SQLite3
今回からはデータベース管理システム「SQLite3」をいじっていこうと思います。
その理由としてはこれまで何らかのデータを保存・管理するのにCSVファイルやJSONファイルを使っていました。
それはそれで使いやすかったのですが、Twitterの制御にTweepyを使ったり、漢字間違い探しを運営したりして、もっともっと大量のデータを扱うようになってきました。
それならばと一念発起し、データベース管理システムに手を出してみようと思ったのが発端です。
色々と調べてみると、メジャーなデータベース管理システムとしては、「MySQL」、「PostgreSQL」、そして今回から扱っていく「SQLite」などがあるようです。
どうも同時に何人もが操作するデータベースの場合、MySQLやPostgreSQLを使うのがいいようですが、これらはなかなか学習コストが高いようです。
そして一人や同時にデータベースを操作しない場合にはSQLiteが手軽に導入できてよいということだったため、とりあえずデータベースのいじり方も含めて、SQLiteから勉強してみようかなと思い、今回はSQLiteを選択しました。
とりあえずSQLiteを使ってみて、もっと勉強する気になったり、機能的に物足りなかったりしたらMySQLやPostgreSQLに手を出してみようかと思います。
また最終的にはPythonのプログラムに組み込んでいきますが、その前にデータベースの作成やデータの追加、データの検索など基本的な点をSQLite3をMacOSのターミナル上でいじって、感覚を掴んでいこうと思います。
ちなみにMacOSのターミナルには最初からSQLite3がインストールされているため、何の事前準備も無しに始められるのもなかなかのメリットです。
ということでとりあえず始めてみましょう。
データベースの作成
まずはデータベースを作成します。
ターミナルを起動し、「sqlite3 test1.db」とタイプし、エンターを押します。
sqlite3 test1.db
実行結果
SQLite version 3.37.0 2021-12-09 01:34:53
Enter ".help" for usage hints.
sqlite> これで「test1.db」というデータベースが作成され、SQLite3上で開いた状態となります。
ということでデータベースの新規作成は「sqlite3 データベース名」というわけです。
ここからターミナルの画面の先頭に「sqlite>」と書かれている場合は、SQLite3のシステム上での操作となっていることに気を付けてください。
つまりターミナルのコマンドである「cd」とか「ls」とかタイプしても動きません。
sqlite> ls
実行結果
...> また上記のように「…>」となっている場合は上の行で入力したコマンドがまだ続いている状態を示しています。
SQLite3の場合、特定のコマンド以外のコマンドの最後には「;」(セミコロン)が必要です。
上記の状態で「;」を入力して、エンターを押してみましょう。
...> ;
実行結果
Error: in prepare, near "ls": syntax error (1)これでやっとエラーが出ました。
話をデータベースの作成に戻しましょう。
先ほど「「sqlite3 test1.db」で「test1.db」というデータベースが作成され、SQLite3上で開いた状態となります。」とお話ししましたが、この状態ではまだファイルは作成されていません。
試しにSQLite3の終了コマンドである「.exit」をタイプして、SQLite3を終了し、実行していたフォルダを確認してみてください。
そこには「test1.db」というフォルダは作成されていないはずです。
ということでもう一度「sqlite3 test1.db」とタイプして、SQLite3に戻ります。
次に「.databases」とタイプして、エンターを押します。
sqlite> .databases
実行結果
main: /sqlite3を実行したフォルダパス/test1.db r/w
sqlite> これで「test1.db」というファイルが作成されていることでしょう。
テーブルの作成
次にテーブルを作成します。
テーブルというのは特定のデータをまとめたもので、後で他のテーブルと連携させたりすることができます。
ここら辺の概念はAdaloを使ったときに少し説明していますので、こちらの記事をご覧ください。
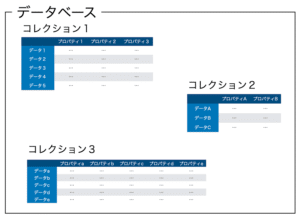
Adaloでの「コレクション」がSQLite3の「テーブル」と同意でいいと思います。
そこでSQLite3でテーブルを作成するのですが、作成する際にはテーブルの名前とどんなデータがどんな形で保存されるののかを指定します。
そのためそのコマンド(クエリというらしいです)は「CREATE TABLE テーブル名(列1の名前 列1の形式, 列2の名前 列2の形式…):」といった形になります。
またPandasのような「明示的な」インデックスは勝手に作成されないようなので、最初の列をインデックスとすることも多々あるでしょう。
(ちなみに隠しIDのようなものは自動で作成されるようです)
その場合はCREATE TABLE テーブル名(id INTEGER PRIMARY KEY, 列2の名前 列2の形式, 列3の名前 列3の形式…):」とすると1列目がインデックス列となるようです。
とりあえず両方試してみましょう。
sqlite> CREATE TABLE table1(name TEXT, age INTEGER);
実行結果
sqlite> sqlite> CREATE TABLE table2(id INTEGER PRIMARY KEY, name TEXT, age INTEGER);
実行結果
sqlite> SQLite3では正常に実行した場合、何らかの返答をくれるわけではないようです。
そこで上記2つのテーブルが作成されたか確認してみましょう。
現在あるテーブルを確認するには「.tables」とタイプし、エンターを押します。
sqlite> .tables
実行結果
table1 table2「table1」と「table2」があることを確認できました。
またそれぞれのテーブルにどのような形のデータが格納されているか表示するには「.schema」とタイプし、エンターを押します。
sqlite> .schema
実行結果
CREATE TABLE table1(name TEXT, age INTEGER);
CREATE TABLE table2(id INTEGER PRIMARY KEY, name TEXT, age INTEGER);データの追加
次にデータの追加をしてみましょう。
データを追加するには「INSERT INTO テーブル名(データを追加する列名1, データを追加する列名2…) values(追加する値1, 追加する値2…);」という形のクエリを用います。
まずはtable1にnameを「’Sato’」で、ageを「30」としてデータを追加してみましょう。
sqlite> INSERT INTO table1(name, age) values('Sato',30);
実行結果
sqlite>エラーが出なかったので、多分正常に追加されていると思いますが、その確認は後ですることにしましょう。
しかし「’Sato’」のデータを入れた時とは異なり、nameだけ入れてみましょう。
sqlite> INSERT INTO table1(name) values('Suzuki');
実行結果
sqlite>こちらもエラーが出なかったので、どう追加されたかは後で確認してみます。
次に「INSERT INTO table1(name, age) values(‘Takahashi’)」、つまり追加する列の数と追加するデータの数が異なっている場合はどうなるのか試してみます。
sqlite> INSERT INTO table1(name, age) values('Takahashi');
実行結果
Error: in prepare, 1 values for 2 columns (1)これは流石に「2つの列を指定しているのに、1つのデータしかないよ」というエラーが出ました。
データの取得
データの取得をするには「SELECT 取得したい列名 FROM テーブル名」というクエリで取得できます。
sqlite> select name from table1;
実行結果
Sato
Suzukiまた全部の列を取得したい場合は列名の代わりに「*」(アスタリスク)を使うことも可能です。
sqlite> select * from table1;
実行結果
Sato|30
Suzuki|先ほど追加した「’Sato’」と「’Suzuki’」のデータが表示されました。
また「’Suzuki’」ではAgeの列のデータは入力しなかったので、空欄になっています。
さらに「’Takahashi’」のデータは入力がエラーになったため、追加されていないことも確認できました。
id INTEGER PRIMARY KEYを使った場合
次にテーブルを作成した際に「id INTEGER PRIMARY KEY」を使った場合を見てみましょう。
先ほどデータを追加したのと同様に「’Tanaka’, 25」、「’Ito’, 30」、「’Watanabe’, 35」というデータを追加します。
sqlite> INSERT INTO table2(name, age) values('Tanaka', 25);
sqlite> INSERT INTO table2(name, age) values('Ito', 30);
sqlite> INSERT INTO table2(name, age) values('Watanabe', 35);そしてSELETを使って追加したデータを取得してみましょう。
sqlite> SELECT * from table2;
実行結果
1|Tanaka|25
2|Ito|30
3|Watanabe|35先ほどINSRETでデータを追加した際には「id」の値を入力しませんでしたが、自動でそれぞれのデータのIDが「1, 2, 3」と振られているのが分かります。
このように「SELECT * from テーブル名」でIDが欲しい場合は、テーブル作成時に「id INTEGER PRIMARY KEY」を追加しておくと良いようです。
SQLite3の終了
SQLite3を終了するには「.exit」とタイプし、エンターを押します。
保存もせずにいきなり終了してしまっていいのかと思いますが、どうやらデータベースに何らかの変更があった場合、自動で保存されるようで大丈夫なようです(多分)。
その確認のために再度データベースを開いて、テーブルの中身を確認してみてください。
先ほど追加したデータが残っていることでしょう。
ということでSQLite3のデータベース作成からテーブルの作成、データの追加、データの取得という基礎をやってみました。
次回はテーブルを作成する際に指定するデータの型に関して勉強してみましょう。
ではでは今回はこんな感じで。
コメント