機械学習ライブラリScikit-learn
前回は機械学習ライブラリScikit-learnのiris(アヤメ)のデータセットを読み込み、中身を読み込んでみました。
今回はirisのデータセットを使って、データを眺めて、どんなデータで機械学習を行うか方針を決めるところまでやってみましょう。
ということでまずはデータの読み込みから。
<セル1>
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.keys())
実行結果
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])今回もJupyter notebookのセルを変えていきますので、セル番号を記載しておきます。
では行ってみましょう。
Pandasのデータフレームに格納
まずはデータセットを扱いやすいように、Pandasのデータフレームに格納していきます。
新しいデータフレームの作成方法はこちらの記事で解説していきます。
まずは「import pandas as pd」でPandasのインポート。
データは「iris.data」、列名は「iris.feature_names」ですので、データフレームの作成方法は「pd.DataFrame(データ, columns=列名のリスト)」となります。
ということでこんな感じ。
<セル2>
import pandas as pd
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df
実行結果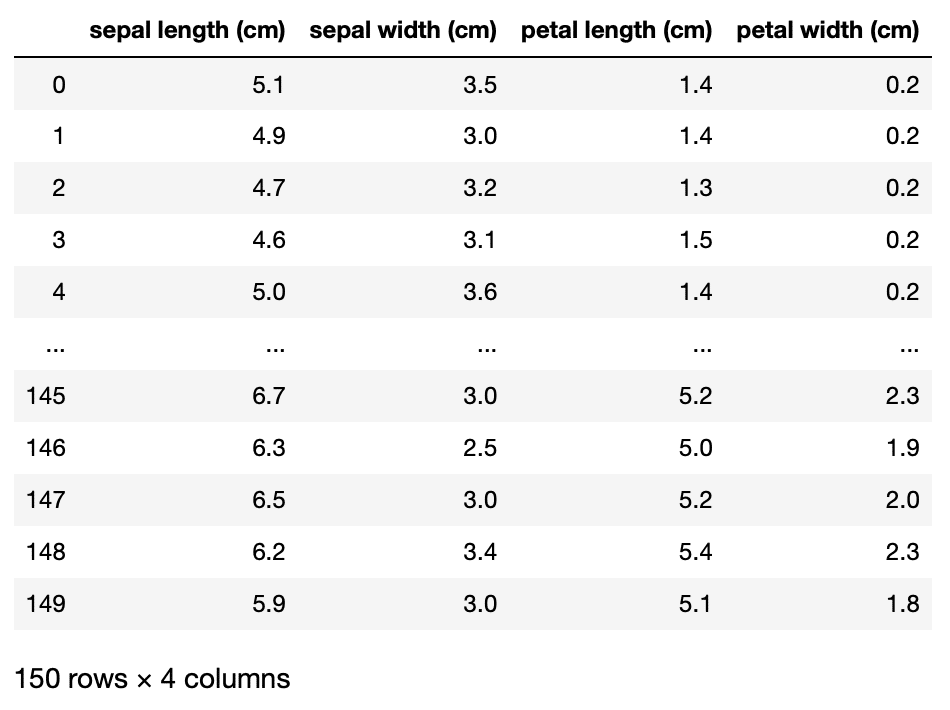
データは150個あり、それぞれに「sepal length (cm)」、「sepal width (cm)」、「petal length (cm)」、「petal width (cm)」の4種類のデータが格納されています。
ただこのデータでは最終的に推測したいデータ「target」が入っていません。
またそのデータは「iris.target」に入っています。
ということで先ほどのデータフレーム「df」に追加します。
追加の方法はこちらの記事で解説していますので、良かったらどうぞ。
<セル2>
import pandas as pd
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df["target"] = iris.target
df
実行結果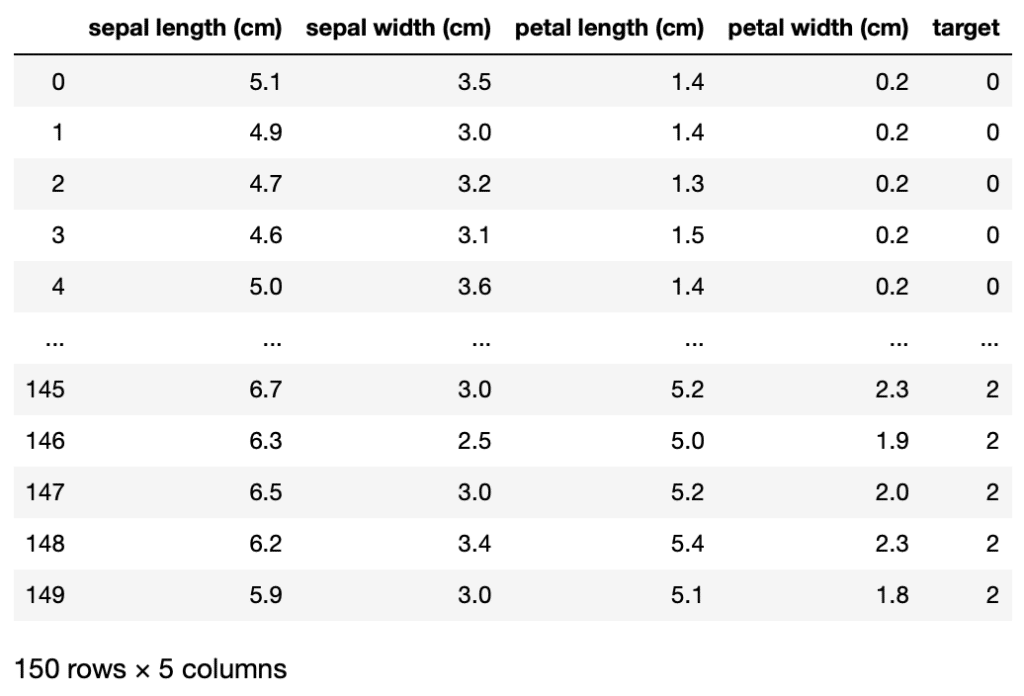
targetの列が追加できました。
欠損値Nanがあるか確認
次にデータに欠損値があるか確認してみましょう。
欠損値の数と何%のデータがNanなのかを調べる関数を前に作成していますので、そちらを使って試してみます。
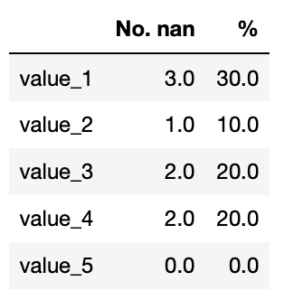
<セル3>
def nan_check(df):
nan_val = df.isnull().sum(axis=0)
total_val = len(df.index)
nan_percent = 100 * nan_val/total_val
nan_df = pd.DataFrame([nan_val, nan_percent], index=["No. nan", "%"])
return nan_df.T
nan_check(df)
実行結果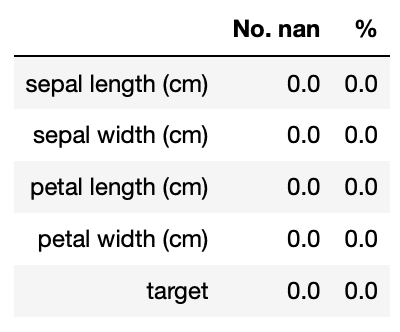
このirisのデータは綺麗で特に欠損値は見当たりませんでした。
Seabornのpairplotでそれぞれのデータの関連を分析
ということで4つのデータがirisの種類を見分けるのに、どんな関連性があるか、seabornのpairplotを描いてみてみましょう。
seabornに関してはこちらの記事で簡単に紹介していますのでこちらの記事もどうぞ。
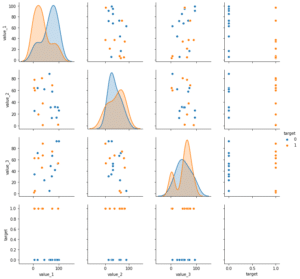
今回は「target」で色分けをしてみましょう。
インポート、マジックコマンド、そしてseabornのコマンドを合わせてこんな感じです。
<セル4>
import seaborn as sns
%matplotlib inline
sns.pairplot(df, hue="target")
実行結果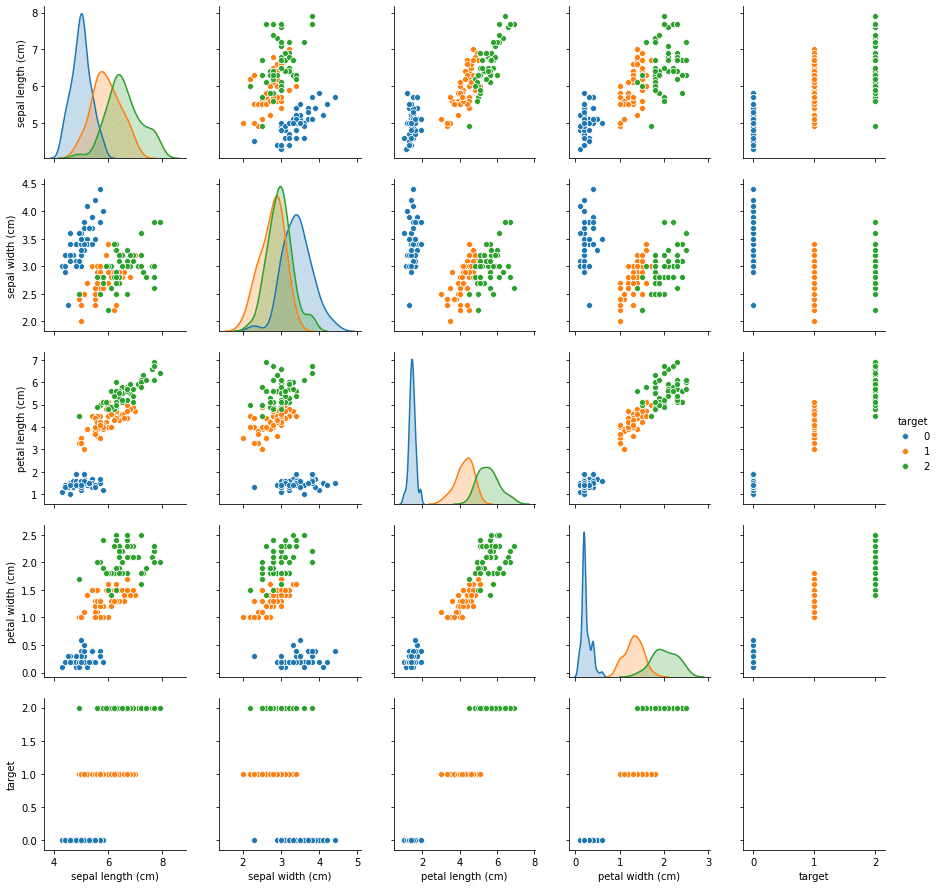
ここでちょっとおかしなことが。
一番右の列と一番下の列は「target」の行と列になりますが、「target」のデータは色分けしているので、正直この行と列は入りません。
実はpairplotは読み込んだデータフレームのうち、数値データのものを並べていく性質があるのです。
ということでtargetの値をそれぞれのアヤメの種類に書き換えてみましょう。
targetのデータを書き換えて、再度pairplotで分析
まずはtargetの列の数値データを、アヤメの種類、つまり文字データに書き換えます。
そのときはこんな感じのコマンドで書き換えます。
df["target"][df["target"] == 0] = "setosa"最初の「df[“target”]」で「target」の列を指定します。
そして次の「[df[“target”] == 0]」で「target」の列のうち、「0」のものを抽出します。
最後に「= “setosa”」で先ほどの「df[“target”][df[“target”] == 0]」で抽出したデータを「”setosa”」に書き換えます。
同じようにして、「1」、「2」のデータも書き換えてみましょう。
<セル5>
df["target"][df["target"] == 0] = "setosa"
df["target"][df["target"] == 1] = "sersicolor"
df["target"][df["target"] == 2] = "virginica"
df
実行結果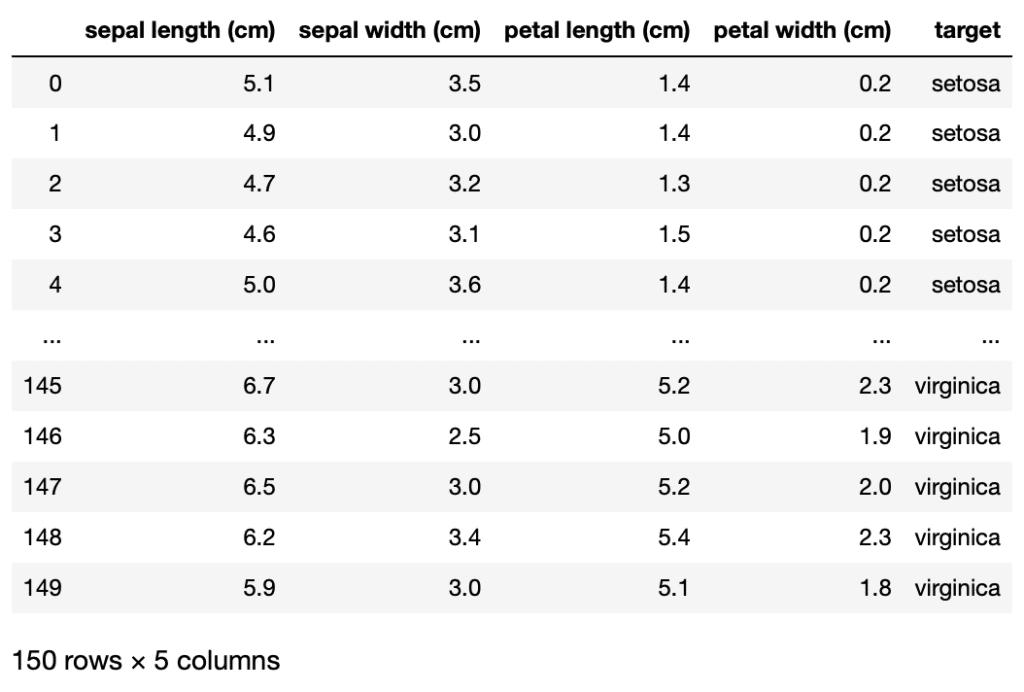
targetのデータを書き換えることができました。
ということでもう一度seabornのpairplotを描いてみましょう。
先ほどserbornのインポートをしているので、今回はインポートは必要ありません。
<セル6>
sns.pairplot(df, hue="target")
実行結果ここで重要なのはそれぞれの色の点、つまりそれぞれアヤメの種類が分かれているかどうかということです。
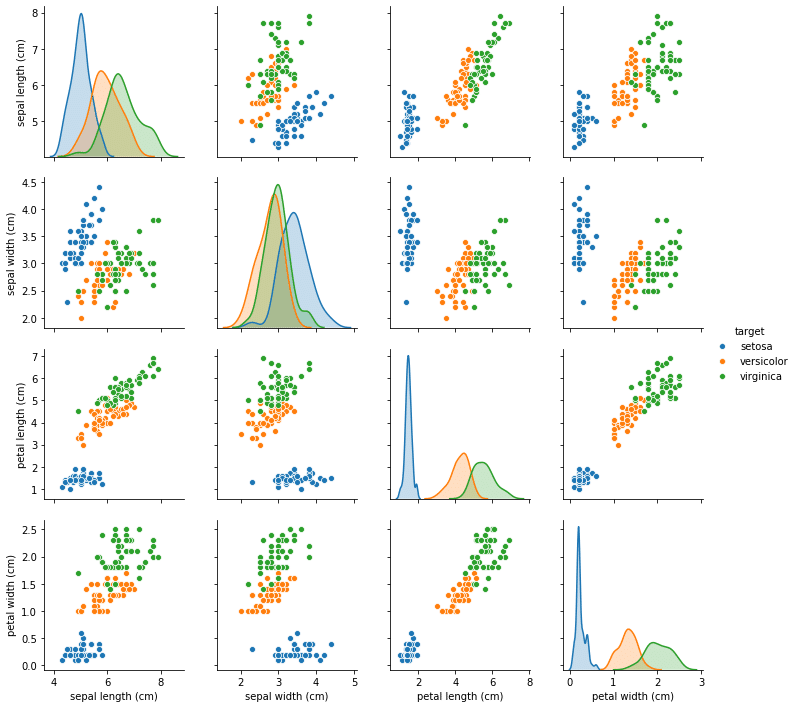
例えば「sepal length」と「sepal width」のデータを示している一番上の行、左から2番目(もしくは一番左の行、上から2番目)は橙色の点「versicolor」と緑色の点「virginica」は重なっているように見えます。
また「petal length」と「petal width」のデータはどこを見ても結構分かれているように見えます。
ということで次回、初めての機械学習を行なっていきますが、方針としては「4種類全てのデータを使う」というのと「petal lengthとpetal widthのデータを使う」という2つの方針で機械学習してみることにしましょう。
ではでは今回はこんな感じで。
コメント