得した時同様、最小は1で最大は「全体の文字数」ですが、range関数で最大値ではその数を”含みません”。
そのため最大値には「+1」が必要になります。
このプログラムを実行するとこんな感じの出力が得られます。
実行結果
['間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '問', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間', '間',
'間', '間', '間', '間', '間', '間', '間', '間', '間', '間']これだけでも結構ゲシュタルト崩壊を起こしそうですが、次回はこれを画像にしていきましょう。

ではでは今回はこんな感じで。
コメント