データ解析支援ライブラリPandas
前回はデータ解析支援ライブラリPandasで欠損値nanを含む行や列を削除する方法を解説しました。
ここまでPandasを使って色々データを扱う方法を解説してきました。
それでだいぶPandasのデータフレームに関して理解が深まってきたことと思います。
そんなPandasのデータフレームのなかで、まだ解説していないのが、実は一番最初の段階かもしれないこと。
そう、新しくデータフレームを作るということです。
ということで今回は新しくデータフレームを作る方法を解説していきたいと思います。
まずは準備ですが、今回はとりあえずPandasをインポートするというだけです。
import pandas as pdそれでは始めていきましょう。
空のデータフレームを作成する方法
最初は全く何も入っていないデータフレームを作成してみましょう。
新規でデータフレームを作成する場合は、「データフレーム名 = pd.DataFrame()」です。
import pandas as pd
df = pd.DataFrame()
df
実行結果
_データフレームが空なので、「_」という表示がされました。
ちなみにprint関数で作成したデータフレームを表示してみたら、こうなりました。
import pandas as pd
df = pd.DataFrame()
print(df)
実行結果
Empty DataFrame
Columns: []
Index: []より空だということが分かりやすいですね。
空のデータフレームにデータを追加する方法
次にからのデータフレームにデータを追加してみましょう。
データフレームにデータを追加する方法は前に解説していて、行名や列名を指定して追加する方法と列を追加するassign、またSeriesとappendを使って追加する方法がありました。
列名、行名を指定して追加する方法
まずは行名、列名を指定して追加してみましょう。
import pandas as pd
df = pd.DataFrame()
df["A"] = [1, 2, 3, 4, 5]
df
実行結果
列名を指定した場合は、無事追加されました。
次に行名を指定してみましょう。
import pandas as pd
df = pd.DataFrame()
df.loc["A"] = [1, 2, 3, 4, 5]
df
実行結果
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-28-20c3812e8ddc> in <module>
3 df = pd.DataFrame()
4
----> 5 df.loc["A"] = [1, 2, 3, 4, 5]
6
7 df
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexing.py in __setitem__(self, key, value)
203 key = com.apply_if_callable(key, self.obj)
204 indexer = self._get_setitem_indexer(key)
--> 205 self._setitem_with_indexer(indexer, value)
206
207 def _validate_key(self, key, axis: int):
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexing.py in _setitem_with_indexer(self, indexer, value)
404
405 if missing:
--> 406 return self._setitem_with_indexer_missing(indexer, value)
407
408 # set
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexing.py in _setitem_with_indexer_missing(self, indexer, value)
633 if not len(self.obj.columns):
634 # no columns and scalar
--> 635 raise ValueError("cannot set a frame with no defined columns")
636
637 if isinstance(value, ABCSeries):
ValueError: cannot set a frame with no defined columns行名を指定した場合はエラーとなってしまいました。
エラーとしてはカラム(列名)を指定していないということでした。
assignで列を追加する方法
次にassignで列を追加してみましょう。
import pandas as pd
df = pd.DataFrame()
test_series = pd.Series([1, 2, 3, 4, 5])
df = df.assign(A = test_series)
df
実行結果
Seriesとappendで行を追加する方法
次にSeriesとappendのコマンドを使って行を追加してみましょう。
import pandas as pd
df = pd.DataFrame()
test_series = pd.Series([1, 2, 3, 4, 5], name="A")
df = df.append(test_series)
df
実行結果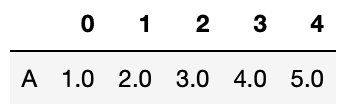
行を追加することができました。
行名、列名のみをもったデータフレームを作成する方法
次に行名、列名のみをもち、データをもっていないデータフレームを作成してみましょう。
先ほど空のデータフレームを作成する方法として「データフレーム名 = pd.DataFrame()」を紹介しました。
行名、列名をもった状態でデータフレームを作成するには、このオプションとして「index=行名のリスト」、「columns=列名のリスト」を追加します。
ということで「データフレーム名 = pd.DataFrame(index=行名のリスト, columns=列名のリスト)」となります。
試してみましょう。
import pandas as pd
df = pd.DataFrame(index=["A", "B", "C"], columns=["x", "y", "z"])
df
実行結果
行名、列名が表示され、それぞれのデータは欠損値NaNというデータフレームを作成することができました。
行名、列名、データをもったデータフレームを作成する方法
では次に行名、列名だけではなく、最初からデータももったデータフレームを作成してみましょう。
その場合は、オプションにデータのリストを追加します。
ということで先ほどの行名、列名と合わせて、「データフレーム名 = pd.DataFrame(データ, index=行名のリスト, columns=列名のリスト)」となります。
import pandas as pd
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
df = pd.DataFrame(data, index=["A", "B", "C"], columns=["x", "y", "z"])
df
実行結果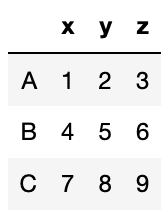
全部入ったデータフレームが作成できました。
ちなみにデータの数が足りないと、欠損値NaNとなります。
先ほどのデータで最後の「9」を削除してみましょう。
import pandas as pd
data = [[1, 2, 3], [4, 5, 6], [7, 8]]
df = pd.DataFrame(data, index=["A", "B", "C"], columns=["x", "y", "z"])
df
実行結果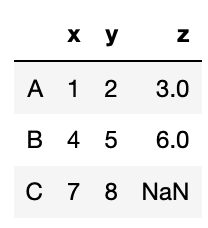
ただしデータ全てにおいて、行や列の数が合わないとエラーとなります。
例えば行の数が合わない例として、[7, 8, 9]を削除してみます。
import pandas as pd
data = [[1, 2, 3], [4, 5, 6]]
df = pd.DataFrame(data, index=["A", "B", "C"], columns=["x", "y", "z"])
df
実行結果
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/internals/managers.py in create_block_manager_from_arrays(arrays, names, axes)
1694 blocks = form_blocks(arrays, names, axes)
-> 1695 mgr = BlockManager(blocks, axes)
1696 mgr._consolidate_inplace()
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/internals/managers.py in __init__(self, blocks, axes, do_integrity_check)
142 if do_integrity_check:
--> 143 self._verify_integrity()
144
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/internals/managers.py in _verify_integrity(self)
344 if block._verify_integrity and block.shape[1:] != mgr_shape[1:]:
--> 345 construction_error(tot_items, block.shape[1:], self.axes)
346 if len(self.items) != tot_items:
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/internals/managers.py in construction_error(tot_items, block_shape, axes, e)
1718 raise ValueError(
-> 1719 "Shape of passed values is {0}, indices imply {1}".format(passed, implied)
1720 )
ValueError: Shape of passed values is (2, 3), indices imply (3, 3)
(以下省略)列の数が合わない例として、「3」「6」「9」を削除してみます。
import pandas as pd
data = [[1, 2], [4, 5],[7, 8]]
df = pd.DataFrame(data, index=["A", "B", "C"], columns=["x", "y", "z"])
df
実行結果
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/internals/construction.py in _list_to_arrays(data, columns, coerce_float, dtype)
499 result = _convert_object_array(
--> 500 content, columns, dtype=dtype, coerce_float=coerce_float
501 )
/opt/anaconda3/lib/python3.7/site-packages/pandas/core/internals/construction.py in _convert_object_array(content, columns, coerce_float, dtype)
582 "{col:d} columns passed, passed data had "
--> 583 "{con} columns".format(col=len(columns), con=len(content))
584 )
AssertionError: 3 columns passed, passed data had 2 columns
(以下省略)行名、列名を指定せず、データのみもったデータフレームを作成する方法
では行名、列名を指定せず、データのみ指定するとどうなるでしょうか。
試してみましょう。
import pandas as pd
data = [[1, 2, 3], [4, 5, 6],[7, 8, 9]]
df = pd.DataFrame(data)
df
実行結果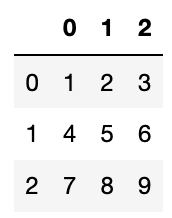
行名、列名は自動で「0, 1, 2」と数字が振られました。
今回はデータフレームを作成する方法を解説しました。
ただ通常データはCSVファイルのようなものから読み込むことが多いと思うので、今回のようなデータフレームの作成方法はあまり使わないかもしれません。
それでもデータフレームへの理解を深めるため、今回解説してみました。
次回はPandasからグラフを表示する方法を解説します。
ということで今回はこんな感じで。
コメント