データ解析支援ライブラリPandas
前回はデータ解析支援ライブラリPandasで合計値、平均値、中央値、最大値、最小値、標準偏差を計算する方法を解説しました。
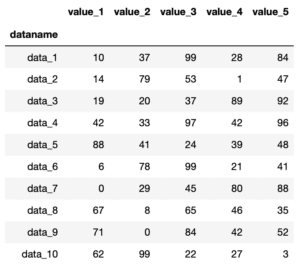
このように色々な値を計算できるようになると、これらの値をPandasで出力できる表に追加していきたいと考えることでしょう。
もちろんそういったことも可能なので、今回は新しく計算したデータを新しい行や列として追加するということをしてみたいと思います。
ただ結構ややこしいので、まずはなるべく簡単な方法から解説していきます。
ということで今回もまずは準備から。
使用するデータは、いつものごとく自作のダミーデータ作成プログラムで作ったこちら。
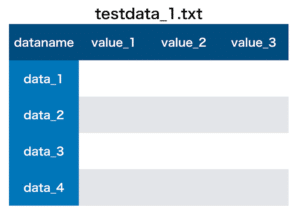
データの読み込みはこんな感じです。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df
実行結果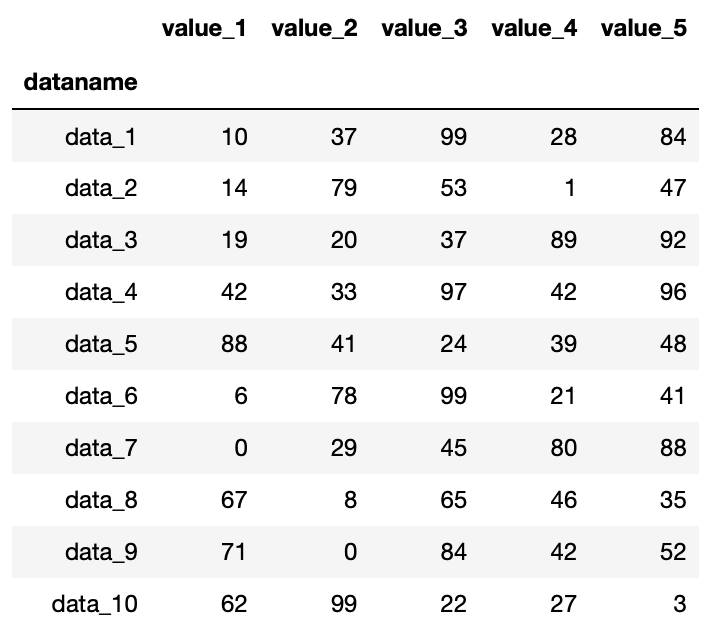
ちなみに今回、変数df、つまり表データ全体のことをデータフレーム(DataFrame)と呼びますのでご注意ください。
ではでは始めていきましょう。
列を追加する方法
まずは列を追加する方法から解説をしていくことにしましょう。
先ほどのデータフレームの一番右にそれぞれのデータの平均値を追加してみます。
ということでまずは前回解説した平均値の計算から。
平均値は「.mean()」で計算でき、それぞれの行の平均値を出したいときは、オプションとして「axis=1」(もしくはaxis=”columns”)を追加します。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
average_data = df.mean(axis=1)
print(average_data)
df
実行結果
dataname
data_1 51.6
data_2 38.8
data_3 51.4
data_4 62.0
data_5 48.0
data_6 49.0
data_7 48.4
data_8 44.2
data_9 49.8
data_10 42.6
dtype: float64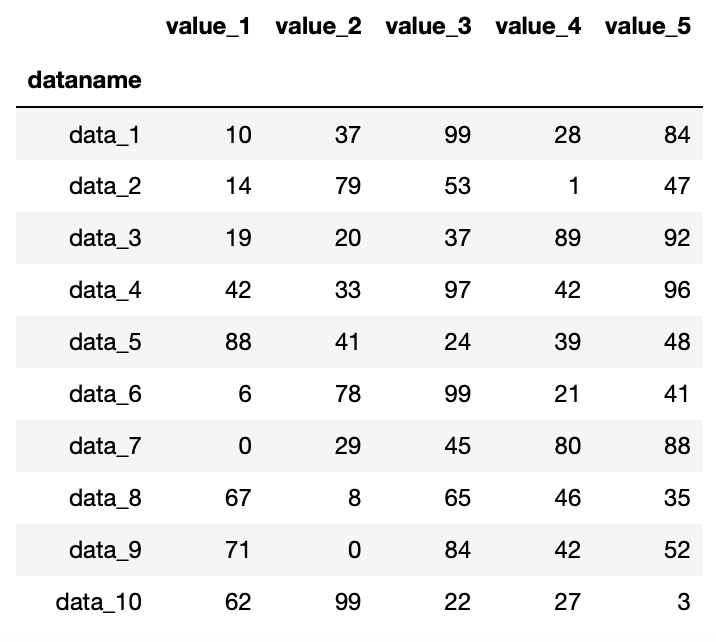
もちろん表の中にはまだ平均値は追加されていません。
新しい列に追加するには「データフレーム名[“列名”] = 追加する列データ」とします。
今回の場合、dfというデータフレームに対し、平均値「Average」という列を追加するので、df[“Average”] = df.mean(axis=1)となります。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df["Average"] = df.mean(axis=1)
df
実行結果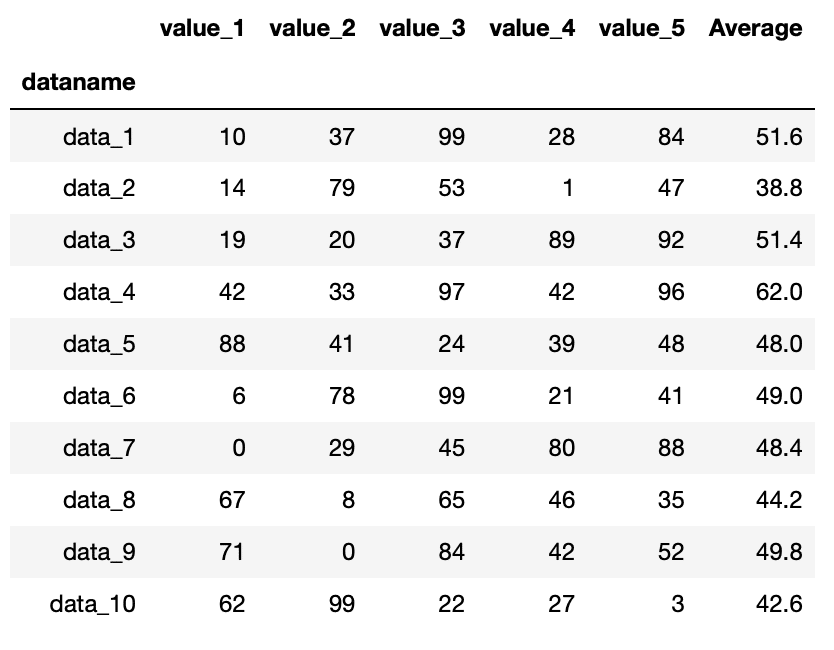
追加できました。
列を追加する際、すでに存在する列名を使った場合
列を追加する時にやりがちなミスとして、既に存在している列名を使ってしまった場合、どうなるのでしょうか?
先ほどの例では「Average」という列名は他に使っていない新しい名前でしたが、間違えて「value_5」という既に存在している列名を使ってしまったとしましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df["value_5"] = df.mean(axis=1)
df
実行結果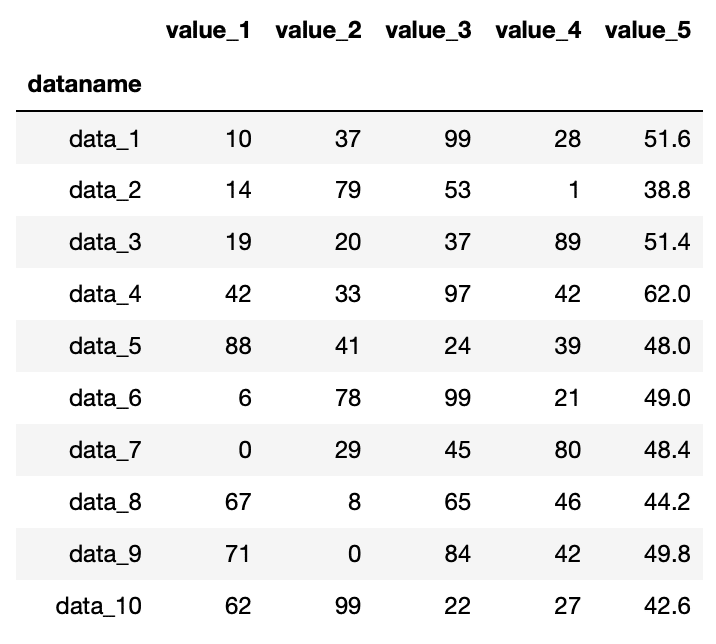
「value_5」の列の値が平均値に変わってしまいました。
これは表示として変わってしまったのでしょうか?それとも「value_5」という列データが書き換えられてしまったのでしょうか?
確かめるために「value_5」の列データを呼び出してみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df["value_5"] = df.mean(axis=1)
print(df["value_5"])
実行結果
dataname
data_1 51.6
data_2 38.8
data_3 51.4
data_4 62.0
data_5 48.0
data_6 49.0
data_7 48.4
data_8 44.2
data_9 49.8
data_10 42.6
Name: value_5, dtype: float64この結果によると、既に存在する列名を使ってしまうと、列データが上書きされてしまうようです。
ということで新しい列を追加する場合は、名前に注意しましょう。
行を追加する方法
次に行を追加する方法を解説していきます。
せっかくなので平均値の列を追加したデータフレームに、さらに新しい行としてそれぞれの列の合計値を追加してみましょう。
ちなみに合計値は「.sum()」で追加でき、今回は行なのでオプションは必要ありません。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df["Average"] = f.mean(axis=1)
sum_data = df.sum()
print(sum_data)
df
実行結果
value_1 379.0
value_2 424.0
value_3 625.0
value_4 415.0
value_5 586.0
Average 485.8
dtype: float64各列の合計値は計算できましたが、まだ表には追加されていません。
表に新しい行を追加するには、「データフレーム名.loc[“行名”] = 新しい行データ」となります。
つまりdfというデータフレームに対し、合計値「Sum」という行を追加するので、「df.loc[“Sum”] = df.sum()」となります。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df["Average"] = df.mean(axis=1)
df.loc["Sum"] = df.sum()
df
実行結果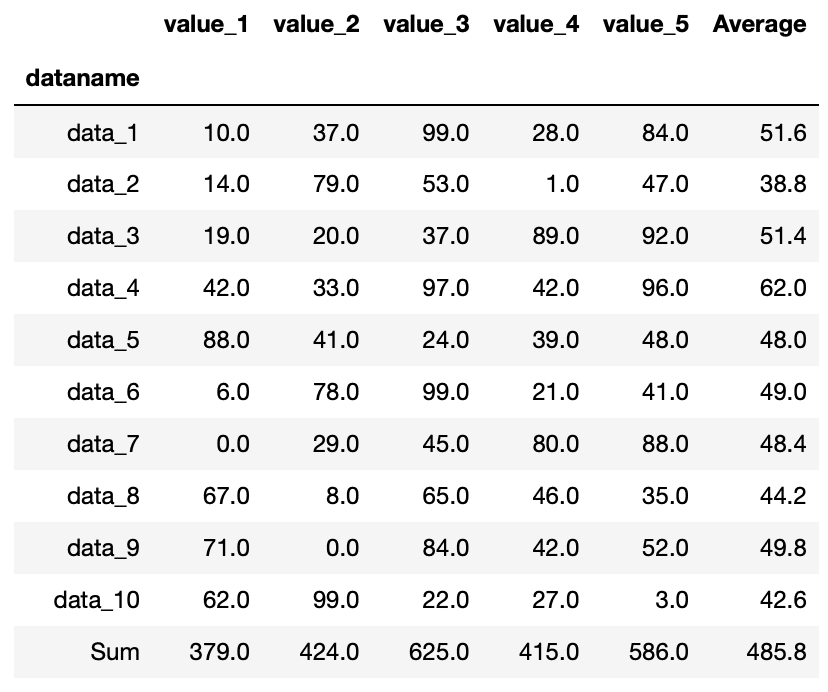
ちなみに行を追加する場合でも、既に存在する行名を使ってしまうと、その行のデータが上書きされてしまうので注意してください。
例えば行名に「Sum」という名前ではなく、既に存在する「data_10」という名前を使ったとするとこんな感じです。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df["Average"] = df.mean(axis=1)
df.loc["data_10"] = df.sum()
df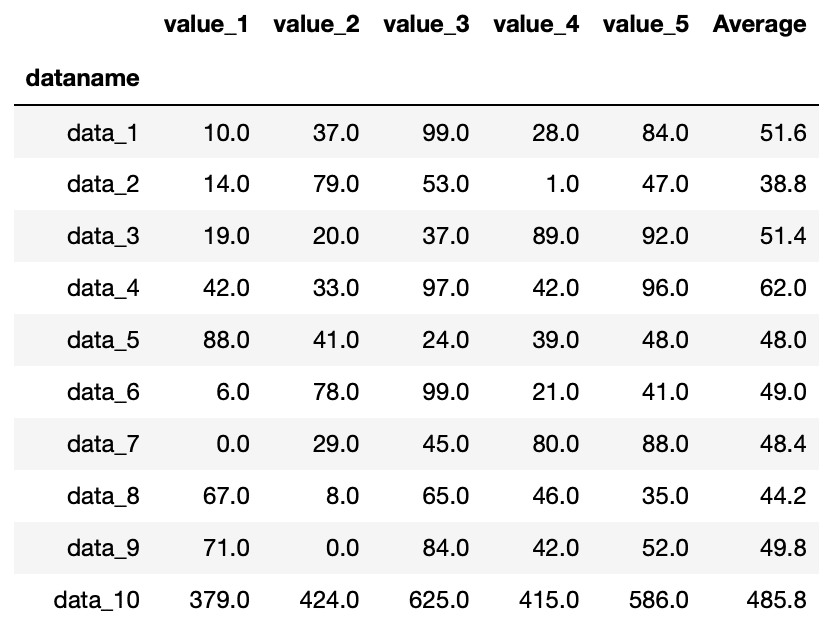
新しい「行名」に既にある「列名」と同じ名前をつけてしまった場合
さらに「行名」に既にある「列名」と同じ名前をつけてしまった場合はどうなるでしょうか?
例えば新しい合計値の行名に「Sum」ではなく、既にある列名「value_5」という名前をつけてみましょう。
import pandas as pd
df = pd.read_csv("python-pandas-2_data.txt", index_col=0)
df["Average"] = df.mean(axis=1)
df.loc["value_5"] = df.sum()
df
実行結果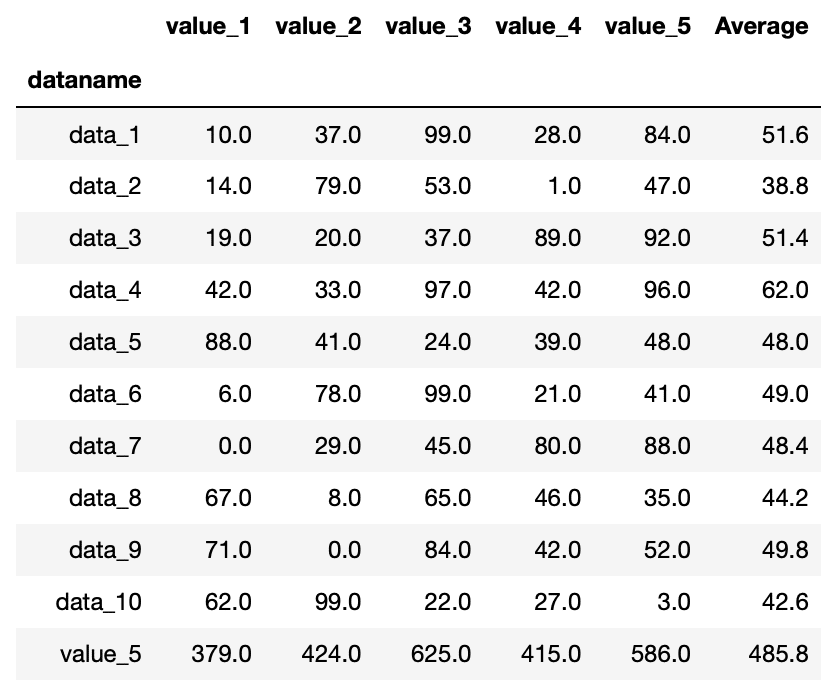
新しく「value_5」という行ができました。
つまり気をつけるべきは「新しい列を追加する場合は、列名が既にあるかどうか」、「新しい行を追加する場合は、行名が既にあるかどうか」ということです。
ということで今回はPandasのデータフレームに行や列を追加する基本的な方法を解説しました。
ただ実は追加する方法はまだ他にもありますし、気をつけなければいけないこともあります。
そういったことは次回に解説していきたいと思います。
ではでは今回はこんな感じで。
コメント