機械学習ライブラリScikit-learn
前回は機械学習ライブラリScikit-learnのiris(アヤメ)のデータセットをPandasのデータフレームに格納し、seabronのpairplotでデータ間の関連性を見てみました。
今回はScikit-learnのライブラリに含まれている機械学習のモデル、サポートベクターマシンというものを使ってみることにします。
サポートベクターマシンがどういう機械学習の原理なのかは他のサイトにお願いすることにします。
ということでまずはWikipedia。

もう一つはこちらのサイト。
ものすごく単純化して解説すると、まずはデータのうち二つの値を軸にプロットします。
分類したいものが分けられるように線を引きます。
これをもとにデータから分類結果を推測するというのがサポートベクターマシンの考え方のようです。
サポートベクターマシンがなんとなく分かったところで準備を始めていきましょう。
使うデータはScikit-learnのirisのデータで、前回処理したところまではまとめてしまいましょう。
今回もセルをどんどん変えていきますので、セル番号を振っておきます。
<セル1>
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df["target"] = iris.target
df["target"][df["target"] == 0] = "setosa"
df["target"][df["target"] == 1] = "versicolor"
df["target"][df["target"] == 2] = "virginica"
df
実行結果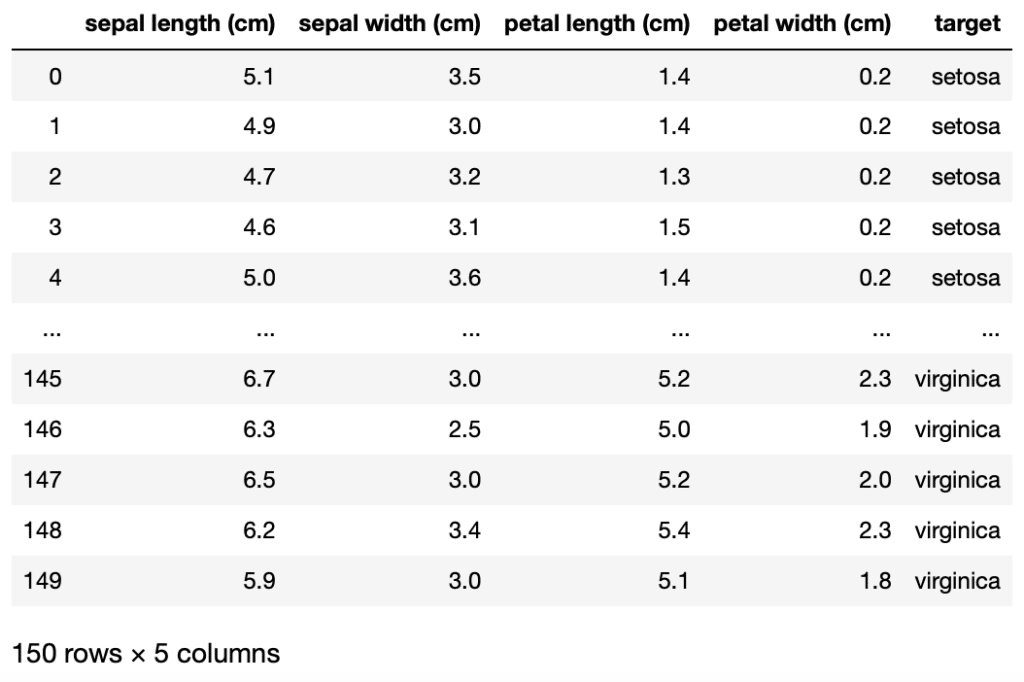
データの選択と格納
まずは機械学習に用いるデータを選択します。
前回、seabornのpairplotの結果から、「4種類全てのデータを使う」と「petal lengthとpetal widthのデータを使う」ので比較してみようと方針を決めました。
ということでまずは「4種類全てのデータ」を使い、機械学習してみることにします。
そこで全4種類のデータを変数「x」、ターゲットを変数「y」に格納します。
Pandasの列データの取得指定方法はこちらの記事で解説していますので、こちらの記事もどうぞ。
<セル2>
x = df.iloc[:, [0, 1, 2, 3]]
y = df.loc[:, "target"]変数xを全部列名から指定しても大丈夫です。
<セル2 列名バージョン>
x = df.loc[:, ["sepal length (cm)", "sepal width (cm)", "petal length (cm)", "petal width (cm)"]]
y = df.loc[:, "target"]訓練用データとテスト用データに分割
次にデータを機械学習で訓練させるデータと、その訓練が正しくできているかを検証するためのデータに分割します。
そこでsklearn.model_selectionライブラリにあるtrain_test_splitというコマンドを使用します。
train_test_splitの使い方は「訓練用Xデータ, テスト用Xデータ, 訓練用Yデータ, テスト用Yデータ = train_test_split(xデータ, Yデータ, test_size=テスト用データのサイズ, train_size=訓練用データのサイズ)」になります。
ということでインポートとデータの分割はこんな感じ。
<セル3>
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)ちなみに「テスト用データのサイズ」「訓練用データのサイズ」は比率を小数点で入力します。
また両方のデータサイズを足した値が最大で「1」以下である必要があります。
両方のデータサイズを足した値が1より大きい場合はエラーがでます。
<セル3 失敗例>
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, train_size=0.8)
実行結果
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-30-74154932dbf4> in <module>
1 from sklearn.model_selection import train_test_split
2
----> 3 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, train_size=0.8)
/opt/anaconda3/lib/python3.7/site-packages/sklearn/model_selection/_split.py in train_test_split(*arrays, **options)
2098 n_samples = _num_samples(arrays[0])
2099 n_train, n_test = _validate_shuffle_split(n_samples, test_size, train_size,
-> 2100 default_test_size=0.25)
2101
2102 if shuffle is False:
/opt/anaconda3/lib/python3.7/site-packages/sklearn/model_selection/_split.py in _validate_shuffle_split(n_samples, test_size, train_size, default_test_size)
1750 'The sum of test_size and train_size = {}, should be in the (0, 1)'
1751 ' range. Reduce test_size and/or train_size.'
-> 1752 .format(train_size + test_size))
1753
1754 if test_size_type == 'f':
ValueError: The sum of test_size and train_size = 1.1, should be in the (0, 1) range. Reduce test_size and/or train_size.ちゃんと分割できたのか、それぞれのデータのサイズを確認してみましょう。
<セル3 データサイズ確認例>
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
print(len(x), len(y))
print(len(x_train), len(x_test))
print(len(y_train), len(y_test))
実行結果
150 150
120 30
120 30元のデータのサイズが150個、訓練用データが120個、テスト用データが30個となっています。
訓練用データサイズは0.8なので、つまり150×0.8=120、テスト用データサイズは0.2なので、つまり150×0.2=30で合っていますね。
サポートベクターマシンで機械学習させる
それではサポートベクターマシンという手法で機械学習をさせてみましょう。
まずはサポートベクターマシンのコマンドをインポートします。
from sklearn.svm import SVC次にモデルの条件を決定し、変数に格納します。
今回はとりあえずサポートベクターマシンのデフォルトのモデルを使用することにします。
model = SVC()もしモデルの条件を変える時は括弧の中に条件を書き込むことになります。
そしてモデルに対して訓練用のデータを読み込み学習させます。
model.fit(x_train, y_train)ということでここまででこんな感じになります。
<セル4>
from sklearn.svm import SVC
model = SVC()
model.fit(x_train, y_train)
実行結果
/opt/anaconda3/lib/python3.7/site-packages/sklearn/svm/base.py:193: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning.
"avoid this warning.", FutureWarning)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='rbf', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)実行してみたら、警告(warning)が出ました。
エラーではないので、実行されているのですが、どうやらデフォルトのオプションの値が将来、「auto」から「scale」に変わるとのことです。
どういう値かまだよく分かりませんが、「auto」か「scale」を指定しておくと警告を出さないようにできるようです。
毎回これだけ長々と出るのも面倒なので、その点だけ修正しておきましょう。
<セル4 修正版>
from sklearn.svm import SVC
model = SVC(gamma="auto")
model.fit(x_train, y_train)
実行結果
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)警告は表示されなくなりました。
実行結果として表示されているのは、サポートベクターマシンのオプションに何が選択されているかということ、つまりこれがモデルの条件になります。
またそのうちに色々と変えて試してみましょう。
今回はとりあえずこのまま進めていきます。
予想して、正答率を計算してみる
これでサポートベクターマシンでの機械学習は完了したので、先ほど分割したテスト用のデータを使って、どれくらいの正答率となるか確認してみましょう。
正答率を計算するのに「accuracy_score」というコマンドを使用しますので、まずはインポートします。
from sklearn.metrics import accuracy_scoreということでテスト用のデータを使って、アヤメの種類を予想してみます。
そのときには「予想した答え=モデル名.predict(予想するためのデータ)」とします。
ということでこんな感じ。
pred_y = model.predict(x_test)そして「accuracy_score(答え、予想した答え)」で正答率を計算します。
accuracy_score(y_test, pred_y)ということでまとめてみるとこんな感じになります。
<セル5>
from sklearn.metrics import accuracy_score
pred_y = model.predict(x_test)
print(accuracy_score(y_test, pred_y))
実行結果
0.966666666666666796.7%の正解率だったようです。
ただもしかしたら皆さんが試したときには違う正解率が出ているかもしれません。
それは先ほどデータを訓練用とテスト用のデータに分割しましたが、その際訓練用、テスト用のデータはそれぞれランダムにピックアップされていきます。
つまりそのデータのピックアップされるデータによって正答率が少しずつ異なるということです。
ということで次のセルを使って試してみましょう。
<セル6>
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
for i in range(10):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = SVC(gamma="auto")
model.fit(x_train, y_train)
pred_y = model.predict(x_test)
print(accuracy_score(y_test, pred_y))
実行結果
1.0
0.9666666666666667
0.9333333333333333
1.0
0.9666666666666667
1.0
0.9333333333333333
0.9666666666666667
1.0
0.9このプログラムではデータを分割して、同じ条件のサポートベクターマシンで学習させ、予想し、正解率を計算するということを10回行なっています。
元のデータは同じですが、結果が異なるというので、先ほど解説した通り、データの選ばれかたによって正解率が異なるということです。
では次に予想された答えを見てみましょう。
せっかくなので予想用のデータと並べてみますが、30個全部表示するのは大変なので「.head()」コマンドを使って上から10個だけ表示させてみます。
<セル7>
x_test["target"] = pred_y
x_test.head(10)
実行結果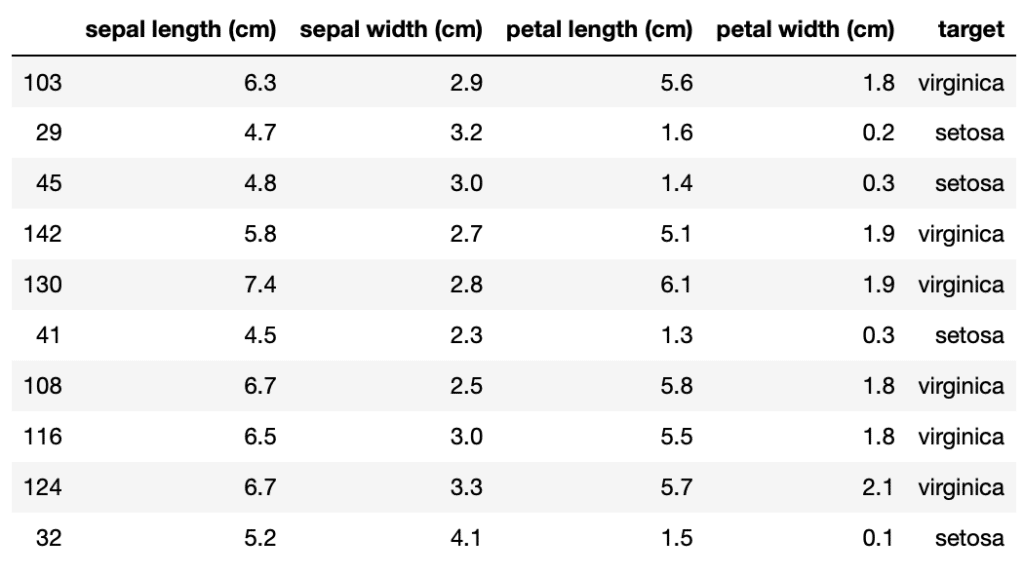
これで初めての機械学習は終了です。
今回は「4種全てのデータを使い」機械学習させてみましたが、次回はより分類がはっきりと分かれている「petal length」と「petal width」の2種のデータを使って機械学習させてみたいのですが、その前にどのように判定しているのか可視化してみましょう。
そうすればもう少しサポートベクターマシンのことが分かるようになると思います。
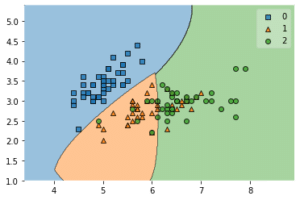
ということで今回はこんな感じで。
コメント