機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnの手書き数字のデータセットを使って、EnsembleClassifiersを試してみました。

今回は前にLinearSVCモデルを使って自分で用意した数字を予想させたように、数字ではない画像を使って予想させたらどんな予想が返ってくるのか試してみたいと思います。
なので基本的にはこの2つの記事をもとに試していきます。
まずは準備
今回は数字ではない画像として、「A」、「B」、「C」、「D」、「E」の5つのアルファベットの画像を用意しました。
そしてファイルはZipで圧縮されているので展開したのち、こんな感じに配置します。
自分で画像ファイルを用意したい方はこちらの記事を参考にしてください(ただしMacに限る)。
ここからプログラミングです。
プログラムの詳細はこちらの記事を参考にしてください。
ということでこんな感じ。
<セル1>
from PIL import Image, ImageOps
import numpy as np
img = Image.open("./alphabet/A.png")
img_gray = ImageOps.invert(img.convert("L").resize((8,8)))
img_array = np.array(img_gray)
print(img_array)
実行結果
[[ 0 0 0 22 23 0 0 0]
[ 0 0 0 44 50 5 0 0]
[ 0 0 13 31 17 27 0 0]
[ 0 0 42 26 18 45 0 0]
[ 0 5 52 30 30 52 3 0]
[ 0 25 23 0 0 30 17 0]
[ 0 21 6 0 0 8 10 0]
[ 0 0 0 0 0 0 0 0]]ここでの変更点はファイルの読み込み先です。
まずは「A」の画像ファイルを読み込ませるため、「img = Image.open(“./alphabet/A.png”)」として「alphabet」フォルダの「A.png」を指定しています。
<セル2>
import matplotlib.pyplot as plt
plt.matshow(img_array)
実行結果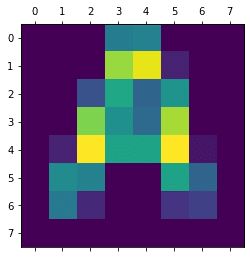
<セル3>
from sklearn.datasets import load_digits
digits = load_digits(as_frame=True)
digits.frame
実行結果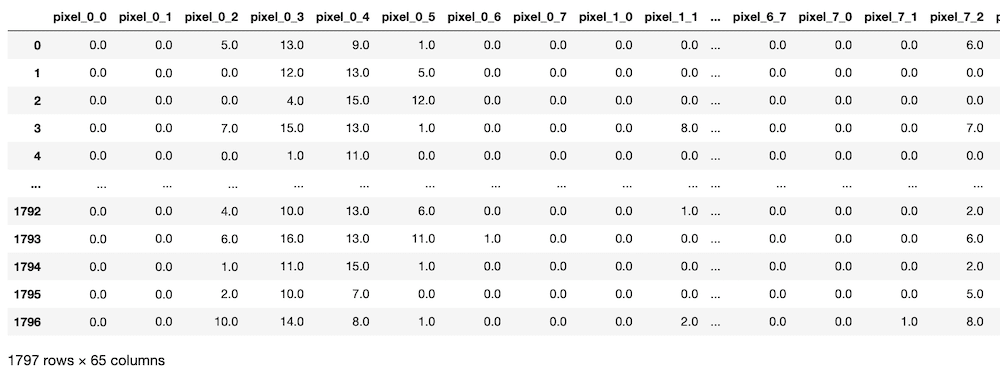
<セル4>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = digits.frame.iloc[:, 0:-1]
y = digits.frame.iloc[:, -1]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=1000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.9527777777777777<セル5>
img_data = img_array.reshape(-1, 64)
result = model.predict(img_data)
print(result)
[4]これでもう「A」の画像を使って予想した答えが出てしまいました。
答えは「4」だそうです。
「A」という画像を学習させていないので、Aの画像に近いということで「4」がでてきたということでしょう。
ちなみに次からは<セル3><セル4>はスキップしても大丈夫です。
A、B、C、D、Eの画像を試してみた
再度になりますが、せっかくなので「A」から。
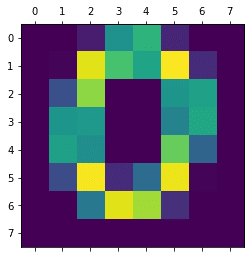
Aの画像
<セル1>
from PIL import Image, ImageOps
import numpy as np
img = Image.open("./alphabet/A.png")
img_gray = ImageOps.invert(img.convert("L").resize((8,8)))
img_array = np.array(img_gray)
print(img_array)
実行結果
[[ 0 0 0 22 23 0 0 0]
[ 0 0 0 44 50 5 0 0]
[ 0 0 13 31 17 27 0 0]
[ 0 0 42 26 18 45 0 0]
[ 0 5 52 30 30 52 3 0]
[ 0 25 23 0 0 30 17 0]
[ 0 21 6 0 0 8 10 0]
[ 0 0 0 0 0 0 0 0]]<セル2>
import matplotlib.pyplot as plt
plt.matshow(img_array)
実行結果<セル5>
img_data = img_array.reshape(-1, 64)
result = model.predict(img_data)
print(result)
実行結果
[4]Bの画像
<セル1>
from PIL import Image, ImageOps
import numpy as np
img = Image.open("./alphabet/B.png")
img_gray = ImageOps.invert(img.convert("L").resize((8,8)))
img_array = np.array(img_gray)
print(img_array)
実行結果
[[ 0 7 34 37 36 7 0 0]
[ 0 30 25 11 25 31 0 0]
[ 0 35 4 0 33 16 0 0]
[ 0 39 41 63 65 16 0 0]
[ 3 39 18 12 7 44 1 0]
[ 7 37 0 0 2 43 0 0]
[ 5 38 32 35 44 19 0 0]
[ 0 5 14 12 2 0 0 0]]<セル2>
import matplotlib.pyplot as plt
plt.matshow(img_array)
実行結果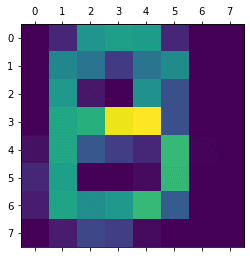
<セル5>
img_data = img_array.reshape(-1, 64)
result = model.predict(img_data)
print(result)
実行結果
[4]Cの画像
<セル1>
from PIL import Image, ImageOps
import numpy as np
img = Image.open("./alphabet/C.png")
img_gray = ImageOps.invert(img.convert("L").resize((8,8)))
img_array = np.array(img_gray)
print(img_array)
実行結果
[[ 0 0 2 10 5 0 0 0]
[ 0 4 43 36 41 33 1 0]
[ 0 21 26 0 0 15 2 0]
[ 0 30 15 0 0 0 0 0]
[ 0 30 14 0 0 1 0 0]
[ 0 16 41 15 21 39 2 0]
[ 0 0 17 31 27 8 0 0]
[ 0 0 0 0 0 0 0 0]]<セル2>
import matplotlib.pyplot as plt
plt.matshow(img_array)
実行結果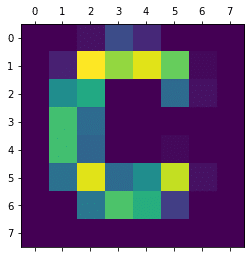
<セル5>
img_data = img_array.reshape(-1, 64)
result = model.predict(img_data)
print(result)
実行結果
[0]Dの画像
<セル1>
from PIL import Image, ImageOps
import numpy as np
img = Image.open("./alphabet/D.png")
img_gray = ImageOps.invert(img.convert("L").resize((8,8)))
img_array = np.array(img_gray)
print(img_array)
実行結果
[[ 0 0 6 7 0 0 0 0]
[ 0 12 42 40 37 2 0 0]
[ 0 20 25 0 23 32 0 0]
[ 0 19 26 0 0 41 0 0]
[ 0 22 24 0 4 40 0 0]
[ 0 27 22 6 36 21 0 0]
[ 0 13 40 39 24 0 0 0]
[ 0 0 0 0 0 0 0 0]]<セル2>
import matplotlib.pyplot as plt
plt.matshow(img_array)
実行結果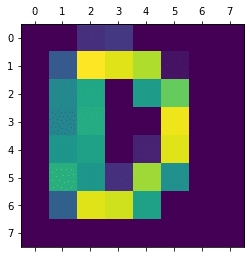
<セル5>
img_data = img_array.reshape(-1, 64)
result = model.predict(img_data)
print(result)
実行結果
[7]Eの画像
<セル1>
from PIL import Image, ImageOps
import numpy as np
img = Image.open("./alphabet/E.png")
img_gray = ImageOps.invert(img.convert("L").resize((8,8)))
img_array = np.array(img_gray)
print(img_array)
実行結果
[[ 0 0 3 9 11 1 0 0]
[ 0 15 50 37 28 1 0 0]
[ 0 22 22 0 0 0 0 0]
[ 0 24 40 22 22 0 0 0]
[ 0 27 42 25 14 0 0 0]
[ 0 30 11 0 0 0 0 0]
[ 0 30 46 39 40 10 0 0]
[ 0 1 4 2 0 0 0 0]]<セル2>
import matplotlib.pyplot as plt
plt.matshow(img_array)
実行結果
<セル5>
img_data = img_array.reshape(-1, 64)
result = model.predict(img_data)
print(result)
実行結果
[7]まとめ
結果をまとめてみるとこうなります。
| A | B | C | D | E |
| 4 | 4 | 0 | 7 | 7 |
まずはもちろん「A」「B」「C」「D」「E」を学習させていないし、「数字以外」という括りのデータもないため、学習させた「数字」を無理やりにでも予想します。
そんな中で「A」の「4」と「C」の「0」はなんとなくそう見えて納得できます。
でも「B」は「8」、「D」は「0」じゃないかと思って納得いかない。
「E」はなかなか当てはまりそうなのはないですが、あえて言えば「8」じゃないかと。
とにかく意外と感覚で思った結果が出ないことも多く、機械学習で読み取っている判別場所というのは人間とは違うんじゃないかということが分かります。
あとは今回はどうしても8x8ピクセルにしなければいけないので、かなり画像の質が落ちていて判別が難しくなっているんじゃないかと思います。
Scikit-learnの付属のデータセットなので、なかなかデータ量を増やせないという問題もあるのでしょうが、こうなってくるともっとピクセル数の多い、綺麗な画像で試してみたくなりますね。
この手書き数字のデータセットも色々といじってきたので、次回はそろそろ違うデータセットに移ろうかと思います。
ということで今回はこんな感じで。
コメント