データ解析支援ライブラリPandas
前にデータ解析支援ライブラリPandasを使ってグラフ表示をする方法を解説しました。
Pandasはまだまだ色んな解析ができるライブラリなので、今回から何回かに分けて、その解説をしていきたいと思います。
使用するデータはこちらのダミーデータを作成するプログラムで作成します。
とりあえず10列10行の0から99までのランダムな数字を使ったファイルを一つ作成しておきます。
ということでこんな感じ。
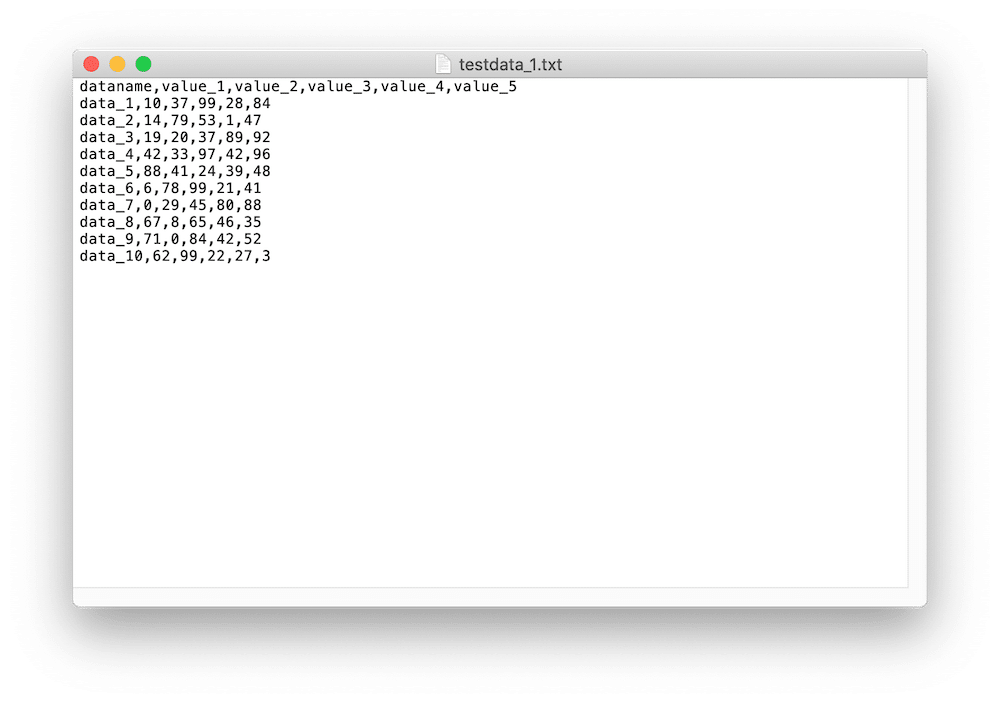
同じデータを使いたい方はこちらからダウンロードしてください。
Anacondaを使っている方は、最初からPandasがインストールされているので、インポートすれば使用できます。
import pandas as pdPandasはよく「pd」としてインポートされるので、上記のように「as pd」と最後につけておきます。
それでは色々いじっていきましょう。
CSVデータの読み込み:pd.read_csv()
CSVデータを読み込むには、「pd.read_csv(“ファイル名”)」を用います。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt")
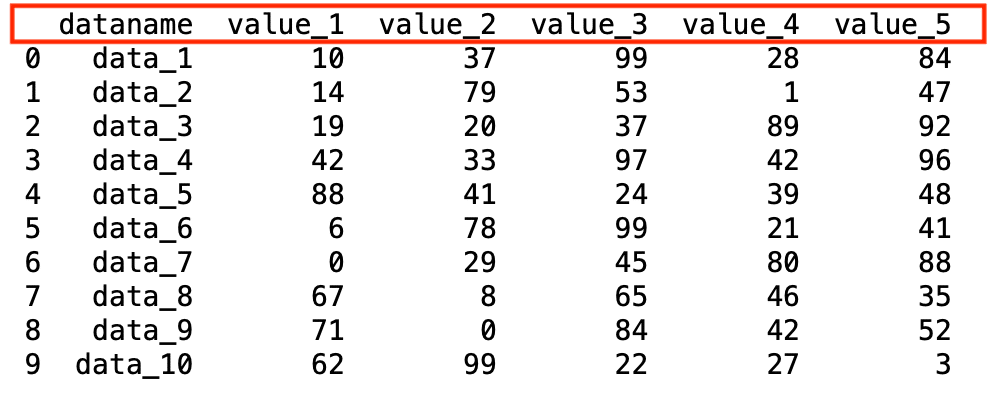
print(df)
実行結果
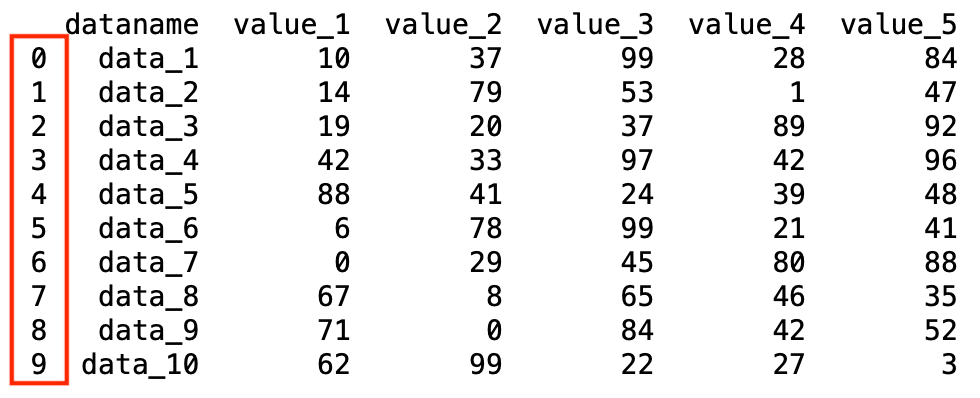
dataname value_1 value_2 value_3 value_4 value_5
0 data_1 10 37 99 28 84
1 data_2 14 79 53 1 47
2 data_3 19 20 37 89 92
3 data_4 42 33 97 42 96
4 data_5 88 41 24 39 48
5 data_6 6 78 99 21 41
6 data_7 0 29 45 80 88
7 data_8 67 8 65 46 35
8 data_9 71 0 84 42 52
9 data_10 62 99 22 27 3考え方としてはファイルを読み込む際と同じです。

つまりpf.read_csv(“ファイル名”)で読み込んだファイルを変数dfに格納しているということです。
ちなみにdfとはDataFrame(データフレーム)の略です。
データの形式としては、データの中の最初の行が自動的にヘッダーになります。
インデックスは自動で番号が振られます。
ヘッダーもインデックスも指定できるのですが、先に表示方法を解説します。
データテーブル(表)の表示
先ほどCSVデータを読み込み、表示する際にprint(df)としました。
ですが実はPandasでデータテーブル(表のこと)を表示するには、print関数はいらず、ただCSVファイルを格納した変数(今回の場合は「df」)をタイプするだけです。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt")
df
実行結果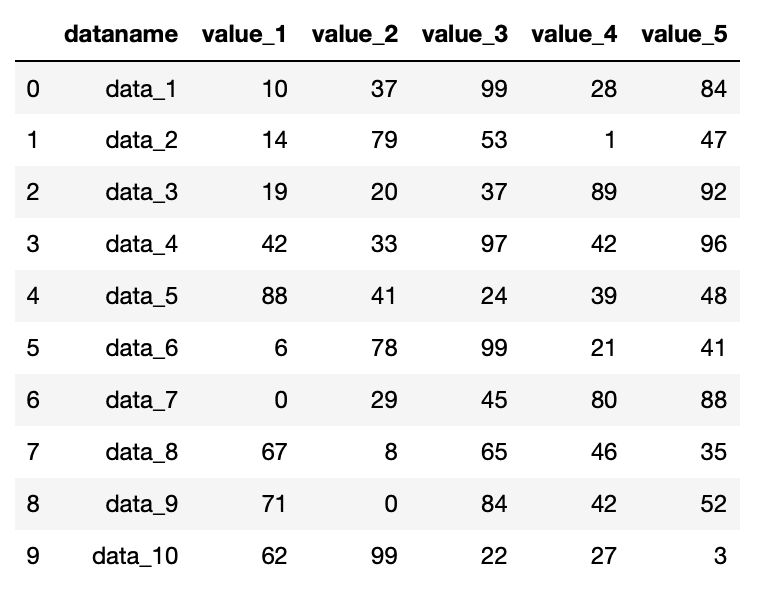
単に変数名をタイプするだけでこれだけ綺麗な表が作られるのは、ちょっとびっくりですね。
今回はデータ全部を表示していますが、行や列を指定して表示することもできるので、次回細かく解説したいと思います。
CSVファイルを読み込む際のヘッダーの指定の方法:header
それでは先ほどのCSVファイルを読み込む時に、ヘッダーを指定する方法を解説していきます。
df.read_csv()のオプションとして、header=”ヘッダー行”として指定します。
まずは「header=0」を試してみます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", header=0)
df
実行結果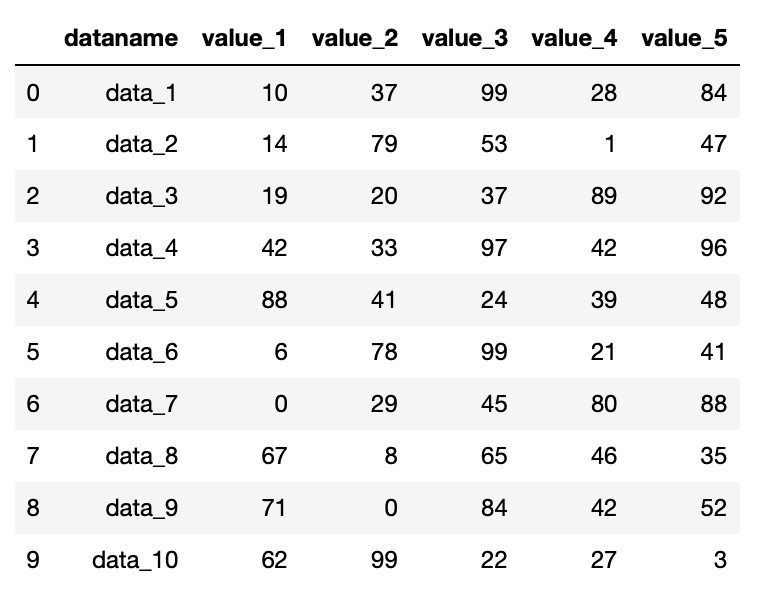
先ほどの指定しなかった場合と同じ表になりました。
つまりヘッダーに関しては「0」がデフォルトということになります。
つぎに「header=1」 を試してみます。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", header=1)
df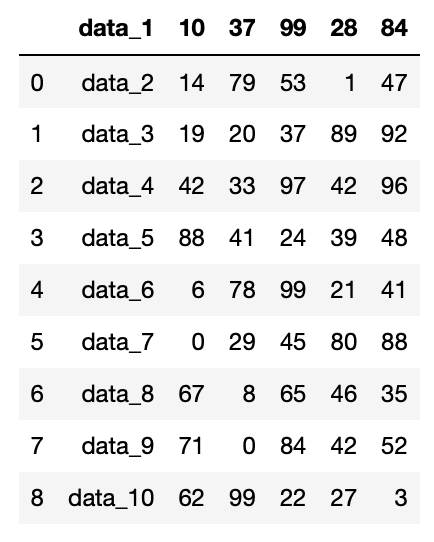
data_1の行がヘッダー行に変わりました。
しかし最初の行がヘッダー行ではなく、いきなりデータから始まっている場合もあることでしょう。
その場合は「header=None」とすることで、ヘッダー行がなしという指定も可能です。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", header=None)
df
実行結果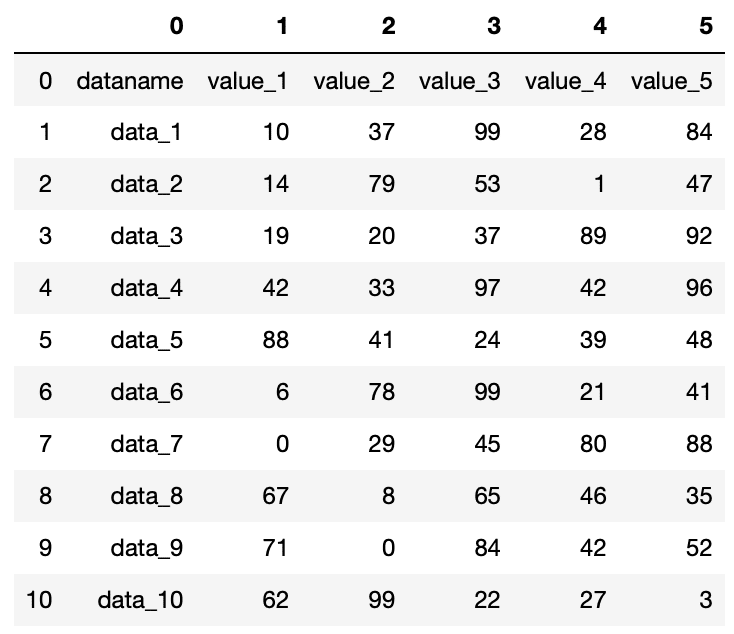
「header=None」とした場合、ヘッダーには自動で番号が振られるようです。
CSVファイルを読み込む際のインデックスの指定の方法:index_col
次にインデックスの指定方法を解説していきます。
インデックスを指定するにはread_csv()のオプションとして、index_col=” インデックス行”とします。
こちらもまずは「index_col=0」を試してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df
実行結果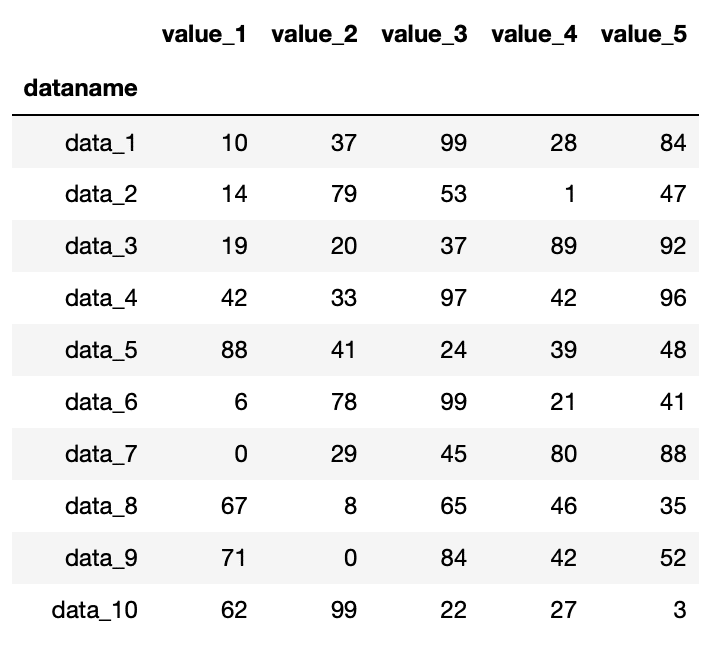
先ほどインデックス列を指定していない場合は、一番左に数字が自動で振られていました。
「index_col = 0」とすると、一番最初の列である「dataname」の列がインデックス列になりました。
今回はまずはPandasの基本ということで、データの読み込みを解説してみました。
読み込みに関しては、コマンドは変わるものの基本的に普通にCSVファイルを読み込むのと変わらないかなという感じです。
ですがPandasが威力を発揮するのはここからです。
次回はデータの表示方法を解説していきます。
ということで今回はこんな感じで。
コメント