前回のおさらい:グラフの表示
前回は温度・湿度ロガーのデータを分析するため、リストに格納したデータをグラフにして表示するプログラムを作成しました。
今回はプログラム全体を統合し、バグの修正を行なっていきます。
まずはこれまでのおさらいから。
最初に作成したのはフォルダ構造を整えるプログラムでした。
import os
import shutil
def dir_check(dirname, dirlist):
if dirname not in dirlist:
os.mkdir(dirname)
elif dirname in dirlist:
shutil.rmtree(dirname)
os.mkdir(dirname)
path = os.getcwd()
# print(path)
dirnames = []
for f in os.listdir(path):
if os.path.isdir(f) == True:
dirnames.append(f)
# print(dirnames)
dir_check("Data", dirnames)
dir_check("Graph", dirnames)次に作成したのはCSVファイルを読み込み、データをリストに格納するプログラムでした。
import os
import shutil
import csv
import datetime
def is_float(val):
try:
float(val)
except:
return False
else:
return True
path = os.getcwd()
data_path = path + "//Data//"
for f in os.listdir(path):
if f[-4:] == ".csv":
shutil.move(f, data_path + f)
time = []; temperature = []; humidity = []
for f in os.listdir(data_path):
if f[-4:] == ".csv":
file = open(data_path + f, "r")
reader = csv.reader(file)
for row in reader:
if row != [] and is_float(row[1]) == True and is_float(row[2]) == True:
time.append(datetime.datetime.strptime(row[0], "%Y-%m-%d %H:%M:%S"))
temperature.append(float(row[1]))
humidity.append(float(row[2]))
file.close()
# print(time)
# print(temperature)
# print(humidity)最後に作成したのは、リストに格納したデータをグラフとして表示するプログラムでした。
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(8,8))
ax1 = fig.subplots()
ax2 = ax1.twinx()
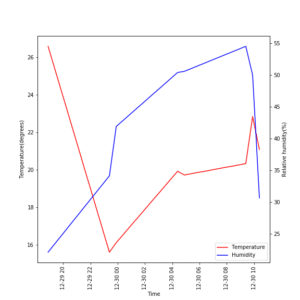
ax1.plot(time, temperature, color="red", label="Temperature")
ax2.plot(time, humidity, color="blue", label="Humidity")
ax1.set_ylabel("Temperature(degrees)")
ax2.set_ylabel("Relative humidity(%)")
ax1.set_xlabel("Time")
ax1.tick_params(axis="x", rotation=90)
h1, l1 = ax1.get_legend_handles_labels()
h2, l2 = ax2.get_legend_handles_labels()
ax1.legend(h1 + h2, l1 + l2, loc="lower right")
graph_path = path + "//Graph//"
plt.savefig(graph_path + "graph.png")
plt.show()これを統合していきます。
とりあえずAnacondaを使うことを想定し、役割ごとにセルに分割していきます。
ということで今回はAnacondaでPython3のプログラムを新規作成して開始しましょう。

また今回のようにバグ修正を目的とする場合は、前に読み込んだデータや変数に格納したデータなどが残っている可能性があるので、確認するたびにカーネルの再起動をすることをお勧めします。

import
最初は「import」です。
何はともあれどんなプログラムでも必要なライブラリは最初に読み込みます。
今回、三つのプログラムで使っているライブラリはこちら。
#Import libraries
import os
import shutil
import csv
import datetime
from matplotlib import pyplot as pltとりあえず単純にこれらを一つのセルに入れます。
最初の行に「#Import libraries」のようにコメントアウトそのセルの役割を書いておくと後からみて分かりやすいです。
(#をつけた行はプログラムとしては読まれない = コメントアウトと呼びます)
セルに入れたら「Shift + Enter」で実行しておきます。
Definition
次は自分の関数の定義です。
今回のプログラムで自分で定義した関数は次の二つ。
#Definition
def dir_check(dirname, dirlist):
if dirname not in dirlist:
os.mkdir(dirname)
elif dirname in dirlist:
shutil.rmtree(dirname)
os.mkdir(dirname)
def is_float(val):
try:
float(val)
except:
return False
else:
return Trueこれを次のセルに入れて、実行しておきます。
フォルダ構造の整理
次にフォルダ構造を整理するプログラムを次のセルに追加します。
#Check&make directories
path = os.getcwd()
print(path)
dirnames = []
for f in os.listdir(path):
if os.path.isdir(f) == True:
dirnames.append(f)
print(dirnames)
dir_check("Data", dirnames)
dir_check("Graph", dirnames)今回はチェックも兼ねているので、コメントアウトした2カ所のコメントアウトを解除しておきます。
print(path)print(dirnames)他に特に変更点はないので、追加したら実行しておきます。
CSVファイル読み込みとデータの格納
次はCSVファイルの読み込みとデータの格納を行います。
これまでのプログラムと被っているところは飛ばして、他の部分を次のセルに追加します。
#Read CSV files
data_path = path + "//Data//"
for f in os.listdir(path):
if f[-4:] == ".csv":
shutil.move(f, data_path + f)
time = []; temperature = []; humidity = []
for f in os.listdir(data_path):
if f[-4:] == ".csv":
file = open(data_path + f, "r")
reader = csv.reader(file)
for row in reader:
if row != [] and is_float(row[1]) == True and is_float(row[2]) == True:
time.append(datetime.datetime.strptime(row[0], "%Y-%m-%d %H:%M:%S"))
temperature.append(float(row[1]))
humidity.append(float(row[2]))
file.close()
print(time)
print(temperature)
print(humidity)ここも確認のため、コメントアウトした下の箇所のコメントアウトを解除しておきます。
print(time)
print(temperature)
print(humidity)これで実行してみます。
実行結果
[]
[]
[]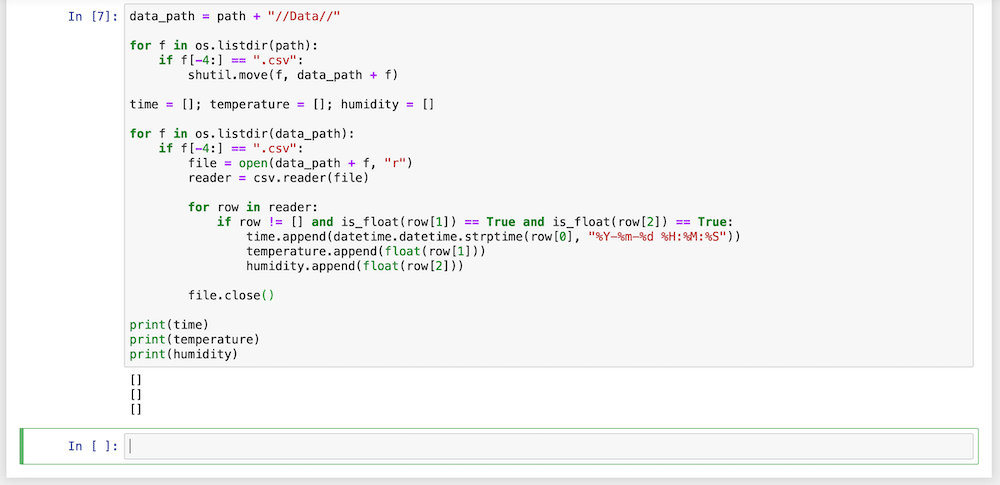
ここでバグに当たりました。
本来ならtime、temperature、humidityに格納されたデータが表示されるはずですが、表示されません。
ということでこのバグをまずは解消していきます。
格納されるはずのデータが消失
ということで何故か格納されるはずのデータが格納されていないバグの原因を探ります。
とりあえずそれぞれのリストが[][][]と表示されることから、プログラム自体は正常終了していると考えられます。
ということはプログラム内ではないどこか。
ということでCSVファイル自体を確認してみましょう。
まずはプログラムが入っているフォルダから。
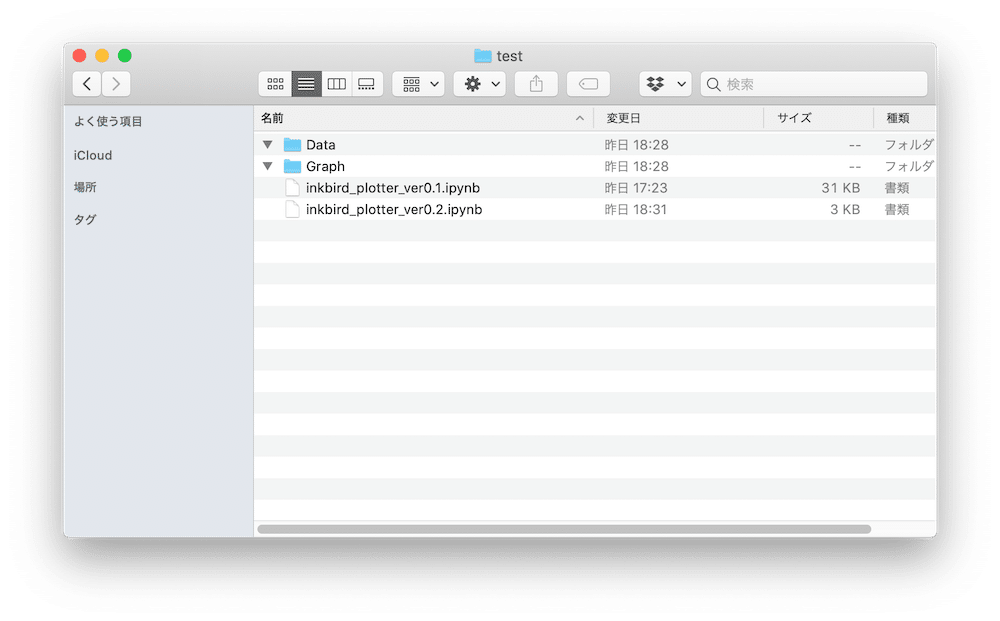
ここにはプログラムが入っています。
inkbird_plotter_ver0.1.ipynbがこれまで作ってきた古いプログラム、inkbird_plotter_ver0.2.ipynbが今回作り直しているプログラムです。
そしてDataフォルダとGraphフォルダがあります。
このDataフォルダに元のデータ「temperature_testdata1.csv」があるはずです。
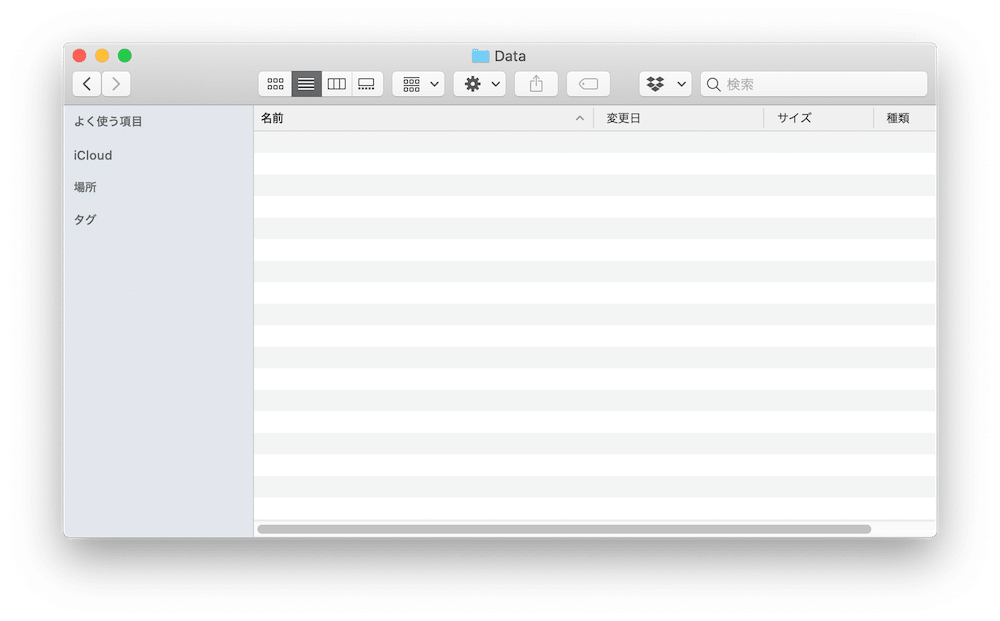
しかし空。
問題点はここにありそうです。
もう一度プログラムの流れを確認してみると、こんな感じです。
- Data、Graphフォルダの確認
- フォルダがなければ作成、あれば一度削除して作成
- CSVファイルをDataフォルダに移動
- CSVファイルの読み込み
- グラフ表示、保存
問題点に気づきましたでしょうか?
プログラム実行1回目では、Dataフォルダが作成され、CSVファイルはDataフォルダに移されます。
そしてプログラム実行2回目に1回目に作成したDataフォルダは削除され、新たに作成されます。
その際、Dataフォルダ内にあるCSVファイルも同時に削除されてしまいます。
ということでData、Graphフォルダがある場合は、再作成せずにスルーすることにしましょう。
下の部分を削除します。
elif dirname in dirlist:
shutil.rmtree(dirname)
os.mkdir(dirname)ということでこうなります。
#Definition
def dir_check(dirname, dirlist):
if dirname not in dirlist:
os.mkdir(dirname)
def is_float(val):
try:
float(val)
except:
return False
else:
return Trueこれで再度、全てのセルを実行してみましょう。
まずは実行前。
「temperature_testata1.csv」をプログラムと同じフォルダに置きます。
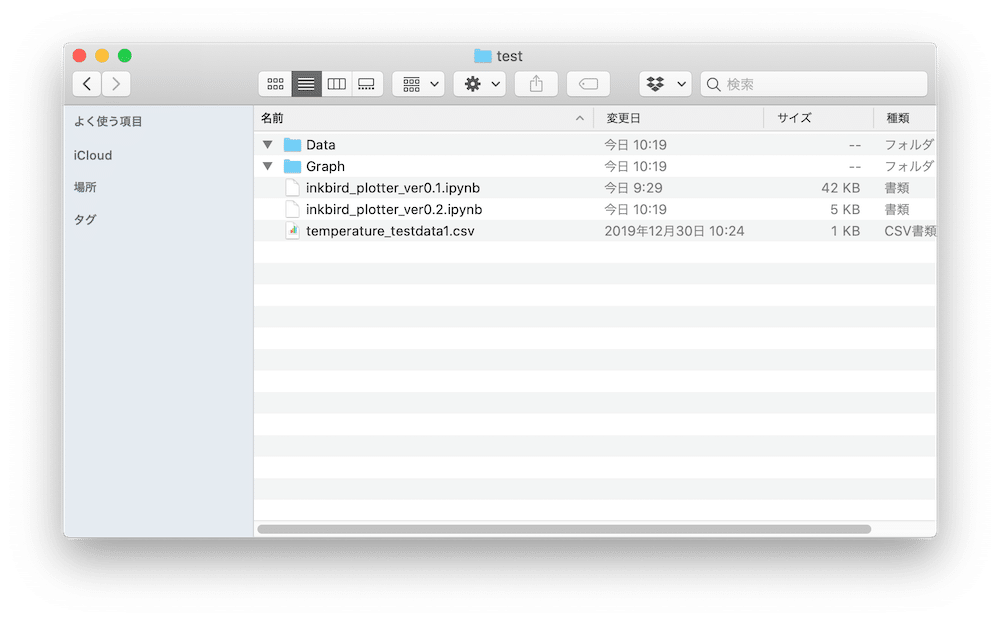
1回目の実行ではこんな感じ。
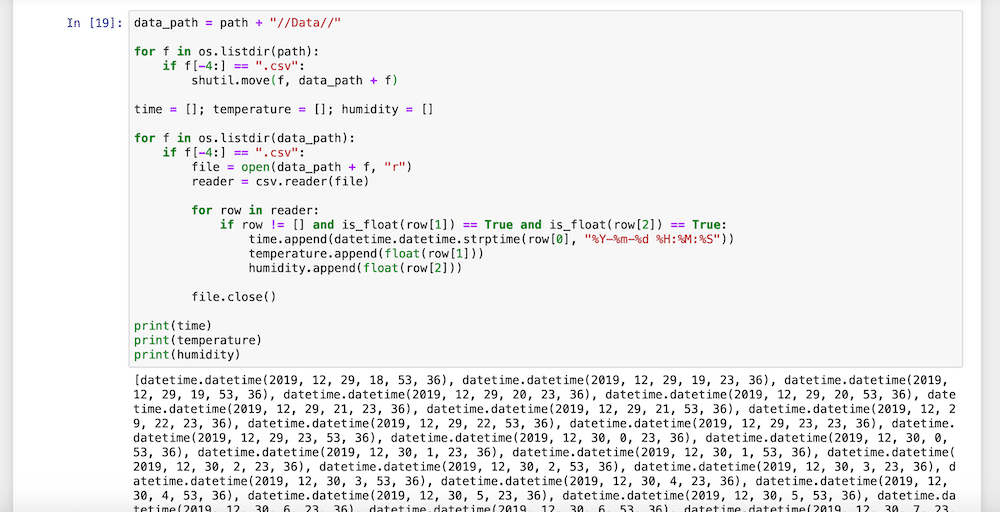
ちゃんとtime、temperature、humidityのリストにデータが入っています。
また「temperature_testdata1.csv」がDataフォルダに入っています。
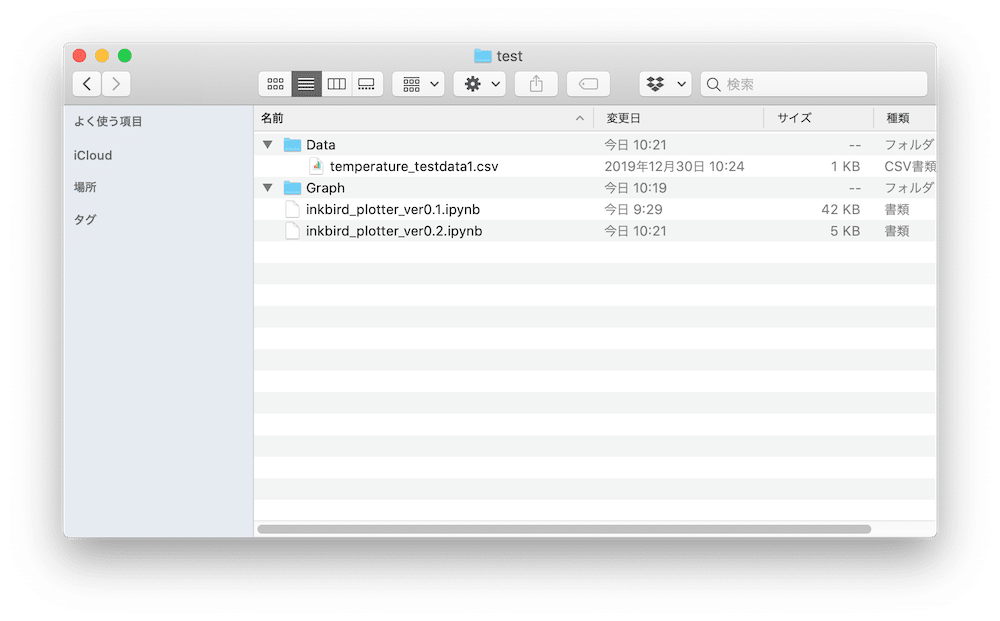
続けてもう一回全部のセルを実行します。
それでも3つのリストにはちゃんとデータが格納されています。
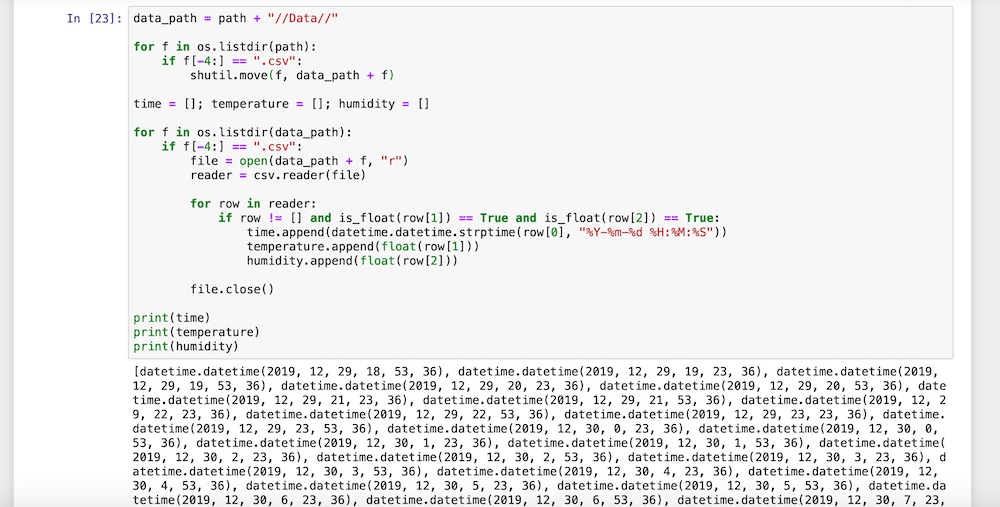
CSVファイルも消えていません。
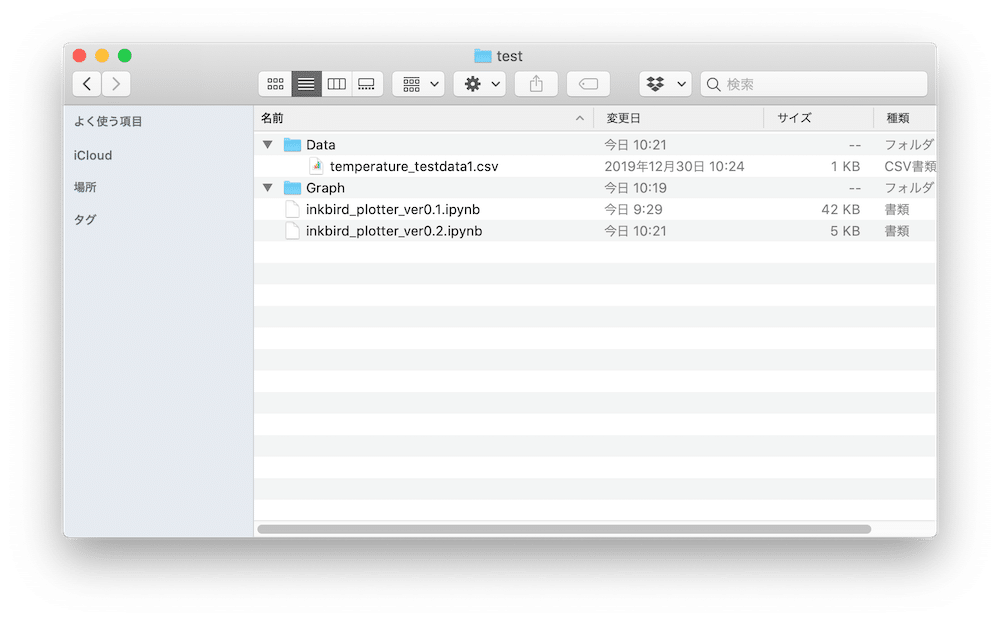
ここで懸念されるのは同じ名前のファイルが来た場合どうなるのかということ。
ということでCSVファイルをコピーして、プログラムと同じフォルダにおきます。
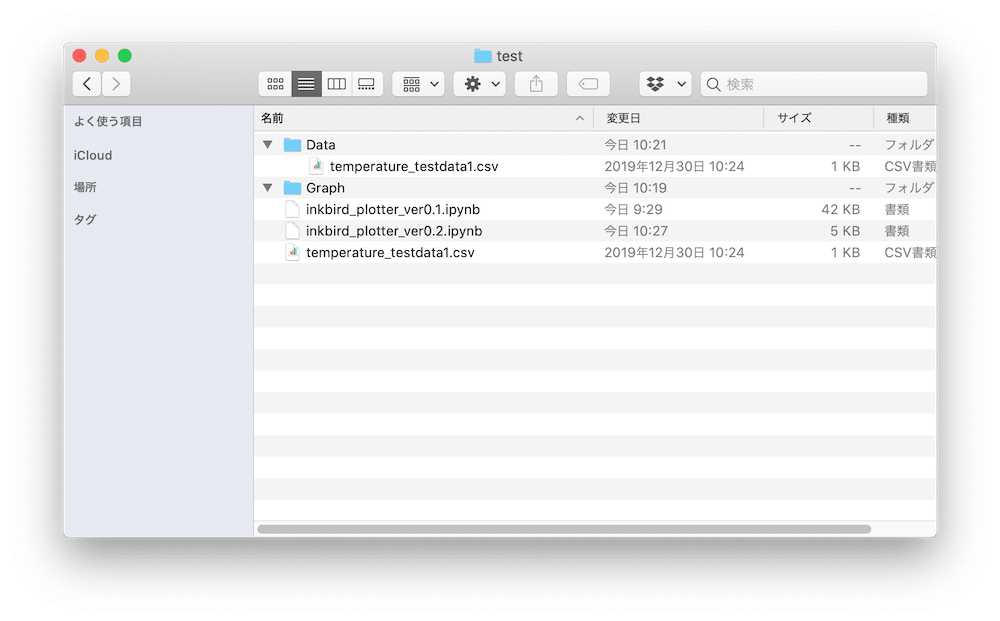
そしてもう一度全てのセルを実行します。
その結果がこちら。
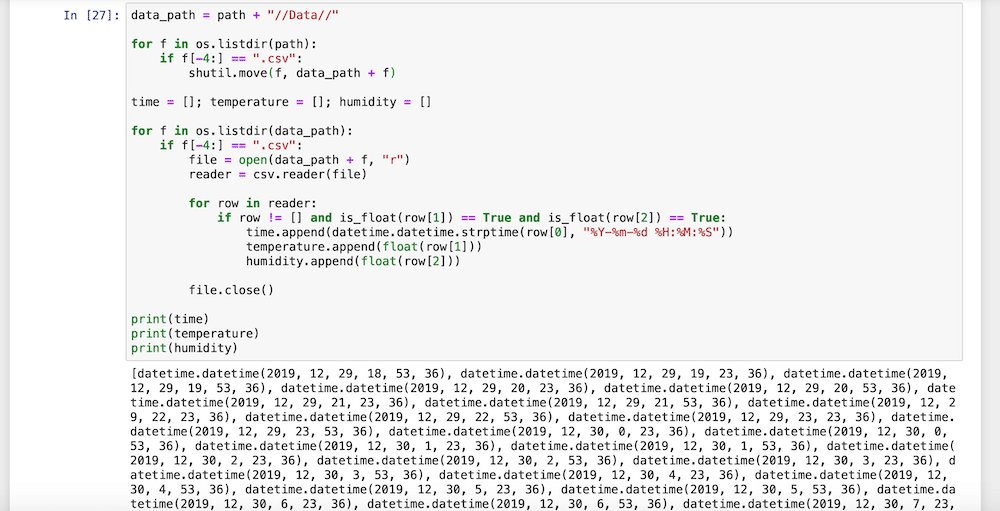
ちゃんと3つのリストにデータが格納されています。
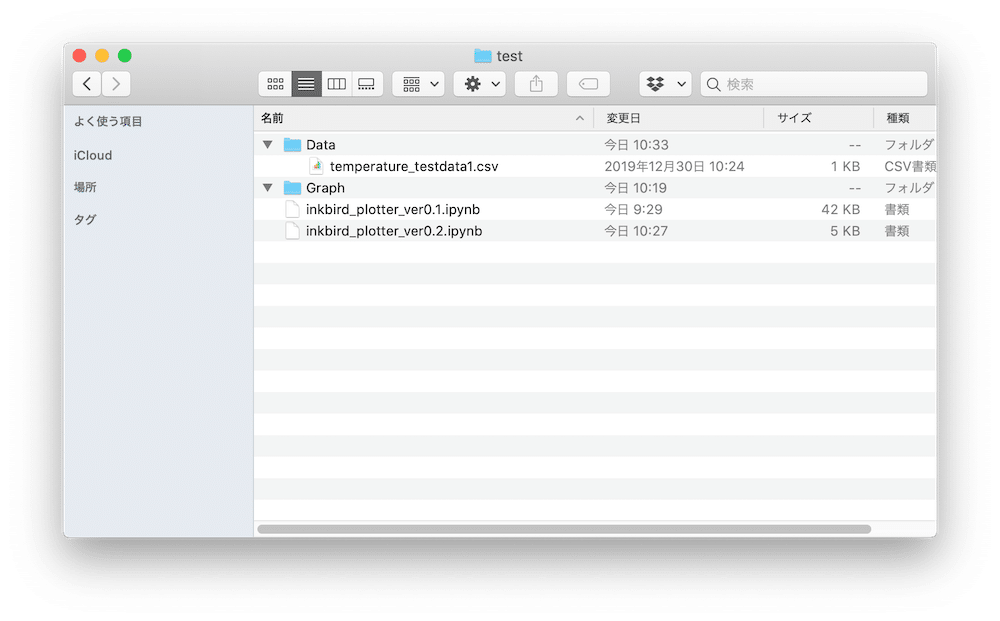
プログラムと同じフォルダに置いたCSVファイルはDataフォルダに移動されますが、同じ名前のファイルがあると上書きされるようですね。
これでとりあえずこのバグは解消できました。
長くなってしまったので今回はここまでとしますが、次回はこのままプログラム統合とバグ修正の続きを行っていきます。
ということで今回はこんな感じで。
コメント