機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnの糖尿病患者のデータセットを使い、SVRモデルのkernelのうち、polyのオプションを色々と試してみました。
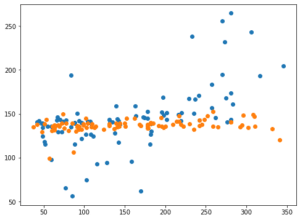
ただこれまで何回かに分けて、オプションを色々といじってきたのですが、なかなか予想精度のスコアが満足に上がりませんでした。
ということでどこに原因があるのかと考えたところ、一つは機械学習で使用する特徴量の数が悪いのではないかと考えました。
特徴量の数としては、こちらの記事で相関マップを描き、選択しました。
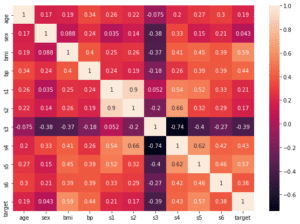
しかし数値で出ているとはいえ、これは人間が選択したもの。
もっと機械的にどの特徴量を選んだらいいのか、抽出できないかと思うわけです。
ということで今回は特徴量の組み合わせ全てに対して機械学習を行い、予想精度のスコアを計算するプログラムを作成してみようと思います。
いつも通りデータの読み込みから。
<セル1>
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df["target"] = diabetes.target
df
実行結果
全ての組み合わせを取得
今回のプログラムで一番重要なのは、全ての組み合わせを取得する方法です。
実はこれは「itertools」というライブラリの中に含まれるので今回はそれを使わせてもらいましょう。
まずはどういうものか確認してみます。
<セル2>
import itertools
comb_list = itertools.combinations(diabetes.feature_names, 9)
for comb in comb_list:
print(comb)
実行結果
('age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5')
('age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's6')
('age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's5', 's6')
('age', 'sex', 'bmi', 'bp', 's1', 's2', 's4', 's5', 's6')
('age', 'sex', 'bmi', 'bp', 's1', 's3', 's4', 's5', 's6')
('age', 'sex', 'bmi', 'bp', 's2', 's3', 's4', 's5', 's6')
('age', 'sex', 'bmi', 's1', 's2', 's3', 's4', 's5', 's6')
('age', 'sex', 'bp', 's1', 's2', 's3', 's4', 's5', 's6')
('age', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6')
('sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6')「itertools.combinations(diabetes.feature_names, 9)」というのは、diabetes.feature_namesのリストから9個抽出することでできる全ての組み合わせという意味です。
つまり「itertools.combinations(リスト, 抽出する数)」というわけです。
そして取得した組み合わせをfor文を使って一つずつ表示させているというわけです。
今回は特定の数ではなく、作成可能な組み合わせ全てを作成したいので、こんな感じにしてみました。
<セル2 特徴量の全ての組み合わせを取得1>
import itertools
for i in range(1, len(diabetes.feature_names)+1):
comb_list = itertools.combinations(diabetes.feature_names, i)
for comb in comb_list:
print(comb)
実行結果
('age',)
('sex',)
('bmi',)
('bp',)
('s1',)
('s2',)
(中略)
('age', 'sex', 'bmi', 's1', 's2', 's3', 's4', 's5', 's6')
('age', 'sex', 'bp', 's1', 's2', 's3', 's4', 's5', 's6')
('age', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6')
('sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6')
('age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6')これで糖尿病データセットの特徴量10個に対する全ての組み合わせを取得できました。
最後に省略できるところを省略して、もう少し見栄え良くしておきましょう。
<セル2 特徴量の全ての組み合わせを取得2>
import itertools
for i in range(1, len(diabetes.feature_names)+1):
for comb in itertools.combinations(diabetes.feature_names, i):
print(comb)
実行結果
('age',)
('sex',)
('bmi',)
('bp',)
('s1',)
('s2',)
(中略)
('age', 'sex', 'bmi', 's1', 's2', 's3', 's4', 's5', 's6')
('age', 'sex', 'bp', 's1', 's2', 's3', 's4', 's5', 's6')
('age', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6')
('sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6')
('age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6')機械学習を繰り返し平均スコアを計算
次に今回も機械学習を繰り返し、平均スコアを計算するようにプログラミングしていきますが、まずは特徴量を変数に格納してきます。
ちなみに先ほど確認のために書いた「print(comb)」はコメントアウトして、スキップするようにしておきます。
<セル2 取得した特徴量を変数に格納>
import itertools
trial=10
for i in range(1, len(diabetes.feature_names)+1):
for comb in itertools.combinations(diabetes.feature_names, i):
# print(comb)
x = df.loc[:, comb]
y = df.loc[:, "target"]
print(x)
実行結果
age
0 0.038076
1 -0.001882
2 0.085299
3 -0.089063
4 0.005383
.. ...
(中略)
.. ... ... ...
437 -0.002592 0.031193 0.007207
438 0.034309 -0.018118 0.044485
439 -0.011080 -0.046879 0.015491
440 0.026560 0.044528 -0.025930
441 -0.039493 -0.004220 0.003064
[442 rows x 10 columns]それぞれの特徴量の数値が表示され、データとして変数xに格納できていることが分かります。
次にこの変数を用い、モデルとしてはとりあえずSVRモデルを使い、10回機械学習して、平均スコアを表示していきます。
<セル2 機械学習10回+平均スコア計算>
import itertools
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.metrics import r2_score
import numpy as np
trial=10
for i in range(1, len(diabetes.feature_names)+1):
for comb in itertools.combinations(diabetes.feature_names, i):
# print(comb)
x = df.loc[:, comb]
y = df.loc[:, "target"]
# print(x)
pred_svr_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_svr = SVR()
model_svr.fit(x_train, y_train)
pred_svr = model_svr.predict(x_test)
pred_svr_score.append(r2_score(y_test, pred_svr))
pred_svr_ave = np.average(np.array(pred_svr_score))
print(pred_svr_ave)
実行結果
-0.04928513811208128
-0.03202763504085264
0.20038469207688164
0.13796238147827838
-0.0020896705133742976
(中略)
0.15029593943238842
0.14223615545096674
0.16069298185961026
0.17150387867791533
0.14389533537797297平均スコアTOP10を取得し、表示
全てのスコアを計算できるようになりましたが、流石にこれではどれが良い組み合わせなのか分かりません。
ということで予想精度の平均スコアTOP10を表示するプログラムにしていきましょう。
import itertools
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.metrics import r2_score
import numpy as np
trial=10
score_list = []; combination_list = []
for i in range(1, len(diabetes.feature_names)+1):
for comb in itertools.combinations(diabetes.feature_names, i):
# print(comb)
x = df.loc[:, comb]
y = df.loc[:, "target"]
# print(x)
pred_svr_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_svr = SVR()
model_svr.fit(x_train, y_train)
pred_svr = model_svr.predict(x_test)
pred_svr_score.append(r2_score(y_test, pred_svr))
pred_svr_ave = np.average(np.array(pred_svr_score))
# print(pred_svr_ave)
if len(score_list) < 10:
score_list.append(pred_svr_ave)
combination_list.append(comb)
elif len(score_list) == 10:
if np.min(score_list) < pred_svr_ave:
del combination_list[np.argmin(score_list)]
del score_list[np.argmin(score_list)]
combination_list.append(comb)
score_list.append(pred_svr_ave)
for comb, score in zip(combination_list, score_list):
print(comb, score)
実行結果
('s5',) 0.23140285357141993
('bmi', 's5') 0.2896731975272274
('bmi', 's1', 's5') 0.2406131795271133
('bmi', 's4', 's5') 0.23512841864486056
('age', 'bmi', 'bp', 's5') 0.23596581025636082
('sex', 'bmi', 'bp', 's5') 0.23416438539308754
('bmi', 'bp', 's4', 's5') 0.2437739731271556
('bmi', 'bp', 's5', 's6') 0.23101116937836172
('sex', 'bmi', 'bp', 's4', 's5') 0.2298175271034379
('bmi', 'bp', 's2', 's4', 's5') 0.23557026474426546追加されたのはこの部分。
score_list = []; combination_list = [] if len(score_list) < 10:
score_list.append(pred_svr_ave)
combination_list.append(comb)
elif len(score_list) == 10:
if np.min(score_list) < pred_svr_ave:
del combination_list[np.argmin(score_list)]
del score_list[np.argmin(score_list)]
combination_list.append(comb)
score_list.append(pred_svr_ave)
for comb, score in zip(combination_list, score_list):
print(comb, score)最初の「score_list = []; combination_list = []」は最終的に表示するスコアとその組み合わせを格納するためのリストです。
そして「if len(score_list) < 10:」でリストに含まれる要素数が10未満の時は、「score_list.append(pred_svr_ave)」で平均スコアを「score_list」に格納し、さらに「combination_list.append(comb)」でそのときの組み合わせを「combination_list」に格納します。
次に「elif len(score_list) == 10:」で「score_list」に含まれる要素数が10個になった場合、「if np.min(score_list) < pred_svr_ave:」で今回の平均スコアが「score_list」に含まれる10個の平均スコアのうち、最小値よりも大きい場合を場合分けします。
もし今回の平均スコアが「score_list」に含まれる10個の平均スコアのうち、最小値よりも大きい場合、del combination_list[np.argmin(score_list)]とdel score_list[np.argmin(score_list)]で最小値の組み合わせとその平均スコアを削除。
さらにその時の組み合わせと平均スコアをそれぞれ「combination_list」と「score_list」に格納します。
全ての組み合わせに関して、計算と評価が終わったら、こちらのプログラムで一つずつ表示します。
for comb, score in zip(combination_list, score_list):
print(comb, score)ちなみに時間がかかることを想定し、下の部位にprint(i)を入れておくと、どこまで処理が終わっているのか分かりやすいです。
<変更前>
for i in range(1, len(diabetes.feature_names)+1):
for comb in itertools.combinations(diabetes.feature_names, i):<変更後>
for i in range(1, len(diabetes.feature_names)+1):
print(i)
for comb in itertools.combinations(diabetes.feature_names, i):ということで最終的なプログラムはこんな感じ。
<セル2 完成版>
import itertools
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.metrics import r2_score
import numpy as np
trial=10
score_list = []; combination_list = []
for i in range(1, len(diabetes.feature_names)+1):
print(i)
for comb in itertools.combinations(diabetes.feature_names, i):
# print(comb)
x = df.loc[:, comb]
y = df.loc[:, "target"]
# print(x)
pred_svr_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_svr = SVR()
model_svr.fit(x_train, y_train)
pred_svr = model_svr.predict(x_test)
pred_svr_score.append(r2_score(y_test, pred_svr))
pred_svr_ave = np.average(np.array(pred_svr_score))
# print(pred_svr_ave)
if len(score_list) < 10:
score_list.append(pred_svr_ave)
combination_list.append(comb)
elif len(score_list) == 10:
if np.min(score_list) < pred_svr_ave:
del combination_list[np.argmin(score_list)]
del score_list[np.argmin(score_list)]
combination_list.append(comb)
score_list.append(pred_svr_ave)
for comb, score in zip(combination_list, score_list):
print(comb, score)
実行結果
1
2
3
4
5
6
7
8
9
10
('s5',) 0.2324347008540927
('bmi', 's5') 0.25211732190510483
('bmi', 'bp', 's5') 0.2590815528704341
('bmi', 's2', 's5') 0.24376496089529925
('bmi', 'bp', 's2', 's5') 0.24234159140148792
('bmi', 'bp', 's3', 's5') 0.2270951116349605
('bmi', 'bp', 's4', 's5') 0.22518801559600696
('bmi', 's4', 's5', 's6') 0.2313280622825627
('bmi', 'bp', 's3', 's4', 's5') 0.24303507844402308
('bmi', 'bp', 's2', 's3', 's4', 's5') 0.22608041336148746これで待っている間もちゃんとプログラムが動いていることを確認できて幸せになりました。
今回はプログラム作成だけでかなり長くなってしまったので、このプログラムを使っての検討は次回にしたいと思います。
ということで今回はこんな感じで。
コメント