機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnのボストンの住宅価格を3種類の特徴量と6種類の特徴量を使って機械学習させ、評価してみました。
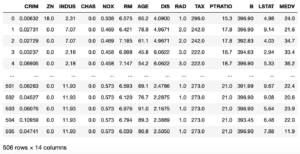
前回、予想した価格と実際の価格がどれくらい合っているかを、決定係数というものを用いて評価をしました。
この決定係数というのは、予想と答えが近いほど「1」に近づき、遠いほど「0」に近く係数です。
その中で「0.6」というのは、まだまだ低い値になります。
機械学習の場合、この決定係数が「0.8」程度になるとなかなかいい機械学習ができたと言われるようです。
こちらのサイトで機械学習における決定係数の判断目安が載っていますので、よく知りたい方はこちらをご覧ください。

ただし高すぎても「過学習」と言われるように、「学習データに合い過ぎた状態」になってしまうそうです。
ということで決定係数が「0.8」程度になるように色々試してみましょう。
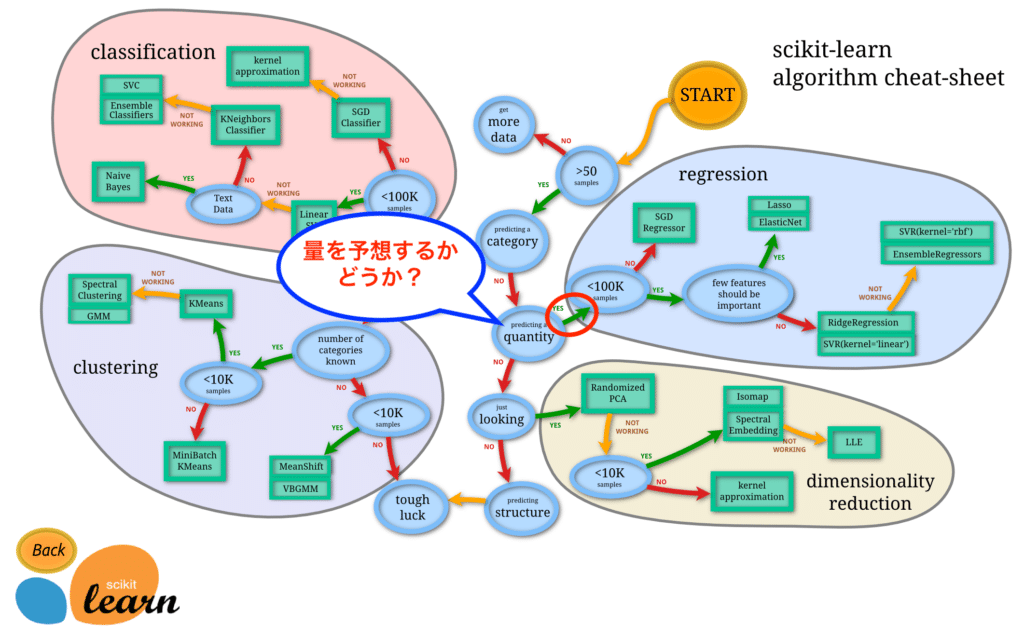
機械学習のモデルのマップを見てみる
iris(アヤメ)のデータセットを機械学習させた時には「サポートベクターマシン」という機械学習のモデルを使いました。
また前回、前々回とボストンの住宅価格を予想した時は「線形回帰」というモデルを使って機械学習させてみました。
ですが、機械学習にはまだまだ他のモデルも存在します。
といいつつもどのモデルを使ったらいいのか分からないというのが正直なところ。
ということで機械学習ライブラリ「Sckit-learn」のウェブサイトを漁ってみました。
それで出てきたのがこちらのページとマップ。
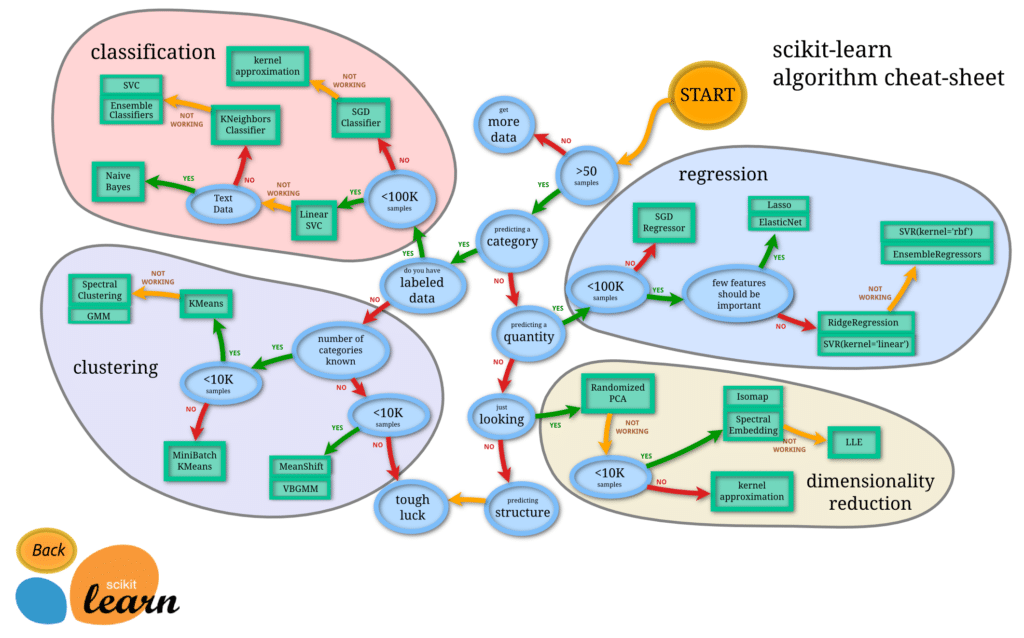
日本語訳は「Qiita」にありましたので、リンクを貼っておきます。

それぞれの質問に対して「Yes」「No」を辿っていくと、適切なモデルにたどり着くというわけです。
ボストン住宅価格にどの機械学習モデルがいいか、マップから検討してみる
それではこの機械学習モデルマップを使って、ボストンの住宅価格のデータセットに適切な機械学習のモデルを選択してみましょう。
まず最初は「50サンプル以上あるかどうか?」という質問です。
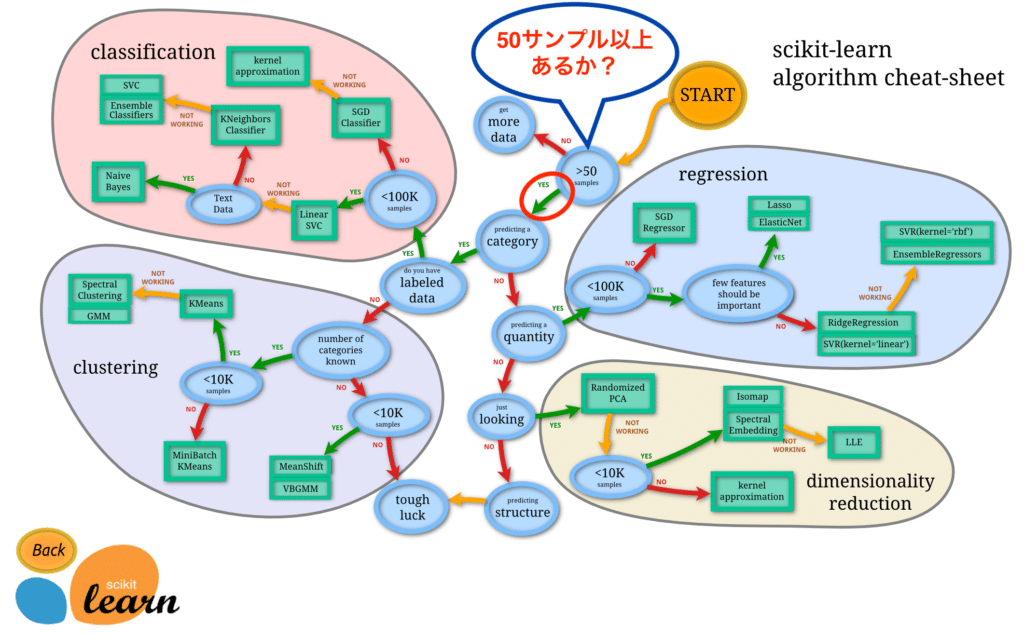
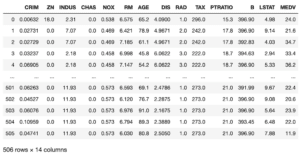
ボストン住宅価格のデータセットにデータは505個ありました。
8割を訓練用のデータとしても404個。
50個以上あるということで「Yes」に進みます。
次は「カテゴリを予想するものかどうか?」という質問です。
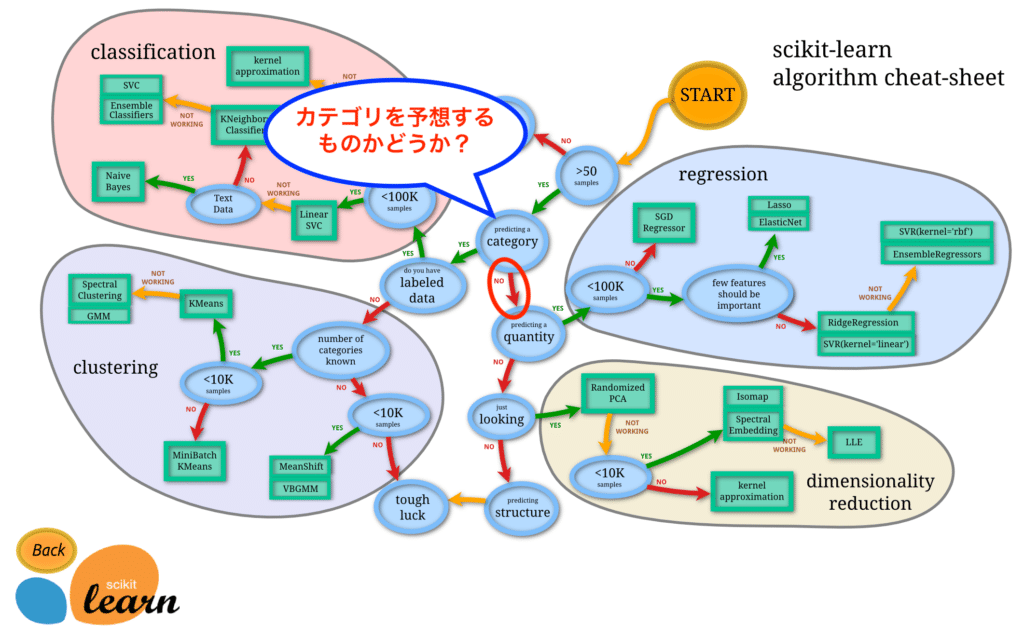
iris(アヤメ)のデータセットのときのようにどの種類かを予想するときには「Yes」です。
しかし今回はボストン市内のある条件の住宅価格を予想したいので「No」です。
次は「量を予想するかどうか?」という質問です。
量というと「何個」とか「何g」とかイメージしてしまいますが、大雑把に「数値」を予想するものと考えましょう。
今回は住宅価格、つまり「数値」を予想するものなので「Yes」です。
次は「データのサンプル数が10万未満かどうか?」という質問です。

数が多くなると処理が大変になるので、違うモデルが推奨されるのでしょう。
ですが今回は先ほど見た通り、全体で505個、8割を訓練用データとしても404個なので「No」に進みます。
次は「少数の特徴量が重要かどうか?」という質問です。
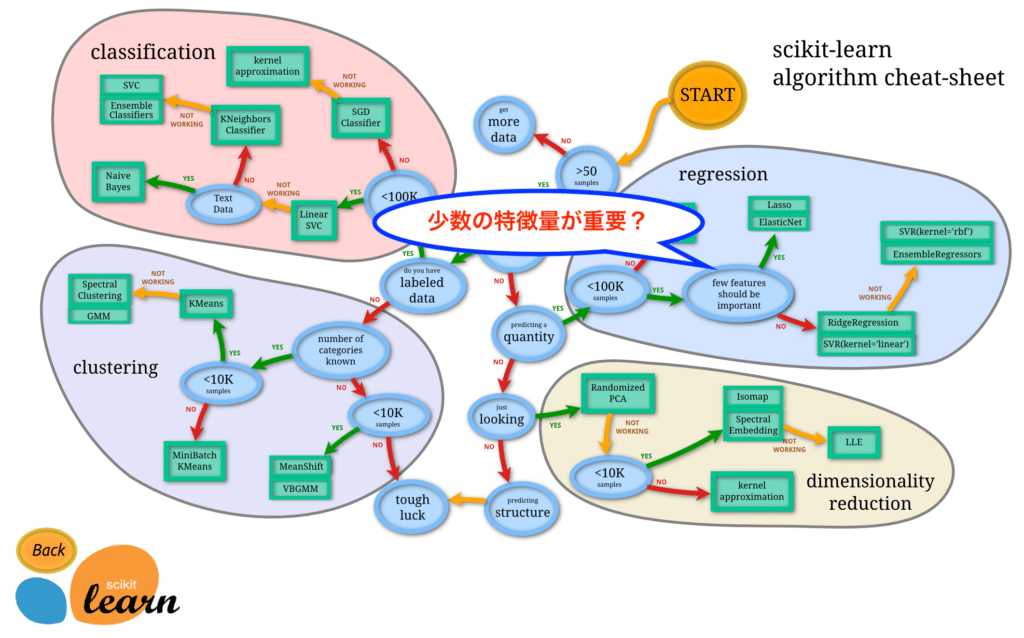
私のイメージ的には「いっぱいある特徴量のうち数個が重要」なら「Yes」、「いくつかの特徴量のうちどれも少しずつ重要」なら「No」ということだと思います。
今回はボストン住宅価格の特徴量のうち、3つの特徴量が重要そうです。
そのため「Yes」と答えたいところですが、読み込ませるデータが重要そうな3つの特徴量なら、どれも少しずつ重要なため「No」とも言えます。
つまり正直ってどちらを選んだらいいか、現時点の私では分からないということ。
ちなみにこの先には、6つの機械学習のモデルが示されています。
- Lasso
- ElasticNet
- RidgeRegression
- SVR(kernel=’linear’)
- SVR(kernel=’rbf’)
- EnsembleRegression
機械学習モデル的には6つですが、SVRはオプションが「linear」か「rbf」かの違いだけのようです。
EnsambleRegressionはこの中にいくつかのモデルがあるようで、ちょっと複雑なので今回はスキップすることにします。
ということでそれぞれの機械学習モデルの勉強がてら、次回から5つの学習モデルを試してみることにしましょう。
また今回の機械学習モデルのマップは今度も使っていくと思うので、どこかに保存しておくのがいいかと思います。
ではでは今回はこんな感じで。
コメント