DX(デジタルトランスフォーメーション)
前回、Pythonで始めるなんちゃってDXのおまけとして、個人情報的なデータをランダムで作るプログラムを紹介しました。
今回はデータから簡単にグラフを作成するプログラムを作ってみたので、紹介していきます。
まずはどんなプログラムか見てみましょう。
このプログラムでできること
このプログラムでできることは「CSVファイルから折れ線グラフを作成すること」です。
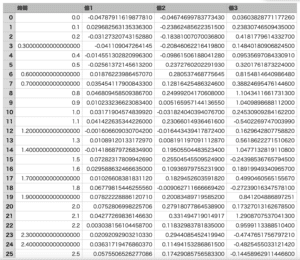
準備するデータはこんな感じです。
(CSVファイルなので、テキストエディタで開くとカンマ区切りです)
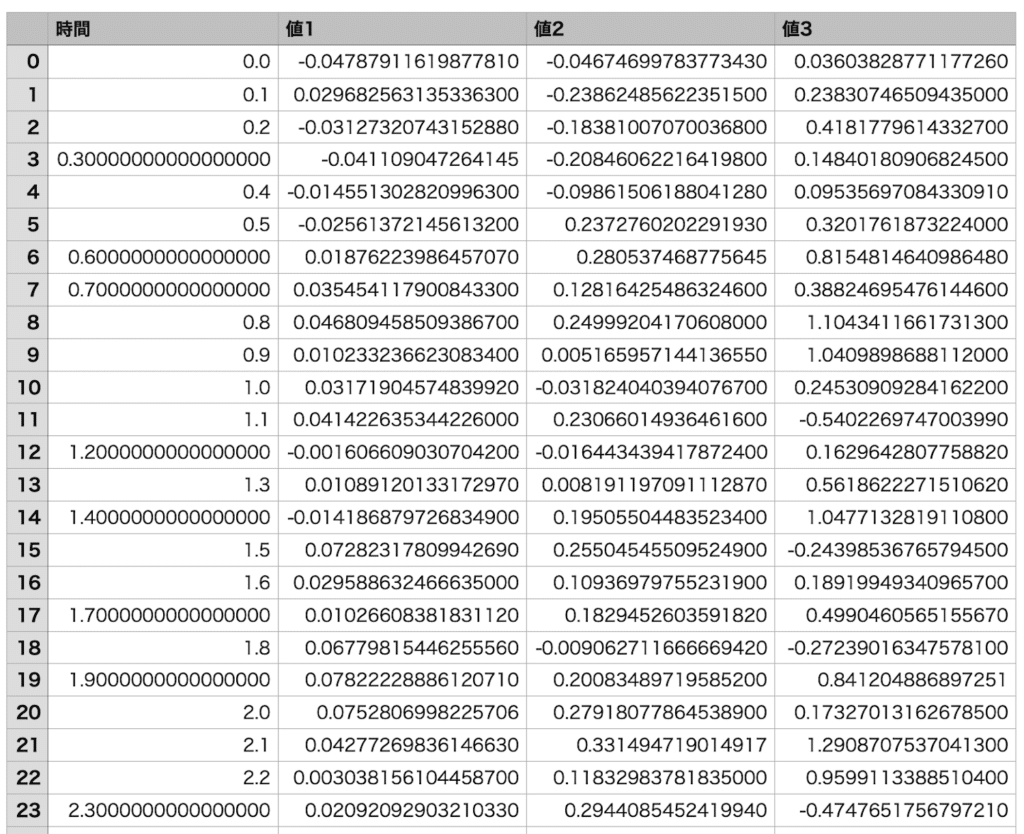
少し数字が細かくてびっくりしたかもしれませんが、単純に最初の列が「X値」で、2列目以降が「Y値」になるような表データです。
このようなデータが入っているCSVファイルから、こんなグラフを作成します。
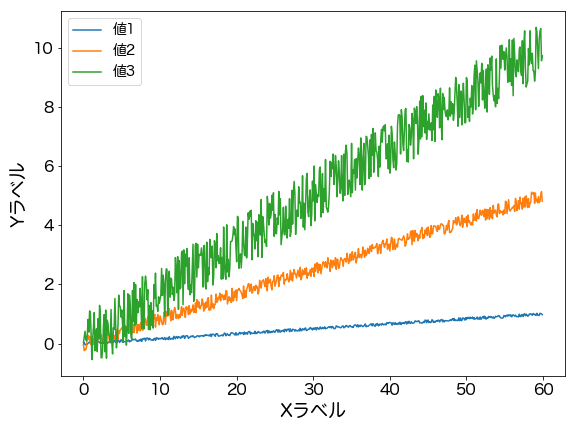
データを扱う人にとって面倒なのは「グラフ化」かなと思います。
特にルーチンワークで同じようなデータを大量に処理する場合、一つ一つエクセルで作っていこうと思うと手間も時間もかかります。
そしてそうして作成されたグラフ全てが使われるわけではなく、例えばデータが正しく取れているか確認したり、処理がうまくいっているのかの確認、さらにはデータの傾向を見たいといった時に、さっと確認できたらうれしいのではないでしょうか。
ということで作成してみましたというのが今回のプログラム。
使い方
まず外部ライブラリ(先に別途インストールが必要なプログラム)で「pandas」と「matplotlib」を使用するので、Macの方はターミナル、Windowsの方はコマンドプロンプトで下のコマンドを実行してください。
ちなみに前回「pandas」をインストールした方は、最初の行をスキップしてもらって大丈夫です。
また逆にインストールできているか心配なら最初の行も実行しても大丈夫です。
pip install pandas
pip install matplotlibインストールが完了したら、こちらのファイルをダウンロードして、展開してください。
展開すると「dx-2_PlotFromCSV.py」というファイルが出てきます。
この「dx-2_PlotFromCSV.py」と、処理したいファイル(下の例ではdx-2_Data1.csv、dx-2_Data2.csv、dx-2_Data3.csv)を同じフォルダに入れてください。
処理したいファイルの名前に制限があり、ファイル名の最初に「dx-2_」をつけてください。
「dx-2_」が付いていないと処理されません。
準備ができたら、「dx-2_PlotFromCSV.py」を実行します。
ダブルクリックで実行してもいいですし、ターミナルやコマンドプロンプトからこちらのコマンドを実行してもいいです。
python dx-2_PlotFromCSV.py実行するとこんな感じになります。
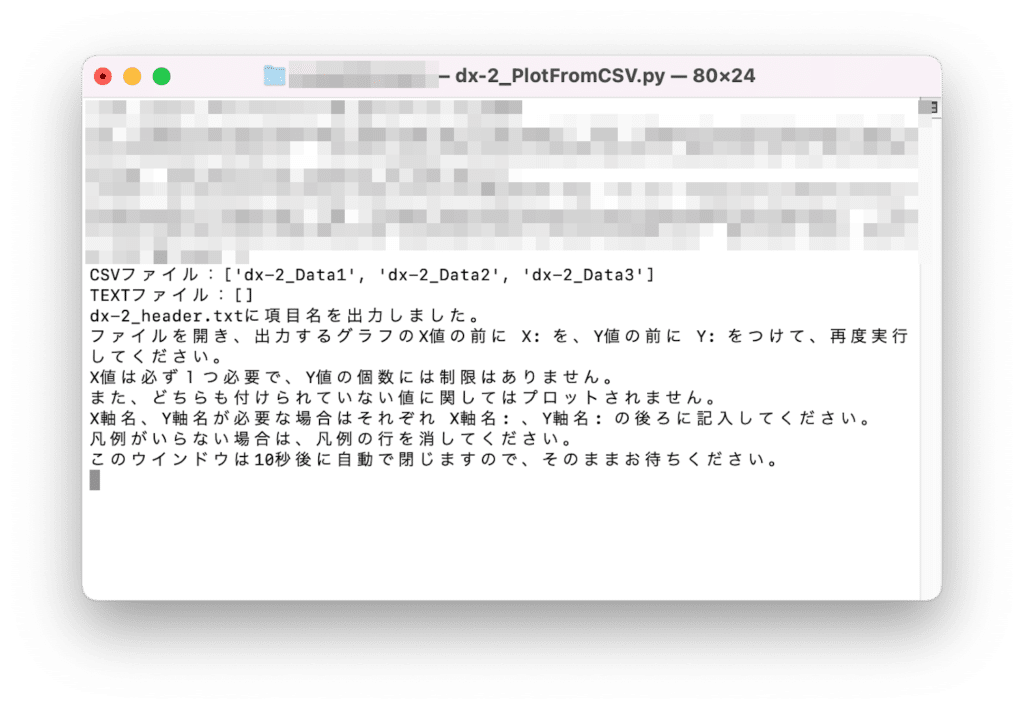
ちなみに「このウインドウは10秒後に自動で閉じますので、そのままお待ちください。」とありますが、Macでは自動で閉じないようです。
ここら辺はご愛嬌ということで、各自で閉じてください。
次は「dx-2_header.txt」というファイルが作成されているので、テキストエディタで開きます。
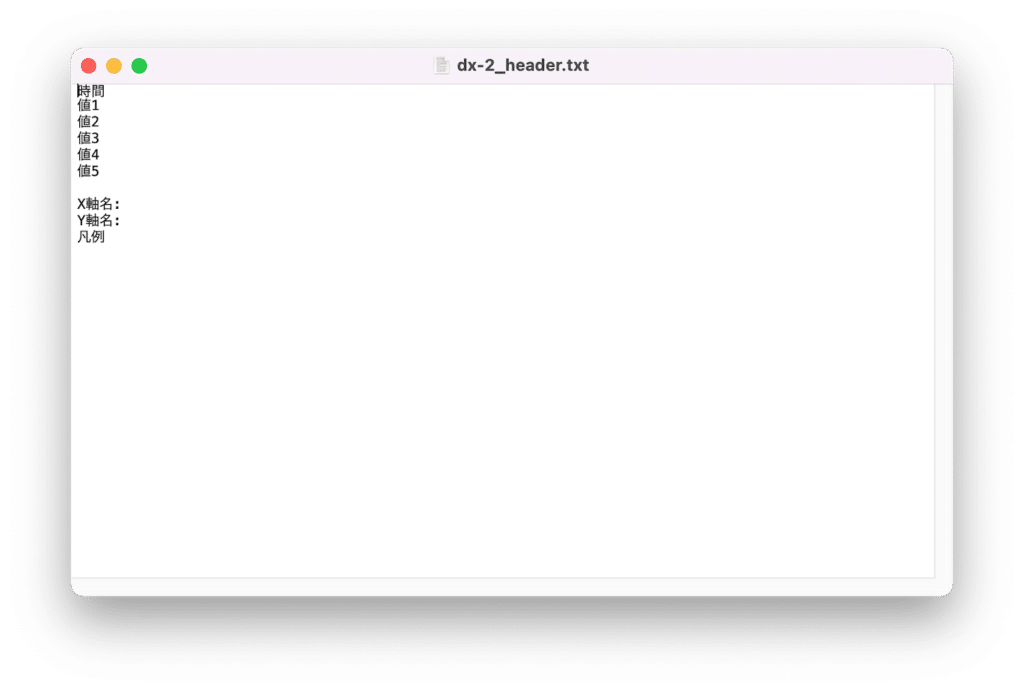
開くと読み込んだCSVファイルに含まれる項目名(ここでは時間、値1、値2、値3、値4、値5)と「X軸名:」、「Y軸名:」、凡例と書かれています。
X軸にしたい値を1つ、Y軸にしたい値を1つ以上選択し、それぞれの行の始めに「X:」、「Y:」を追加します。
また「X軸名:」、「Y軸名:」には続けて、X軸に表記したい文字列、Y軸に表記したい文字列を追加します。
凡例はそのままだと凡例を表示、消すと凡例を非表示になります。
今回はこんな感じにしてみました。
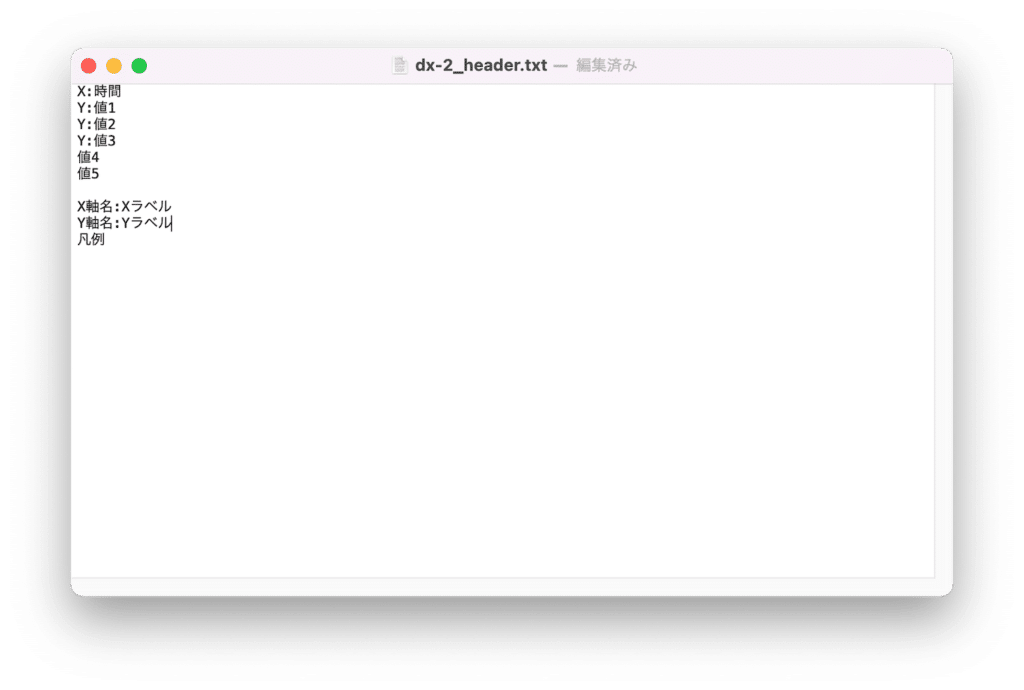
保存したら、再度「dx-2_PlotFromCSV.py」を実行します。
すると処理したCSVファイルの数だけ、このようなグラフのpngファイルが生成されます。
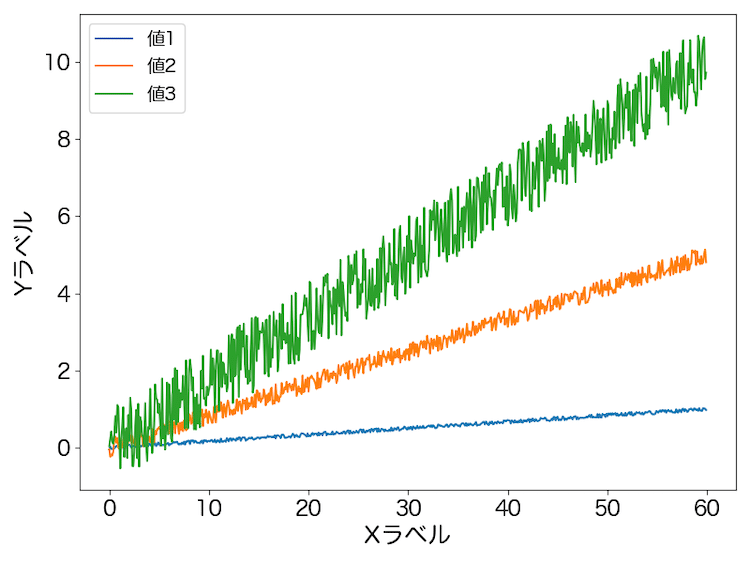
ちなみに列の項目名は同時に処理するファイル全てをまとめたものになります。
そのため、ファイルによっては抽出を選択した項目がない場合もありますが、その場合は単にその項目がスキップされます。
プログラムの解説
プログラム全体
それではプログラムの解説をしていきます。
プログラム全体としてはこんな感じです。
import os
import time
import datetime
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import pandas as pd
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro', 'Yu Gothic', 'Meirio', 'Takao', 'IPAexGothic', 'IPAPGothic', 'Noto Sans CJK JP']
def filenameGet():
csv_list = []; text_list =[]
for filename in os.listdir('./'):
if filename.startswith('dx-2_'):
if filename.endswith('.csv'):
csv_list.append(filename[:-4])
elif filename == 'dx-2_header.txt':
text_list.append(filename)
return csv_list, text_list
def fileProcess(csv_list, text_list, timenow):
if 'dx-2_header.txt' in os.listdir('./'):
x_list = []; y_list = []; legend = 'off'
with open('./dx-2_header.txt', 'r') as f_in:
for row in f_in:
if row.startswith('X:'):
x_list.append(row.split(':')[1].replace('\n',''))
elif row.startswith('Y:'):
y_list.append(row.split(':')[1].replace('\n',''))
elif row.startswith('X軸名:'):
x_label = row.split(':')[1].replace('\n','')
elif row.startswith('Y軸名:'):
y_label = row.split(':')[1].replace('\n','')
elif row.startswith('凡例'):
legend = 'on'
if len(x_list) == 0:
print('X値が設定されていません。dx-2_header.txtのX値を設定したい項目の先頭に X: をつけて再度実行してください。')
elif len(x_list) >= 2:
print('X値が2つ以上設定されています。設定できるX値の数は1つです。')
elif len(y_list) == 0:
print('Y値が設定されていません。dx-2_header.txtのY値を設定したい項目の先頭に Y: をつけて再度実行してください。')
else:
print(f'X値:{x_list}、X軸ラベル名:{x_label}')
print(f'Y値:{y_list}、Y軸ラベル名:{y_label}')
if legend == 'on':
print('凡例:表示')
elif legend == 'off':
print('凡例:非表示')
for csv in csv_list:
print(f'{csv}.csvファイルのグラフを作成します。')
df = pd.read_csv(f'./{csv}.csv', encoding='utf-8', index_col=0)
fig = plt.figure(figsize=(8,6))
plt.clf()
for y_name in y_list:
if y_name in df.keys():
plt.plot(df[x_list[0]], df[y_name], label=y_name)
if legend == 'on':
plt.legend(fontsize=14)
plt.xticks(fontsize=16);plt.yticks(fontsize=16)
if x_label != '':
plt.xlabel(x_label, fontsize=18)
if y_label != '':
plt.ylabel(y_label, fontsize=18)
plt.tight_layout()
plt.savefig(f'./{csv}.png')
print(f'{csv}.csvファイルのグラフを保存しました。')
print('処理が完了しました。')
else:
key_list = []
for csv in csv_list:
df = pd.read_csv(f'./{csv}.csv', encoding='utf-8', index_col=0)
for key in df.keys():
if not key in key_list:
key_list.append(key)
with open('dx-2_header.txt', 'w', encoding='utf-8') as f_out:
for key in key_list:
f_out.write(f'{key}\n')
f_out.write('\n')
f_out.write('X軸名:\n')
f_out.write('Y軸名:\n')
f_out.write('凡例')
print('dx-2_header.txtに項目名を出力しました。')
print('ファイルを開き、出力するグラフのX値の前に X: を、Y値の前に Y: をつけて、再度実行してください。')
print('X値は必ず1つ必要で、Y値の個数には制限はありません。')
print('また、どちらも付けられていない値に関してはプロットされません。')
print('X軸名、Y軸名が必要な場合はそれぞれ X軸名: 、Y軸名: の後ろに記入してください。')
print('凡例がいらない場合は、凡例の行を消してください。')
def main():
timenow = timenow = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
csv_list, text_list = filenameGet()
print(f'CSVファイル:{csv_list}')
print(f'TEXTファイル:{text_list}')
fileProcess(csv_list, text_list, timenow)
print('このウインドウは10秒後に自動で閉じますので、そのままお待ちください。')
time.sleep(10)
if __name__ == '__main__':
main()ライブラリのインポート
今回使用するライブラリは「os」、「time」、「datetime」、「matplotlib」、「pandas」です。
import os
import time
import datetime
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import pandas as pd「pandas」と「matplotlib」は外部ライブラリなので、使用する前にインストールが必要です。
pip install pandas
pip install matplotlibmatplotlibのフォント設定
次にmatplotlibのフォント設定をしています。
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro', 'Yu Gothic', 'Meirio', 'Takao', 'IPAexGothic', 'IPAPGothic', 'Noto Sans CJK JP']matplotlibは初期設定では日本語は使えません。
その理由としてはデフォルトのフォントが日本語に対応していないためです。
そのため日本語が必要な場合は、日本語が使えるフォントを別途指定してやる必要があります。
上記の2行のプログラムはWindowsでもMacでもLinuxでも日本語が使えるようになっているそうです。
詳しくはこちらの記事で紹介されていますので、よかったらどうぞ。

filenameGet関数
これは前回も出てきましたが、処理するファイルのファイル名を取得するための関数です。
def filenameGet():
csv_list = []; text_list =[]
for filename in os.listdir('./'):
if filename.startswith('dx-2_'):
if filename.endswith('.csv'):
csv_list.append(filename[:-4])
elif filename == 'dx-2_header.txt':
text_list.append(filename)
return csv_list, text_list前回同様、頭に「dx-2_」がついた処理するファイルと1回目の実行で生成される項目名が記載されているファイル(dx-2_header.txt)をリストに格納して、この関数の実行結果として返します。
fileProcess関数
ファイルを処理するための関数です。
処理が大きく4つに分かれているので、別々に見ていきましょう。
fileProcess関数 その1:データの抽出
fileProcess関数 その1は「dx-2_header.txt」から出力する項目を取得する部分です。
if 'dx-2_header.txt' in os.listdir('./'):
x_list = []; y_list = []; legend = 'off'
with open('./dx-2_header.txt', 'r') as f_in:
for row in f_in:
if row.startswith('X:'):
x_list.append(row.split(':')[1].replace('\n',''))
elif row.startswith('Y:'):
y_list.append(row.split(':')[1].replace('\n',''))
elif row.startswith('X軸名:'):
x_label = row.split(':')[1].replace('\n','')
elif row.startswith('Y軸名:'):
y_label = row.split(':')[1].replace('\n','')
elif row.startswith('凡例'):
legend = 'on'「dx-2_header.txt」を1行ずつ読み込み、先頭に「X:」、「Y:」、「X軸名:」、「Y軸名:」、「凡例」がついているものをそれぞれリストに格納します。
またその際、改行コード(\n)を削除するため、「.replace(‘\n’,”)」で改行コードを置換しています。
fileProcess関数 その2:データの判定
fileProcess関数 その2はその1で取得した項目が正しく設定されているか判定する部分です。
if len(x_list) == 0:
print('X値が設定されていません。dx-2_header.txtのX値を設定したい項目の先頭に X: をつけて再度実行してください。')
elif len(x_list) >= 2:
print('X値が2つ以上設定されています。設定できるX値の数は1つです。')
elif len(y_list) == 0:
print('Y値が設定されていません。dx-2_header.txtのY値を設定したい項目の先頭に Y: をつけて再度実行してください。')
else:
print(f'X値:{x_list}、X軸ラベル名:{x_label}')
print(f'Y値:{y_list}、Y軸ラベル名:{y_label}')
if legend == 'on':
print('凡例:表示')
elif legend == 'off':
print('凡例:非表示')重要なのはX値が1つだけ設定されていること、つまり設定されていなかったり、2つ以上だった場合はエラーとなることです。
またY値も設定されているかどうかを判定して、設定されていない場合はエラーの表示をしています。
軸名や凡例に関しては、グラフを作成するのに特に重要ではないので判定せず、とりあえず表示させています。
fileProcess関数 その3:グラフ作成部分
fileProcess関数 その3はCSVファイルを開き、グラフを作成する部分です。
for csv in csv_list:
print(f'{csv}.csvファイルのグラフを作成します。')
df = pd.read_csv(f'./{csv}.csv', encoding='utf-8', index_col=0)
fig = plt.figure(figsize=(8,6))
plt.clf()
for y_name in y_list:
if y_name in df.keys():
plt.plot(df[x_list[0]], df[y_name], label=y_name)
if legend == 'on':
plt.legend(fontsize=14)
plt.xticks(fontsize=16);plt.yticks(fontsize=16)
if x_label != '':
plt.xlabel(x_label, fontsize=18)
if y_label != '':
plt.ylabel(y_label, fontsize=18)
plt.tight_layout()
plt.savefig(f'./{csv}.png')
print(f'{csv}.csvファイルのグラフを保存しました。')
print('処理が完了しました。')「for csv in csv_list:」でリストに格納されているCSVファイル名を取得し、「df = pd.read_csv(f’./{csv}.csv’, encoding=’utf-8′, index_col=0)」で読み込みつつ、pandasのデータフレームに格納します。
「fig = plt.figure(figsize=(8,6))」でグラフエリアを確保し、「plt.clf()」で一度グラフエリアの中身を消去します。
「for y_name in y_list:」をY値の項目名のリストから順々にY値の項目名を取得し、「if y_name in df.keys():」でデータフレーム(つまり読み込んだCSVファイル)にそのY値の項目名があるかを判定します。
Y値の項目名があった場合は「plt.plot(df[x_list[0]], df[y_name], label=y_name)」でプロットしています。
凡例に関しては「if legend == ‘on’:」で判定をし、「plt.legend(fontsize=14)」で凡例を表示させています。
「plt.xticks(fontsize=16);plt.yticks(fontsize=16)」は軸の数値に関する項目で、フォントサイズを16に固定しています。
「if x_label != ”:」と「if y_label != ”:」で「X軸名:」、「Y軸名:」に記載があった場合は「plt.xlabel(x_label, fontsize=18)」と「plt.ylabel(y_label, fontsize=18)」でフォントサイズを18として出力しています。
「plt.tight_layout()」でグラフが外に飛び出ないように自動で調節させて、「plt.savefig(f’./{csv}.png’)」でグラフのpngファイルを保存しています。
fileProcess関数 その4:項目ファイルの作成
fileProcess関数 その4は、項目ファイルである「dx-2_header.txt」を作成している部分です。
else:
key_list = []
for csv in csv_list:
df = pd.read_csv(f'./{csv}.csv', encoding='utf-8', index_col=0)
for key in df.keys():
if not key in key_list:
key_list.append(key)
with open('dx-2_header.txt', 'w', encoding='utf-8') as f_out:
for key in key_list:
f_out.write(f'{key}\n')
f_out.write('\n')
f_out.write('X軸名:\n')
f_out.write('Y軸名:\n')
f_out.write('凡例')
print('dx-2_header.txtに項目名を出力しました。')
print('ファイルを開き、出力するグラフのX値の前に X: を、Y値の前に Y: をつけて、再度実行してください。')
print('X値は必ず1つ必要で、Y値の個数には制限はありません。')
print('また、どちらも付けられていない値に関してはプロットされません。')
print('X軸名、Y軸名が必要な場合はそれぞれ X軸名: 、Y軸名: の後ろに記入してください。')
print('凡例がいらない場合は、凡例の行を消してください。')こちらではfileProcess関数の前半部分で使用したコマンドばかりなので、多くは解説しません。
やっていることとしては、それぞれのCSVファイルを読み込み、列の項目名を抽出し、「dx-2_header.txt」に書き込んでいます。
main関数
main関数ではfilenameGet関数とfileProcess関数を実行しています。
def main():
timenow = timenow = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
csv_list, text_list = filenameGet()
print(f'CSVファイル:{csv_list}')
print(f'TEXTファイル:{text_list}')
fileProcess(csv_list, text_list, timenow)
print('このウインドウは10秒後に自動で閉じますので、そのままお待ちください。')
time.sleep(10)
if __name__ == '__main__':
main()注意すべき点
注意すべき点としては、以下の通りです。
- 処理できるのはCSVファイルのみ
- CSVファイルの形式が制限
- X軸1つまでY軸1つまでに制限
- WindowsとMacでは改行コード(Macでは「\n」)が違う可能性
1つ目と4つ目の項目に関しては前回と同様です。
今回はさらに2つ目の「CSVファイルの形式が制限」と3つ目の「X軸1つまでY軸1つまでに制限」が追加されました。
2つ目に関してはCSVファイルの形式が1行目が項目名、2行目以降が値である必要があるということです。
例えばデータの出どころが測定器だった場合、最初に測定器特有のヘッダーが追加されたりします。
その場合はこのプログラムでは正しく処理することはできません。
また1列目が項目名で、2列目以降が値という縦と横が入れ替わっている場合も処理できません。
ということで入力するデータの形式を気にする必要があるわけです。
ここら辺のデータの前処理のプログラムは後々作成することにしましょう。
3つ目の「X軸1つまでY軸1つまでに制限」に関しては、Y値を複数表示する場合、値の差が大きいとY軸を分けて表示したい場合もあるでしょう。
つまりこちらの記事にあるようにY軸を左右に分けて2軸で表示するということです。
今回のプログラムではあくまでも簡単に使用できるようX軸もY軸も1つずつしか設定できないようになっています。
ということでせっかくなのでY軸を2軸にするようなプログラムもまた後々作成してみることにしましょう。
ということでとりあえずCSVファイルのデータをグラフにするプログラムはこんな感じです。
良かったら、使ってみたり、いじってみたりしてください。
次回は、このプログラムを試すためのデータを作成したプログラムを紹介します。
ではでは今回はこんな感じで。
コメント