tweepy
前回、PythonのTwitter API制御ライブラリtweepyを使って、条件に合うアカウント名をLINEに通知してみました。
今回はもう少しtweepyの使い方を発展させて、特定のワードで検索をかけた後、条件に合うアカウントを抽出し、前回同様LINEに通知してみようと思います。
どんなワードで検索かけるかというと、おはよう戦隊のハッシュタグを検索してみようと思います。
ちなみにおはよう戦隊をご存知ない方は、発起人であるひーさんのアカウントをご覧ください。
前におはよう戦隊ハッシュタグ作成プログラムを作成していますので、こちらを使っていきます。
ちなみにこのおはよう戦隊ハッシュタグ作成プログラムの部分とTwitter APIの部分、前回のLINE通知の部分の解説は省略しますので、その部分に関しては過去の記事をご覧いただけますようお願い致します。
それでは始めていきましょう。
プログラム全体
まずはプログラム全体をお見せします。
import tweepy
from datetime import date
import requests
followers = 5000
timenow = date.today()
account = "@account_name"
consumer_key = ' consumer key '
consumer_secret = ' consumer secret '
access_token = ' access token '
access_token_secret = ' access token secret '
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth, wait_on_rate_limit = True)
line_notify_token = ' 取得したアクセストークン '
line_notify_api = 'https://notify-api.line.me/api/notify'
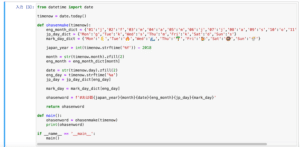
def ohasenmake(timenow):
eng_month_dict = {'01':'j','02':'f','03':'m','04':'a','05':'m','06':'j','07':'j','08':'a','09':'s','10':'o','11':'n','12':'d'}
jp_day_dict = {'Mon':'g','Tue':'k','Wed':'s','Thu':'m','Fri':'k','Sat':'d','Sun':'n'}
mark_day_dict = {'Mon':'🌜','Tue':'🔥','Wed':'🌊','Thu':'🌴','Fri':'🍺','Sat':'🍩','Sun':'🍨'}
japan_year = int(timenow.strftime('%Y')) - 2018
month = str(timenow.month).zfill(2)
eng_month = eng_month_dict[month]
date = str(timenow.day).zfill(2)
eng_day = timenow.strftime('%a')
jp_day = jp_day_dict[eng_day]
mark_day = mark_day_dict[eng_day]
ohasenword = f'#おは戦{japan_year}{month}{date}{eng_month}{jp_day}{mark_day}'
return ohasenword
def searchtweet(ohasenword):
tweets = api.search(q=ohasenword, count=100)
return tweets
def collecttweets(tweets):
collected_accounts = []
collected_tweetids = []
for tw in tweets:
if not (tw.text.startswith('RT')) or (tw.text.startswith('@')):
if tw.user.followers_count >= followers:
if not tw.id in collected_tweetids:
collected_accounts.append(tw.user.screen_name)
collected_tweetids.append(tw.id)
return collected_accounts, collected_tweetids
def sendlinemessage(collected_accounts, collected_tweetids):
headers = {'Authorization': f'Bearer {line_notify_token}'}
message = '\nおはよう戦隊挨拶回り\n'
for user, twid in zip(collected_accounts, collected_tweetids):
user_url = f'https://twitter.com/{user}/status/{twid}'
message = message + user_url + '\n'
data = {'message': message}
requests.post(line_notify_api, headers = headers, data = data)
def main():
ohasenword = ohasenmake(timenow)
tweets = searchtweet(ohasenword)
collected_accounts, collected_tweetids = collecttweets(tweets)
sendlinemessage(collected_accounts, collected_tweetids)
if __name__ == '__main__':
main()プログラムの大まかな流れとしては、こんな感じです。
- おはよう戦隊のハッシュタグを作成する
- Tweepyを使って、おはよう戦隊のハッシュタグで検索をかける
- 検索結果で得られたツイートの中からフォロワー数が指定値以上のアカウントのツイート情報を取得する
- 取得したツイート情報をLINEで通知する
設定部分、おはよう戦隊ハッシュタグ部分
設定部分はほぼ過去の記事そのままですが、先ほどの大まかな流れのうち、3番目の「検索結果で得られたツイートの中からフォロー数が指定値以上のアカウントのツイート情報を取得する」ということから、フォロワー数の指定をしています。
followers = 5000次におはよう戦隊ハッシュタグ部分ですが、これは過去記事のままなので、今回解説は割愛します。
tweepyによる検索
tweepyを使って検索をかける関数「searchtweet」を定義しています。
def searchtweet(ohasenword):
tweets = api.search(q=ohasenword, count=100)
return tweetsここで重要なのは検索をかける場合は「api.search(q=’検索をかけるワード’, count=’取得するツイート数’)」だということです。
おさらいになりますが、特定のアカウントのツイートのタイムラインを取得する場合は「tweepy.Cursor(api.user_timeline, id=’アカウント名’).items(取得するツイート数)」、また特定のアカウントのホームタイムラインを取得する場合は「tweepy.Cursor(api.home_timeline, id=’アカウント名’).items(取得するツイート数)」でした。
少しコマンドを変えるだけで色々な取得方法ができるのはいいですね。
ということでこれで検索で特定のツイートを取得することができました。
ツイート情報の取得
次に検索結果の中から特定のツイートを抽出します。
今回の場合は、「おはよう戦隊のハッシュタグをついているツイートのうち、ツイートしたアカウントのフォロワーがX人以上のツイートとアカウント名」を取得します。
def collecttweets(tweets):
collected_accounts = []
collected_tweetids = []
for tw in tweets:
if not (tw.text.startswith('RT')) or (tw.text.startswith('@')):
if tw.user.followers_count >= followers:
if not tw.id in collected_tweetids:
collected_accounts.append(tw.user.screen_name)
collected_tweetids.append(tw.id)
return collected_accounts, collected_tweetidsまず最初にアカウント名とツイートIDを格納するためのリストを用意しています。
collected_accounts = []
collected_tweetids = []ここでアカウント名とツイートIDを取得するのには理由があります。
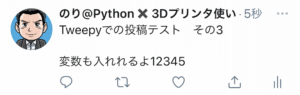
例えば私のこのツイート。
このツイートに直接アクセスするためのURLはこんな感じです。
https://twitter.com/GomiDeMoso/status/1432847952976875521つまり「https://twitter.com/アカウント名/status/ツイートID」ということなので、アカウント名とツイートIDを取得する必要があるというわけです。
ただ取得する前に条件を満たすツイートを抽出します。
それがこの3行です。
if not (tw.text.startswith('RT')) or (tw.text.startswith('@')):
if tw.user.followers_count >= followers:
if not tw.id in collected_tweetids:1行目でリツイートとメンションに関しては除外します。
これで最初にツイートされたものだけ取得できます。
そして2行目でフォロワーの数を指定数と比較し、指定数よりも多いものを抽出します。
3行目ではプログラムの一回の実行時に、もし同じツイートIDのものが取得されたら、それはリストに追加しないよう除外しています(もしかしたら必要ないかもしれません)。
抽出されたツイートからアカウント名(tw.user.screen_name)とツイートID(tw.id)を取得し、リストに追加します。
そして最終的にアカウント名とツイートIDがそれぞれ格納されたリストを返します。
LINEへの通知
得られたアカウント名とツイートIDから、ツイートへ直接アクセスできるURLを作成し、LINEへ通知します。
def sendlinemessage(collected_accounts, collected_tweetids):
headers = {'Authorization': f'Bearer {line_notify_token}'}
message = '\nおはよう戦隊挨拶回り\n'
for user, twid in zip(collected_accounts, collected_tweetids):
user_url = f'https://twitter.com/{user}/status/{twid}'
message = message + user_url + '\n'
data = {'message': message}
requests.post(line_notify_api, headers = headers, data = data)ここに関しては前々回、前回の記事と大きく変わっていませんので、それらの記事を参考にしてください。
あとはmain関数ですが、ここまでの関数を組み合わせているだけですので、解説は割愛します。
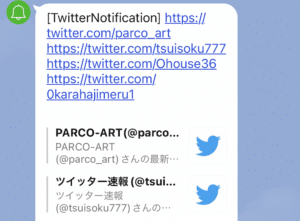
ということで今回のプログラムを実行するとこんな感じです。
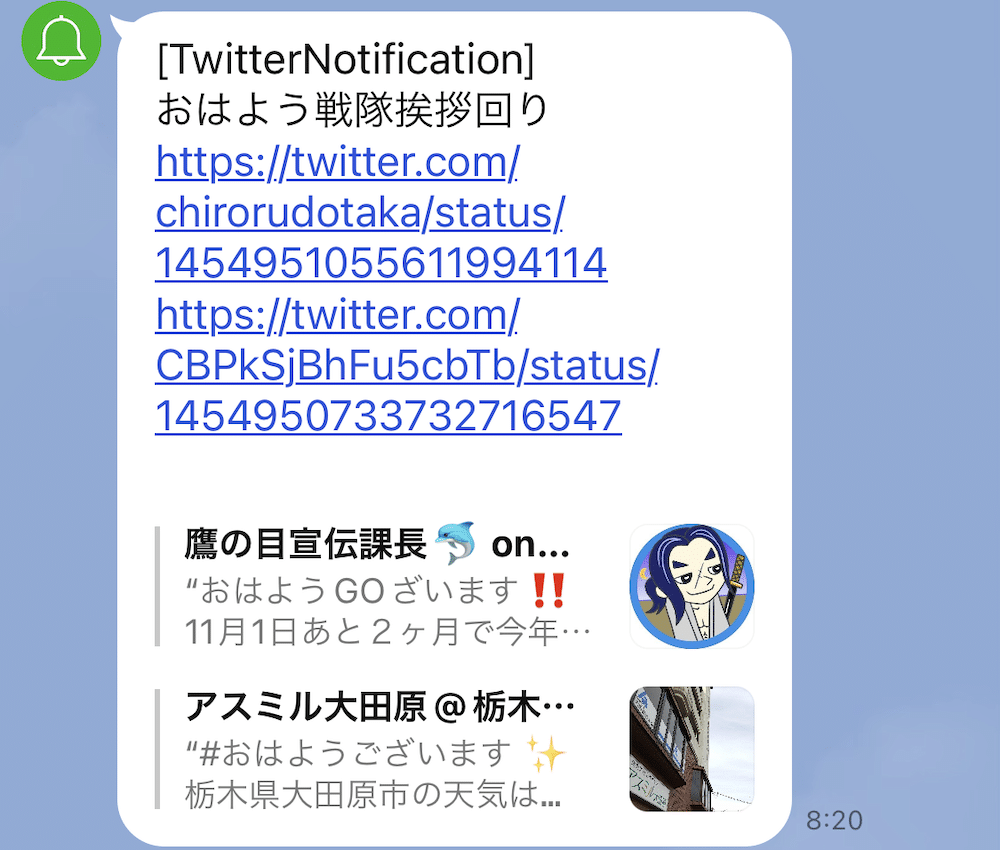
今回は手っ取り早くツイートした人のフォロワー数を条件としていますが、例えば他に特定の言葉が入っている人を抽出しても面白いかもしれません。
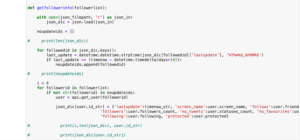
次回はtweepyを使ってフォロワー情報をまとめてみようと思います。
ではでは今回はこんな感じで。
コメント