機械学習ライブラリScikit-learn
前回まで機械学習ライブラリScikit-learnのiris(アヤメ)のデータセットを使って、機械学習の手法の一種サポートベクターマシンの解説をしてきました。
今回からはデータセットを変えて、また機械学習の別の手法を学んでいきたいと思います。
これまではサポートベクターマシンで数値データから最終的に「分類」をしてきました。
しかし機械学習は「分類」をするだけではありません。
今回は色々なデータを学習させ、ある特定の「数値」を予想するということをしてみましょう。
そのため今回はScikit-learnの練習用データセットの中の「ボストンの住宅価格」を使っていきます。
ということでまずは読み込んでいきます。
今回もセルを変えていきますので、セル番号を書いておきます。
<セル1>
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.keys())
実行結果
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])irisのデータセットの時と同様、「from sklearn.datasets import load_boston」でデータセットをインポートします。
そして「boston = load_boston()」で変数bostonにデータセットを格納しています。
最後に「print(boston.keys())」で含まれるキーを表示しました。
データセットの概要を確認
まずはデータセットの概要を確認していきます。
このScikit-learnの練習用データセットでは「DESCR」というキーでその概要を見ることができます。
<セル2>
print(boston.DESCR)
実行結果
.. _boston_dataset:
Boston house prices dataset
---------------------------
**Data Set Characteristics:**
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
(以下略)全部表示するには長すぎるので、データの内容を解説しているところだけ抜き出しました。
上から解説していきましょう。
「Number of Instances: 506」は含まれているデータ数が「506」であることを示しています。
「:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target」は13の特徴量があり、「Median Value」というのが通常、機械学習で求める対象だそうです。
「CRIM per capita crime rate by town」= 犯罪率。
「ZN proportion of residential land zoned for lots over 25,000 sq.ft.」= 区画のサイズが25,000平方フィート以上の住居区画の割合。
「INDUS proportion of non-retail business acres per town」= 小売業以外のビジネスの土地の割合。
「CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)」= チャールズ川沿いかどうかのダミー変数(1:川沿い、0:それ以外)
「NOX nitric oxides concentration (parts per 10 million)」= NOX(窒素酸化物)の濃度
「RM average number of rooms per dwelling」= 住居の中の平均部屋数
「AGE proportion of owner-occupied units built prior to 1940」= 1940より前に建てられた持ち家の割合。
「DIS weighted distances to five Boston employment centres」= ボストンにある5つの職場からの距離(重みを含む)
「RAD index of accessibility to radial highways」= 高速道路へのアクセスのしやすさの指標
「TAX full-value property-tax rate per $10,000」= $10,000あたりの住居に対する税率
「PTRATIO pupil-teacher ratio by town」= 生徒と教師の割合
「B 1000(Bk – 0.63)^2 where Bk is the proportion of blacks by town」= 町の黒人の割合を「1000(Bk – 0.63)^2」の式で表したもの
「LSTAT % lower status of the population」= 低所得者層の人の割合
「MEDV Median value of owner-occupied homes in $1000’s」= 持ち家として占有されている住居価格の中央値($1,000単位)
「Missing Attribute Values: None」= 特徴量の中で欠損値の数:無し
今回はかなり多くの特徴量があり、さらに英語ということもあり、正確に訳せているかはちょっと自信がないところです。
ですが、なるべくどんな数値かイメージして扱っていくのが機械学習では重要だと思います。
つまりどんな値が最終的に予想する「MEDV」、つまり住居の価格に繋がっているのかを考えていくということです。
ということで今回は大まかに、そしてある程度正確であればよしとして、機械学習をしていきたいと思います。
ちなみに欠損値がないということで、欠損値チェックは省きます。
ということでちょっとそれぞれの値を見てみましょう。
データを眺めてみる
データを眺めてみるには、まずはPandasのデータフレームに格納して、表としてみるのが一番です。
<セル3>
import pandas as pd
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df
実行結果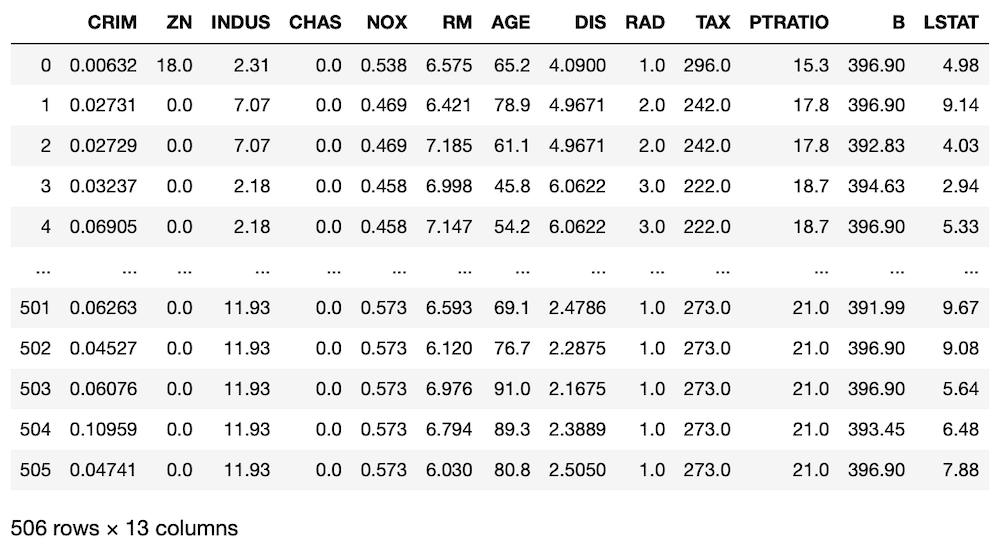
最終的に予想する「MEDV」の値がありません。
「MEDV」はtargetの方に格納されているので、さらにこのデータフレームに追加します。
import pandas as pd
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df["MEDV"] = boston.target
df
実行結果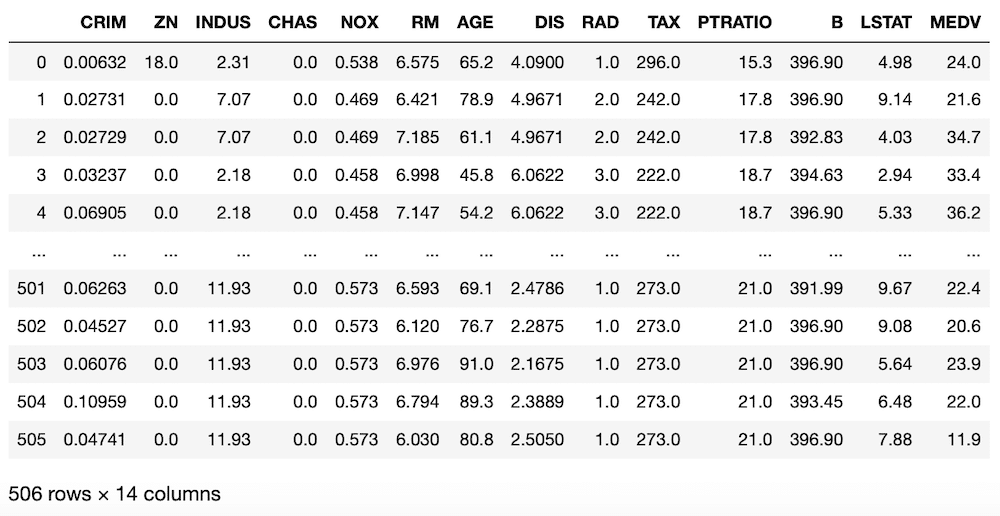
「MEDV」の列が追加されました。
ここから値をなんとなく眺めて感覚を掴んでいきます。
ですがなんとなく下側の「501」から「505」のデータをみると値的に似通っているものばかりなので、最初と最後の5つずつのデータではなく、最初の10個のデータを表示してみましょう。
<セル3>
import pandas as pd
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df["MEDV"] = boston.target
df.head(10)
実行結果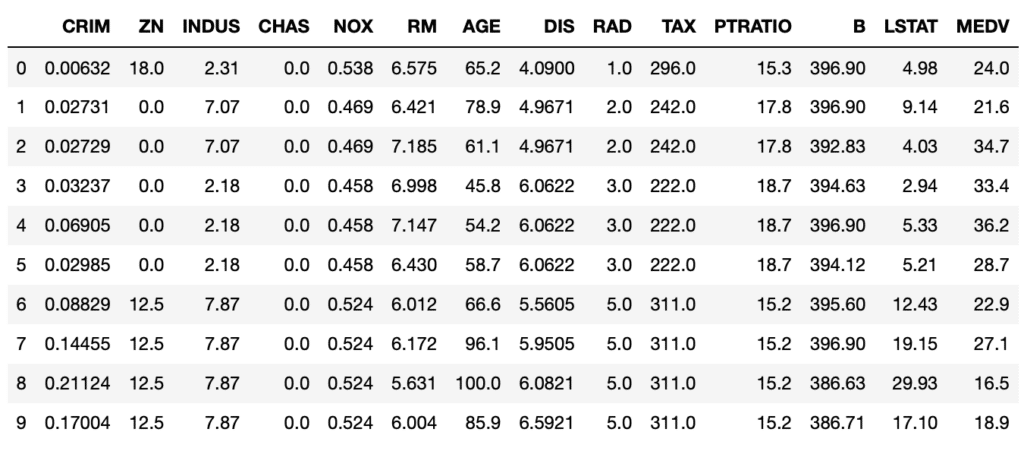
- ZNは0が多いが、18、12.5と値が大きく違うものがある?
- INDUSは2か7と大きく違っている?
- CHASは0ばかり?(川の近くかどうかなので、単に1である物件が少ない?)
- NOXはそこまで大きく違っているように見えない
- Bもあまり変わらない
- LSTATの値は大きく差がある?
次回はこういった点に注目しつつ、グラフ化してどういった値が住宅価格に関連しているのかを解析していきましょう。
ということで今回はこんな感じで。
コメント