機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnの手書き数字のデータセットを使って、自分で作った手書き数字から実際にどの数字なのか予想させてみました。
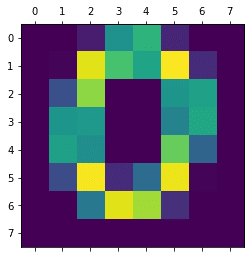
その機械学習モデルとしては「LinearSVC」を使ってきました。
この手書き数字のデータセットに関しては、かなりいい精度で予想してくれて、なかなか良いモデルなのですが、せっかくなら他のモデルも試していこうというのが今回の内容です。
前に機械学習のモデルを検討した際、「LinearSVC」がダメだった場合はこんな感じでした。
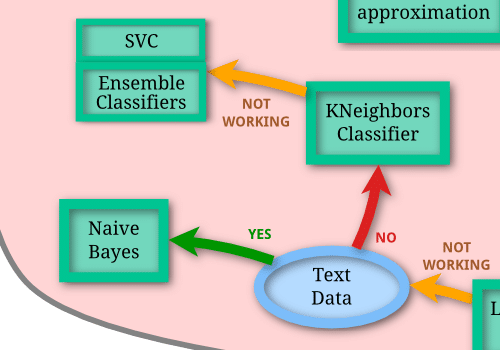
「Naive Bayes」は文章のようなテキストデータに使うものなので今回のデータセットでは除外。
ということで「KNeighborsClassifier」を試して、ダメなら「SVC」、「EnsembleClassifiers」を試すという流れになります。
「EnsembleClassifiers」はちょっと特殊な機械学習モデルのようなので、今回は「LinearSVC」の元の機械学習モデルである「SVC」と「KNeighborsClassifier」を試してみましょう。
最初はデータの読み込みからです。
<セル1>
from sklearn.datasets import load_digits
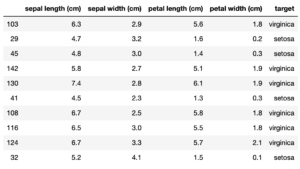
digits = load_digits(as_frame=True)
digits.frame
実行結果
また比較対象として「LinearSVC」モデルを使った機械学習をやっておきます。
<セル2>
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = digits.frame.iloc[:, 0:-1]
y = digits.frame.iloc[:, -1]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = LinearSVC(max_iter=1000000)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.9583333333333334それでは始めていきましょう。
SVC:Support Vector machine Classifier
SVCは前に使った「LinearSVC」のもとになる機械学習モデルです。
またSupport Vector machine Classifierということで、前にちょっと解説したサポートベクターマシンの分類バージョンであることが分かります。
つまりサポートベクターマシンで分類するモデルが今回のSVCモデルで、その中の分類方法を「Linear」 とすると「LinearSVC」 になるというわけです。
またそのうちにオプションに関しては詳しい解説をしたいと思いますので、今回はとりあえず使ってみましょう。
先ほどの「LinearSVC」のプログラムで「from sklearn.svm import LinearSVC」を「from sklearn.svm import SVC」に変え、「model = LinearSVC(max_iter=1000000)」を「model = SVC()」に変えるだけです。
<セル3>
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = digits.frame.iloc[:, 0:-1]
y = digits.frame.iloc[:, -1]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = SVC()
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.9888888888888889こちらもかなり良いスコアが出ました。
ちなみにLinearSVCだと、kernelというオプションが「linear」になるようです。
デフォルトでは「rbf」となっていて、ちょっとだけですがスコアの違いがあるのは、このkernelのオプションからきているかもしれません。
KNeighborsClassifier:K近傍法
「KNeighborsClassifier」は先にでてきたSVCとはまた違う思想の機械学習モデルです。
こちらの場合はある点から近いところにあるデータを同じカテゴリであると認識します。
Qiitaに概念をざっくりと解説している記事があったのでリンクを貼っておきます。

こちらも試してみましょう。
「SVC」の時と同様にインポートするライブラリを変え、モデルの読み込みを変えるだけです。
<セル4>
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
x = digits.frame.iloc[:, 0:-1]
y = digits.frame.iloc[:, -1]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model = KNeighborsClassifier()
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
実行結果
0.9888888888888889こちらもかなり良いスコアが出ました。
今回のデータセットはかなり優しいデータセットのようで、どのモデルでも良いスコアが出ています。
それでももう少しモデル探索の旅を続けてみることにしましょう。
次回は今回後回しにした「EnsembleClassifiers」を試してみることにしましょう。

ということで今回はこんな感じで。
コメント