機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnの手書き数字のデータセットを使って、自分で作った手書き数字の予想をするための画像などの準備をしました。
今回は画像を読み込み、データセットを機械学習させ、予想するというプログラムを作っていきます。
画像の読み込み、処理に関して「PIL(Python Image Library)」を使っていきますが、今回はざっとした解説だけにして、とりあえず動かしてみることにします。
PILの詳しい解説に関してはまたそのうちにやりたいなと思いますので、しばしお待ちくださいませ。
ということで進めていきましょう。
画像の読み込みとデータの変換
まず最初に画像の読み込みをして、手書き数字のデータセットと同じ形式に変換していきます。
まずはライブラリのインポートから。
ここでは「PIL」の「Image」と「ImageOps」、そして「numpy」をインポートします。
from PIL import Image, ImageOps
import numpy as npイメージを読み込むには、「Image.open(“画像のファイル”)」とします。
現在、フォルダ構造はこうなっているはずなので、画像のファイルは「./numbers/0.png」といった感じになります。
img = Image.open("./numbers/0.png")これで画像が「img」という変数に格納されました。
次に読み込んだ画像をグレースケールにして、一度表示し確認するため8ピクセルx8ピクセルの画像にし、さらに白黒を反転させます。
グレースケールに変えるのは「.convert(“L”)」、8ピクセルx8ピクセルにするのは「.resize((8, 8))」、白黒反転させるのは「ImageOps.invert()」です。
img_gray = ImageOps.invert(img.convert("L").resize((8,8)))次にデータをnumpyの二次元リストに変えます。
img_array = np.array(img_gray)ということで全体を書いてみるとこんな感じ。
<セル1>
from PIL import Image, ImageOps
import numpy as np
img = Image.open("./numbers/0.png")
img_gray = ImageOps.invert(img.convert("L").resize((8,8)))
img_array = np.array(img_gray)
print(img_array)
実行結果
[[ 0 0 5 33 42 7 0 0]
[ 0 1 62 46 38 65 8 0]
[ 0 16 54 0 0 34 37 0]
[ 0 34 35 0 0 29 39 0]
[ 0 37 32 0 0 50 21 0]
[ 0 15 64 8 23 63 1 0]
[ 0 0 26 62 56 9 0 0]
[ 0 0 0 0 0 0 0 0]]次に画像で表示してみましょう。
こちらは前に解説した「matplotlib」の「matshow」でさくっと表示させましょう。
<セル2>
import matplotlib.pyplot as plt
plt.matshow(img_array)
実行結果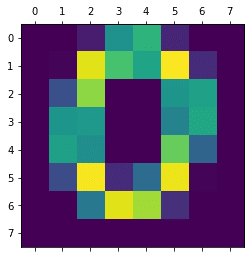
これなら人が見ればちゃんと「0」だと分かりますね。
LinearSVCで機械学習
次は手書き数字のデータセットをLinearSVCモデルを使って機械学習させていきましょう。
ここは前にもやっているので、詳しい解説は飛ばします。
<セル3>
from sklearn.datasets import load_digits
digits = load_digits(as_frame=True)
digits.frame
実行結果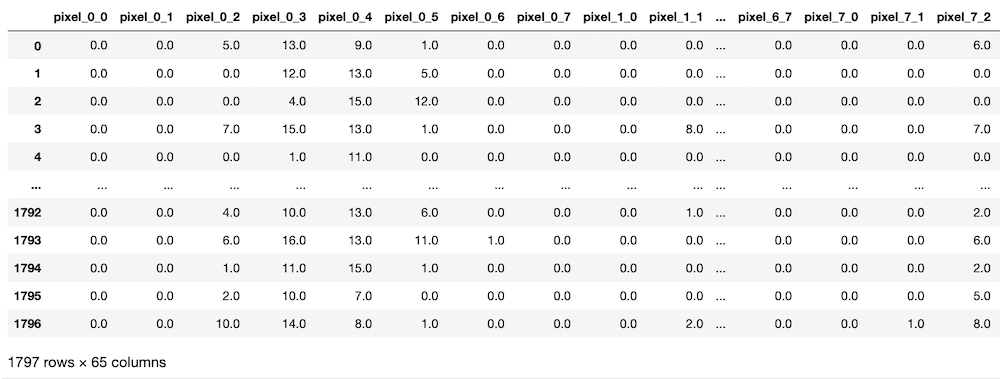
<セル4>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = digits.frame.iloc[:, 0:-1]
y = digits.frame.iloc[:, -1]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=1000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.9416666666666667これでLinearSVCモデルを使って機械学習できました。
予想させてみる
それでは今回のメインイベント。
機械学習による手書き数字の予想を試してみましょう。
と、ここでまずは読み込んだ画像データの形式をもう少し変えます。
最初に読み込んだ際は、8ピクセルx8ピクセルの二次元リストにしました。
しかしデータセット内のデータは二次元リストではなく一次元リストなので、形式を変換します、。
img_data = img_array.reshape(-1, 64)次に予想させます。
予想させるには「モデル名の変数.predict(予想するデータ)」となります。
result = model.predict(img_data)ということで繋げて、実行してみるとこんな感じ。
<セル5>
img_data = img_array.reshape(-1, 64)
result = model.predict(img_data)
print(result)
実行結果
[0]ちゃんと「0」 と予想されました。
こうやって思ったように動くとなかなか感動ですね。
ついでに他の数字も試してみましょう。
数字を変える場合は<セル1>で読み込む画像を変えます。
今回は「5」にしてみましょう。
<セル1 変更>
from PIL import Image, ImageOps
import numpy as np
img = Image.open("./numbers/5.png")
img_gray = ImageOps.invert(img.convert("L").resize((8,8)))
img_array = np.array(img_gray)
print(img_array)
実行結果
[[ 0 1 16 20 22 26 4 0]
[ 0 26 68 47 46 40 4 0]
[ 0 35 32 8 6 0 0 0]
[ 0 36 82 55 59 50 0 0]
[ 0 3 2 0 0 65 1 0]
[ 0 1 22 29 48 53 0 0]
[ 0 3 38 40 28 1 0 0]
[ 0 0 0 0 0 0 0 0]]一応画像でも確認してみます。
<セル2>
import matplotlib.pyplot as plt
plt.matshow(img_array)
実行結果
機械学習のパートは先ほど実行しているので、カーネルがそのままの場合(カーネル再起動のボタンを押していなかったり、Anacondaを閉じたりしていない場合)は省略できます。
ということで<セル5>まで飛んで実行してみます。
img_data = img_array.reshape(-1, 64)
result = model.predict(img_data)
print(result)
実行結果
[5]ちゃんと「5」と予想されました。
やっぱりこうやって予想できるようになると「機械学習をやった」という感じになりますね。
今回のデータセットの場合、LinearSVCで十分な予想精度がありそうですが、せっかくなので他のモデルも試してみることにしましょう。
それはまた次回ということで。
ではでは今回はこんな感じで。
コメント