Tweepy
前回はツイート数やリツイート数、いいね数を数えて、ツイートのログを取るプログラムを作ってみました。

その時に「ツイートをログとして保存するのは次に作るプログラムと関連している」というお話をしました。
それが今回の「保存したツイートからランダムにツイートする」というプログラムです。
なんのためにかというと、Twitterで記事を紹介した後、そのツイートを時間が経ってから再度ツイートすることで宣伝しようという目論見からです。
最初はツイートのリストを一つずつ作っていき、それをランダムにツイートするというのも考えたのですが、実はそれは結構うまくいかない可能性が高いと考えられます。
一番大きな問題はTwitterは「140文字」という制限があることです。
「140文字」を超えてしまったら、ツイートできません。
そうなると文字数を気にしつつツイートを作る必要が出てきます。
しかしテキストエディタで140文字を気にしつつ書くのも面倒です。
そこで出てきた案が、「一度ツイートする」という案です。
一度ツイートしてしまえば、140文字以内に収まっているのは明確ですし、スマホで入力した絵文字もそのまま使えます。
書くときはTwitterアプリで書けば140文字に収めることは簡単ですし、ハッシュタグも予測で出てきてくれる。
ということでかなりメリットが大きそうなので、「一度ツイートして、そのログを保存。必要なツイートのみ、テキストファイルに保存して、それをランダムにツイートする」という流れにしました。
実際に何日間かツイートのログを取り、一つ一つファイルにしていったのがこちらです。
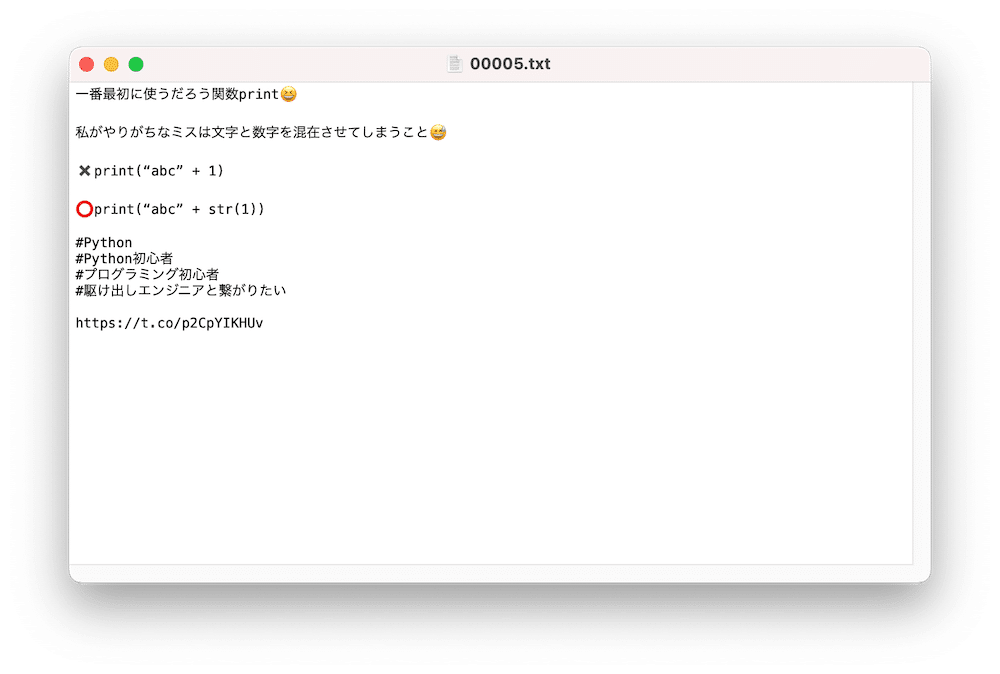
例として「0005.txt」を開いてみるとこんな感じです。
それではプログラムをみていきましょう。
プログラム全体
プログラム全体はこんな感じです。
<セル1>
import tweepy
import os
import random
import datetime
tweetlist = r" tweet_list_dir "
tweet_log = r" randomtweet_log.txt "
timenow = datetime.datetime.now().strftime("%Y%m%d_%H%M")
consumer_key = ' consumer key '
consumer_secret = ' consumer secret '
access_token = ' access token '
access_token_secret = ' access token secret '
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth, wait_on_rate_limit = True)<セル2>
def main():
filelist = []
for f in os.listdir(tweetlist):
if not f.startswith("."):
filelist.append(f)
tweet = random.choice(filelist)
print(tweet)
with open(tweet_log, "a") as log_out:
log_out.write(timenow + ", " + tweet + "\n")
with open(tweetlist + "/" + tweet, "r") as file:
tweet_content = file.read()
api.update_status(tweet_content)<セル3>
if __name__ == '__main__':
main()<セル1>セッティング
<セル1>はセッティング部分です。
インポートするライブラリは「tweepy」「os」「random」「datetime」の4つです。
import tweepy
import os
import random
import datetimeツイートが保存してあるフォルダを「tweetlist」に、またどのツイートをいつにしたかのログファイルを「tweet_log」に定義します。
あとはプログラムの実行の時間を取得して「timenow」に格納しておきます。
tweetlist = r" tweet_list_dir "
tweet_log = r" randomtweet_log.txt "
timenow = datetime.datetime.now().strftime("%Y%m%d_%H%M")ここからはいつも通りTwitter APIへの接続なので、解説は割愛します。
consumer_key = ' consumer key '
consumer_secret = ' consumer secret '
access_token = ' access token '
access_token_secret = ' access token secret '
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth, wait_on_rate_limit = True)<セル2>メインプログラム
<セル2>はメインプログラム部分です。
この部分では、
- ツイートファイルが保存してあるフォルダから、ツイートファイルのリストを取得
- ツイートファイルのリストからランダムに一つ抽出
- 抽出したツイートファイルの番号をログに保存
- 抽出したツイートファイルの内容をツイート
という流れでプログラムが進んでいきます。
1. ツイートファイルのリストを取得
filelist = []
for f in os.listdir(tweetlist):
if not f.startswith("."):
filelist.append(f)ここではまず空のリストを準備(filelist = [])し、ツイートファイルが保存してあるフォルダからファイル名を一つずつ取得(for f in os.listdir(tweetlist):)、隠しファイルではなかったら(if not f.startswith(“.”):)、そのファイル名をリストに追加(filelist.append(f))しています。
特にMacの場合はシステムが隠しファイルを作りたがるので、隠しファイルを読み込まない工夫が必要でした。
2. ツイートファイルのリストからランダムに一つ抽出
tweet = random.choice(filelist)
print(tweet)ここでは先ほど作成したツイートのファイル名のリストからランダムに一つ(random.choice())取得しています。
randomモジュールに関してはこちらの記事でまとめていますので、よかったらどうぞ。

print(tweet)としているのは確認のためです。
3. 抽出したツイートファイルの番号をログに保存
with open(tweet_log, "a") as log_out:
log_out.write(timenow + ", " + tweet + "\ここではログファイルを追記モードで開き(with open(tweet_log, “a”))、2行目で時間とツイートのファイル名を書き込んでいます。
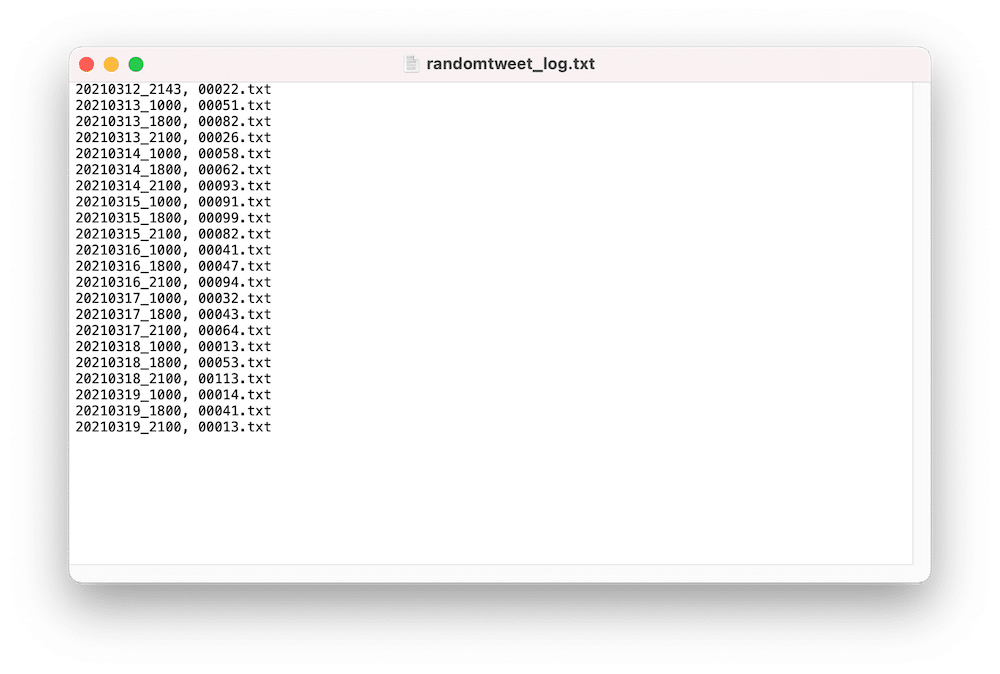
実際にはこんな感じのログを取得できます。
4. 抽出したツイートファイルの内容をツイート
with open(tweetlist + "/" + tweet, "r") as file:
tweet_content = file.read()
api.update_status(tweet_content)ここでは先ほどランダムに取得したファイル名から実際にファイルを開き(with open(tweetlist + “/” + tweet, “r”))、その内容をtweet_contentに格納(tweet_content = file.read())、最後にツイートしています(api.update_status(tweet_content))。
<セル3>__name__の呼び出し
if __name__ == '__main__':
main()このプログラムはcronで定期実行するため、pythonの実行ファイルとしておく必要があります。
そこで「if __name__ == ‘__main__’:」でこのプログラムがpyファイルとして実行されたとき、main()が実行されるようにしておきます。
これでプログラムは完成です。
まとめ
この方法では前回のプログラムで保存したツイートを、一つ一つ手作業でファイルとして保存し、サーバーにアップロードする必要があります。
とはいえ1日に100回もツイートするわけでなく、よくやって1時間に1回、つまり24回程度が最大値としてみていいでしょう。
そう考えるとコピペするだけですので、それほど手間もかかりません。
実際に1ヶ月程度運用してみましたが、数日に1回、10分程度作業すれば十分でした。
それで過去の記事も紹介できるとなれば、結構いいプログラムなのではないかなと自画自賛しています。
もちろん他にもっと効率的な方法もあるのでしょうが、とりあえずはこのやり方ブログの宣伝を自動化していこうと思います。
ちなみにGitHubにもこのプログラムはアップロードしてありますので、よかったらどうぞ。
ではでは今回はこんな感じで。
コメント