DX(デジタルトランスフォーメーション)
前回、Pythonで始めるなんちゃってDXとして、表の項目を抽出するプログラムを紹介しました。
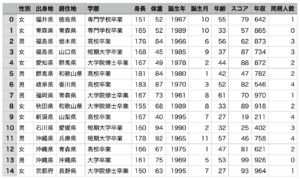
その際にこんなデータを使いました。
(CSVファイルなので、テキストエディタで開くとカンマ区切りです)
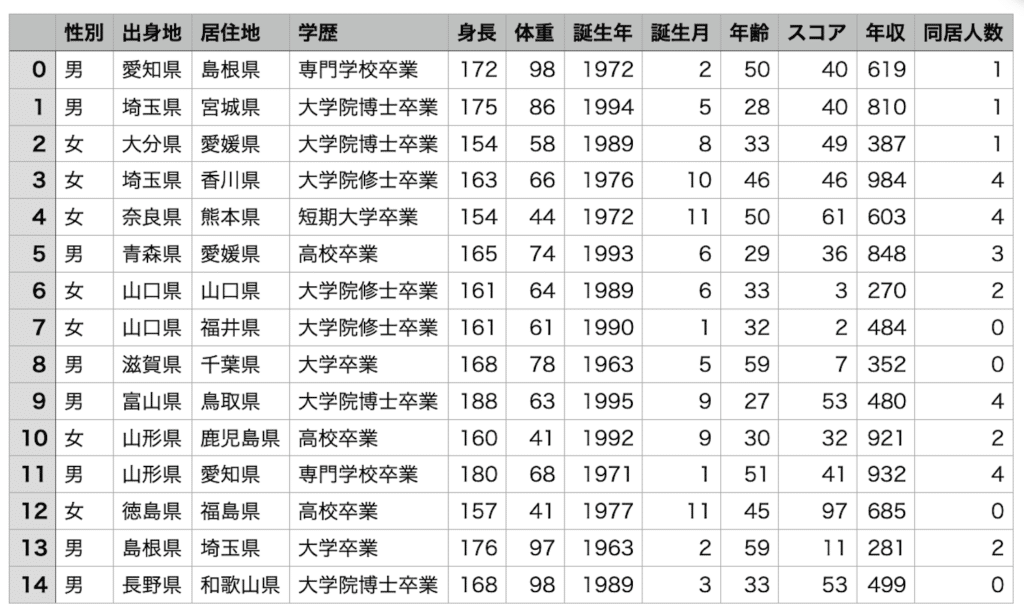
見た目的に個人情報満載なデータですが、こんなものを何処かから持ってきたらそれは大問題なわけです。
ということでこんなデータを出力するプログラムを作成し、前回使用したというわけです。
今回はせっかくなので、こちらのデータ作成プログラムについても紹介していこうと思います。
プログラム全体
まずはプログラム全体をみてみましょう。
import random
import os
import pandas as pd
num_people = 15
sex_list = ['男','女']
prefectures_list = ['北海道','青森県','岩手県','宮城県','秋田県','山形県','福島県','茨城県','栃木県','群馬県','埼玉県',
'千葉県','東京都','神奈川県','新潟県','富山県','石川県','福井県','山梨県','長野県','岐阜県','静岡県',
'愛知県','三重県','滋賀県','京都府','大阪府','兵庫県','奈良県','和歌山県','鳥取県','島根県','岡山県',
'広島県','山口県','徳島県','香川県','愛媛県','高知県','福岡県','佐賀県','長崎県','熊本県','大分県',
'宮崎県','鹿児島県','沖縄県']
eb_list = ['高校卒業','専門学校卒業','短期大学卒業','大学卒業','大学院修士卒業','大学院博士卒業']
df = pd.DataFrame()
df['性別'] = random.choices(sex_list, k=num_people)
df['出身地'] = random.choices(prefectures_list, k=num_people)
df['居住地'] = random.choices(prefectures_list, k=num_people)
df['学歴'] = random.choices(eb_list, k=num_people)
height_list = []; weight_list = []
for i in range(len(df)):
data = df.iloc[i]
if data['性別'] == '男':
height_list.append(random.choice(range(160, 190)))
weight_list.append(random.choice(range(60, 100)))
elif data['性別'] == '女':
height_list.append(random.choice(range(150, 170)))
weight_list.append(random.choice(range(40, 70)))
df['身長'] = height_list; df['体重'] = weight_list
df['誕生年'] = random.choices(range(1960, 2000), k=num_people)
df['誕生月'] = random.choices(range(1, 12), k=num_people)
df['年齢'] = 2022 - df['誕生年']
df['スコア'] = random.choices(range(0, 100), k=num_people)
df['年収'] = random.choices(range(200, 1000), k=num_people)
df['同居人数'] = random.choices(range(0, 5), k=num_people)
df1 = df.iloc[:,[0,1,2,3,8,9,10]]
df1.to_csv('./dx-1_Data1.csv', encoding='utf-8')
df2 = df.iloc[:,[0,1,4,5,8]]
df2.to_csv('./dx-1_Data2.csv', encoding='utf-8')
df3 = df
df3.to_csv('./dx-1_Data3.csv', encoding='utf-8')このプログラムはあくまでも一時的に利用できればいいと思い、綺麗にまとめたり、自動化したりはしていません。
ということでダミーデータが必要な時とか、勉強用に使用してもらえればいいかなと思います。
ライブラリのインポートと設定
まずはライブラリのインポートと設定の部分からです。
import random
import os
import pandas as pd
num_people = 15
sex_list = ['男','女']
prefectures_list = ['北海道','青森県','岩手県','宮城県','秋田県','山形県','福島県','茨城県','栃木県','群馬県','埼玉県',
'千葉県','東京都','神奈川県','新潟県','富山県','石川県','福井県','山梨県','長野県','岐阜県','静岡県',
'愛知県','三重県','滋賀県','京都府','大阪府','兵庫県','奈良県','和歌山県','鳥取県','島根県','岡山県',
'広島県','山口県','徳島県','香川県','愛媛県','高知県','福岡県','佐賀県','長崎県','熊本県','大分県',
'宮崎県','鹿児島県','沖縄県']
eb_list = ['高校卒業','専門学校卒業','短期大学卒業','大学卒業','大学院修士卒業','大学院博士卒業']
df = pd.DataFrame()今回使用しているライブラリは「random」、「os」、「pandas」の3種類です。
「num_people」は出力する人数です。
その後の「sex_list」、「prefectures_list」、「eb_list」はそれぞれ性別、都道府県、最終学歴を選択するために使用するリストです。
「df = pd.DataFrame()」でPandasのデータフレームを新規に作成し、ここに各個人のデータを格納していきます。
ちなみに今回は一人ずつのデータを作成するのではなく(要するに行ごとではなく)、項目ごと(列ごと)でデータを作成していきます。
この後にランダムにデータを収集していくのですが、タイプごとに3つに分けて解説していきましょう。
リストからランダムに取得する項目
まずはリストからランダムに選択する項目です。
先ほど性別や都道府県、最終学歴のリストを作ったので、そこからrandomモジュールの「choices」を使ってランダムに人数分のデータを抽出しています。
random.choicesは「random.choices(抽出元のリスト, k=抽出する数)」です。
df['性別'] = random.choices(sex_list, k=num_people)
df['出身地'] = random.choices(prefectures_list, k=num_people)
df['居住地'] = random.choices(prefectures_list, k=num_people)
df['学歴'] = random.choices(eb_list, k=num_people)ちなみにrandomモジュールはこちらの記事で解説していますので、よかったらどうぞ。

条件からランダムに取得する範囲を変える項目
次は条件からランダムに取得する範囲を変える項目です。
なんのことか分かりにくいですが、単純にいうと身長、体重は男女差があるので、単純にランダムに取得するよりは、男女で条件分岐させ、それぞれの範囲からランダムに取得する方が現実味があるかなと思います。
ということでこんな感じ。
height_list = []; weight_list = []
for i in range(len(df)):
data = df.iloc[i]
if data['性別'] == '男':
height_list.append(random.choice(range(160, 190)))
weight_list.append(random.choice(range(60, 100)))
elif data['性別'] == '女':
height_list.append(random.choice(range(150, 170)))
weight_list.append(random.choice(range(40, 70)))
df['身長'] = height_list; df['体重'] = weight_list先ほど作成した性別の項目を読み込み、値の「男女」で分岐させています。
そしてrandom.choice(抽出元のリスト)でランダムに値を一つ取得しています。
抽出元のリストは範囲からリストを作成する「range(範囲の開始, 範囲の終了)」で作成しています。
先ほどのrandom.choicesは複数の値を重複ありで取得するコマンドで、こちらのrandom.choiceは一つの値を取得します。
rangeに関しては、こちらの記事で解説していますので、良かったらどうぞ。

特定の範囲からランダムに取得する項目
ここからは特定の範囲からランダムに取得する項目です。
こちらもrandom.choices(抽出元のリスト, k=抽出する数)とrange(開始, 終了)を組み合わせて、それぞれ値を取得しています。
df['誕生年'] = random.choices(range(1960, 2000), k=num_people)
df['誕生月'] = random.choices(range(1, 12), k=num_people)
df['年齢'] = 2022 - df['誕生年']
df['スコア'] = random.choices(range(0, 100), k=num_people)
df['年収'] = random.choices(range(200, 1000), k=num_people)
df['同居人数'] = random.choices(range(0, 5), k=num_people)年齢だけは「df[‘年齢’] = 2022 – df[‘誕生年’]」のように列のデータと特定の値から一括に計算しています。
ここらへんがPandasの使いやすいところですね。
データの出力
最後にデータの出力です。
今回はファイルによって、保存されているデータが異なるように設定しています。
その方法としては、ここまでに作成した元のデータフレームから一部分を新しいデータフレームに移し、それを「データフレーム名.to_csv(‘ファイルパス’)」で出力する方法です。
df1 = df.iloc[:,[0,1,2,3,8,9,10]]
df1.to_csv('./dx-1_Data1.csv', encoding='utf-8')
df2 = df.iloc[:,[0,1,4,5,8]]
df2.to_csv('./dx-1_Data2.csv', encoding='utf-8')
df3 = df
df3.to_csv('./dx-1_Data3.csv', encoding='utf-8')ここで使っている「.iloc」は「.iloc[行, 列]」とすることで、特定の範囲のデータを取得できるコマンドです。
そこで「df.iloc[:,[0,1,2,3,8,9,10]]」とすることで、すべての行の[0, 1, 2, 3, 8, 9, 10]列のデータのみ取得できます。
それを新しいデータフレーム「df1」に移し、「.to_csv」で出力しています。
またデータには日本語が含まれていますので、「encording=’utf-8’」を追加しています。
こうして出力されたデータがこちらです。
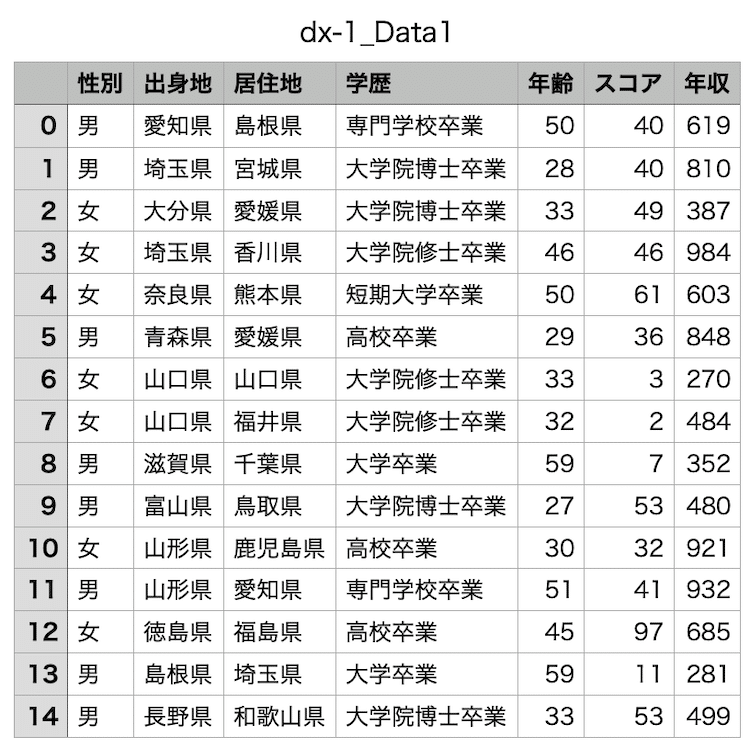
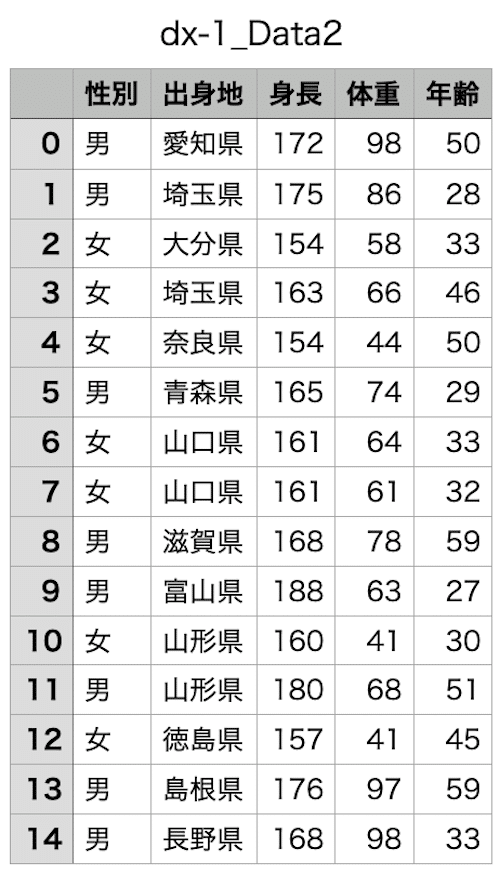
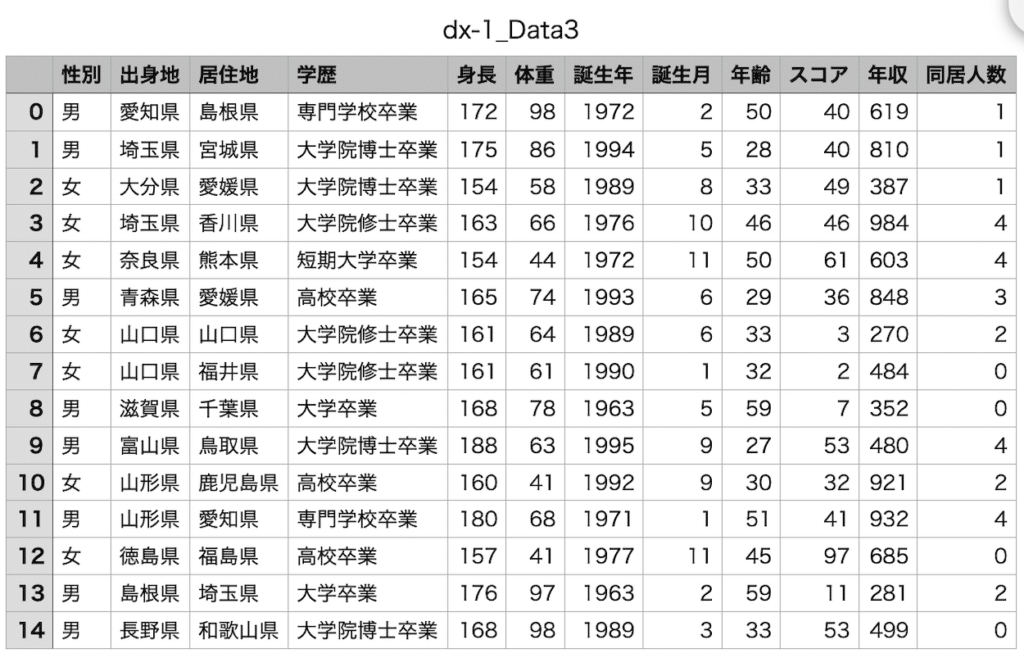
もっとリアリティのあるデータにするには、まだまだいじっていくところがあるのでしょうが、とりあえずダミーデータとしていい感じのデータを出力してくれると思っています。
次回は簡単にグラフを作成するプログラムを紹介します。
ではでは今回はこんな感じで。
コメント