Pandas
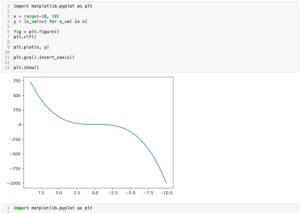
前回、PythonのmatplotlibでX軸やY軸の数値を反転させる方法を紹介しました。
今回はPandasのデータをもつデータフレームを作成する方法を紹介します。
それでは始めていきましょう。
空のデータフレームにデータを追加して作成する方法
まずは私がよくやる空のデータフレームを作成し、そこに列でデータを追加するという方法です。
空のデータフレームを作成するには「データフレーム名 = pd.DataFrame()」です。
またそのデータフレームに新たな列のデータを追加するには「データフレーム名[“列名”] = データ」です。
import pandas as pd
df = pd.DataFrame()
df["A"] = [1, 2, 3, 4, 5]
df["B"] = [2, 4, 6, 8, 10]
print(df)
実行結果
A B
0 1 2
1 2 4
2 3 6
3 4 8
4 5 10辞書にデータをまとめてからデータフレームを作成する方法
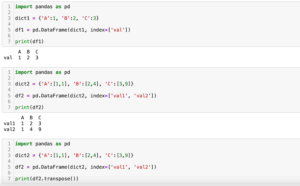
次の方法は辞書にデータをまとめてから、データフレームを作成する方法です。
この場合、辞書のキーが列名になります。
そして辞書からデータフレームを作成するには「データフレーム名 = pd.DataFrame(辞書)」です。
ただし辞書の値がリストではなく、一つの数値である場合、「If using all scalar values, you must pass an index」のエラーが出ることがあります。
その場合はインデックスを合わせて指定してあげてください。
import pandas as pd
df = pd.DataFrame()
data = {}
data["A"] = [1, 2, 3, 4, 5]
data["B"] = [2, 4, 6, 8, 10]
df = pd.DataFrame(data)
print(df)
実行結果
A B
0 1 2
1 2 4
2 3 6
3 4 8
4 5 10
2つの方法の比較
いつもは「空のデータフレームにデータを追加して作成する方法」を使っているのですが、最近になって「辞書にデータをまとめてからデータフレームを作成する方法」が便利そうだなと思い始めました。
ということでこんな2つのプログラムを組んで比較してみました。
import pandas as pd
num_columns = 10
num_rows = 10
col_number_list = [i for i in range(num_columns)]
df = pd.DataFrame()
for i in col_number_list:
df[f"column_{i}"] = [i for _ in range(num_rows)]
print(df)
実行結果
column_0 column_1 column_2 column_3 column_4
0 0 1 2 3 4
1 0 1 2 3 4
2 0 1 2 3 4
3 0 1 2 3 4
4 0 1 2 3 4import pandas as pd
num_columns = 5
num_rows = 5
col_number_list = [i for i in range(num_columns)]
data = {}
for i in col_number_list:
data[f"column_{i}"] = [i for _ in range(num_rows)]
df = pd.DataFrame(data)
print(df)
実行結果
column_0 column_1 column_2 column_3 column_4
0 0 1 2 3 4
1 0 1 2 3 4
2 0 1 2 3 4
3 0 1 2 3 4
4 0 1 2 3 4任意の列数、行数のデータフレームを2つの作り方で作るプログラムです。
これをマジックコマンド「%%timeit」を使って処理時間を測定してみます。
| 列数、行数 | 空のデータフレームに追加 | 辞書にまとめてから追加 |
| 10 | 2.31 ms ± 304 µs | 263 µs ± 7.23 µs |
| 100 | 20.8 ms ± 2.34 ms | 4.11 ms ± 89.4 µs |
| 1000 | 635 ms ± 22.4 ms | 267 ms ± 24.5 ms |
全体的に「辞書にデータをまとめてからデータフレームを作成する方法」の方が処理が数倍速いようです。
また「空のデータフレームにデータを追加して作成する方法」では列数、行数が1000から「<magic-timeit>:11: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`」という警告がでました。
ちなみにこの警告は何度も列を追加することでが出るようです。
そのため一度に追加する「辞書にデータをまとめてからデータフレームを作成する方法」ではでないようです。
ということで今後はなるべく辞書でデータフレームをまとめてから、データフレームに追加するようにしていこうと思います。
既存のデータフレームに複数の列のデータを追加する方法
ちなみに既存のデータフレームに複数の列のデータを追加するのにも使えます。
その場合は追加したいデータを辞書でまとめてから、「pd.concat([データフレーム1, データフレーム2], axis=1)」で結合させます。
import pandas as pd
num_columns = 5
num_rows = 5
col_number_list = [i for i in range(num_columns)]
data1 = {}
for i in col_number_list:
data1[f"column_1-{i}"] = [i for _ in range(num_rows)]
df1 = pd.DataFrame(data1)
data2 = {}
for i in col_number_list:
data2[f"column_2-{i}"] = [i for _ in range(num_rows)]
df2 = pd.DataFrame(data2)
df_new = pd.concat([df1, df2], axis=1)
print(df_new)
実行結果
column_1-0 column_1-1 column_1-2 column_1-3 column_1-4 column_2-0 \
0 0 1 2 3 4 0
1 0 1 2 3 4 0
2 0 1 2 3 4 0
3 0 1 2 3 4 0
4 0 1 2 3 4 0
column_2-1 column_2-2 column_2-3 column_2-4
0 1 2 3 4
1 1 2 3 4
2 1 2 3 4
3 1 2 3 4
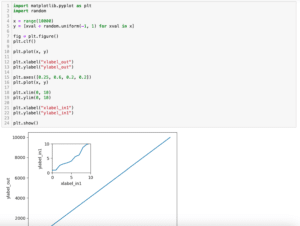
4 1 2 3 4 次回はmatplotlibでグラフの中に拡大図のような小さなグラフを表示する方法を紹介します。
ではでは今回はこんな感じで。
コメント