機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnの糖尿病患者のデータセットを使い、SVRモデルのkernelのうち、sigmoidのオプションを色々と試してみました。
今回は最後の一つ、”poly”のオプションを色々といじってみることにしましょう。
ということでまずはデータの読み込みから。
<セル1>
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df["target"] = diabetes.target
df
実行結果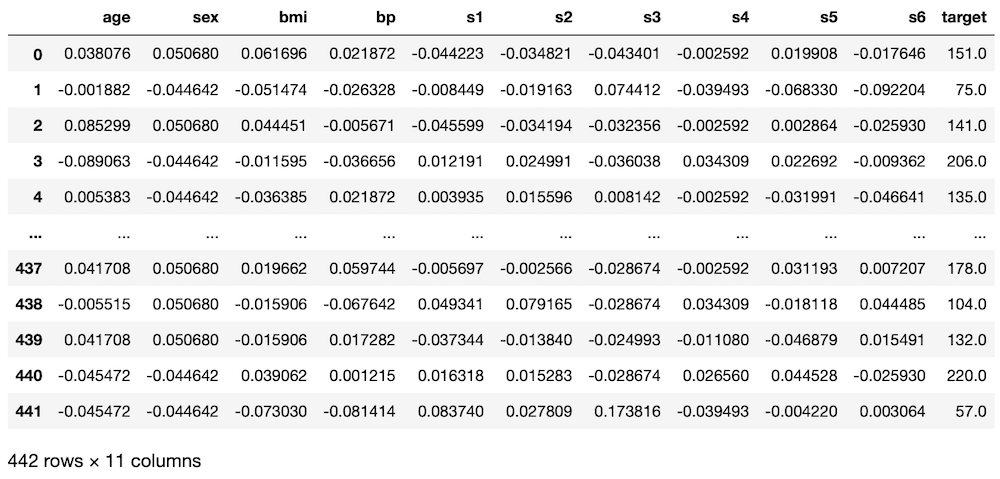
次に機械学習に用いる特徴量とターゲットをそれぞれ変数xとyに格納します。
(後で気付いたのですが、前の記事では「s6」も関連性がありそうということでしたが、忘れてしまいました。他の記事でも上記の組み合わせで行っているものもありますが、忘れたんだなぁと思って読んでください。)
<セル2>
x = df.loc[:, ["bmi", "s5", "bp", "s4", "s3"]]
y = df.loc[:, "target"]
実行結果次にSVRモデル読み込み、機械学習と予想を100回試した後、その予想精度のスコアの平均値を表示します。
この際、SVRのkernelをpolyに指定します。
<セル3>
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.metrics import r2_score
import numpy as np
trial = 100
pred_svr_score = []; pred_svr_train_score = []
for i in range(trial):
x_train_ori, x_test_ori, y_train_ori, y_test_ori = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_svr = SVR(kernel="poly")
model_svr.fit(x_train_ori, y_train_ori)
pred_svr_ori = model_svr.predict(x_test_ori)
pred_svr_score.append(r2_score(y_test_ori, pred_svr_ori))
pred_svr_ori_train = model_svr.predict(x_train_ori)
pred_svr_train_score.append(r2_score(y_train_ori, pred_svr_ori_train))
pred_svr_ave = np.average(np.array(pred_svr_score))
pred_svr_train_ave = np.average(np.array(pred_svr_train_score))
print(pred_svr_ave, pred_svr_train_ave)
実行結果
0.3150519677644141 0.35463008372751886今回、SVRのkernelをpolyとしてみましたが、予想精度のスコアとしては「0.31505」ということでこれまでと比べると特段良くも悪くもない数値となりました。
これが今回の基準となります。
あとはグラフの表示もしてみましょう。
<セル4>
from matplotlib import pyplot as plt
fig=plt.figure(figsize=(8,6))
plt.clf()
plt.scatter(y_test_ori, pred_svr_ori)
実行結果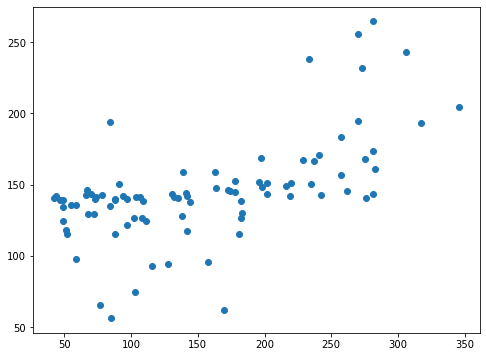
X軸方向に正解値、Y軸方向に予測値をプロットしていますので、右肩上がりのグラフになれば正解値と予想値が近いということになります。
ここからkernel=”poly”に関するオプションを見ていきましょう。
解説ページからすると「degree」、「gamma」、「coef0」が関係するようですが、「degree」以外は前回、前々回に解説しています。

ということで今回は「degree」を試していきましょう。
degree
degree: kernelがpolyの時にのみ使える多項式カーネル関数の次数。
int値(整数)、デフォルト値は3
前の記事でもちょっと解説したのですが、SVRはサポートベクター回帰というように、SVM(サポートベクターマシン)のように、グラフ上に線を引いて、その線をもとに回帰を行うのだと考えられます。
linearだと直線回帰だったのが、polyだとその線の次数を好きなように選べるのではないでしょうか。
ということでまずはdegree=1から試してみましょう。
<セル5 degree=1>
trial = 100
pred_svr_score = []; pred_svr_train_score = []
for i in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_svr = SVR(kernel="poly", degree=1)
model_svr.fit(x_train, y_train)
pred_svr = model_svr.predict(x_test)
pred_svr_score.append(r2_score(y_test, pred_svr))
pred_svr_train = model_svr.predict(x_train)
pred_svr_train_score.append(r2_score(y_train, pred_svr_train))
pred_svr_ave = np.average(np.array(pred_svr_score))
pred_svr_train_ave = np.average(np.array(pred_svr_train_score))
print(pred_svr_ave, pred_svr_train_ave)
実行結果
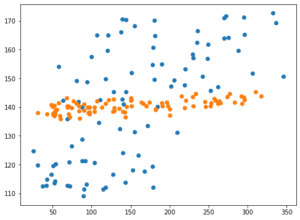
0.4243964666531823 0.4404141492787258スコアが一気に良くなりました。
ただdegreeが次数の指定だとすると、1にしたら1次式、つまりはlinearと変わらないんじゃないかと思っていました。
しかし前に試した通り、kernel=”linear”とするとスコアが「-0.01675」とものすごく悪くなってしまいました。
それと比べると今回のkernel=”poly”, degree=1では「0.42440」と断然良いスコアとなっています。
そう考えると単純に次数を変えられるというのは違うのかもしれません。
とりあえずグラフを表示してみましょう。
<セル6 degree=1>
fig=plt.figure(figsize=(8,6))
plt.clf()
plt.scatter(y_test_ori, pred_svr_ori)
plt.scatter(y_test, pred_svr)
実行結果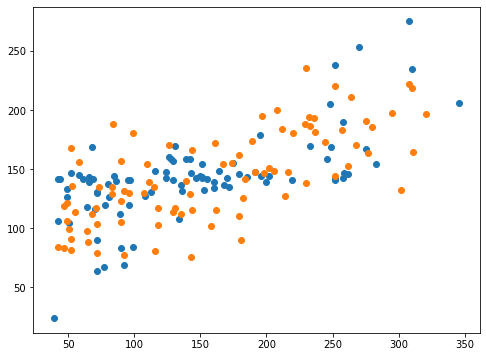
思ったよりも改善したという感じはしません。
次にデフォルトは3なので、もっと多い数値として10を試してみましょう。
<セル5 degree=10>
trial = 100
pred_svr_score = []; pred_svr_train_score = []
for i in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_svr = SVR(kernel="poly", degree=10)
model_svr.fit(x_train, y_train)
pred_svr = model_svr.predict(x_test)
pred_svr_score.append(r2_score(y_test, pred_svr))
pred_svr_train = model_svr.predict(x_train)
pred_svr_train_score.append(r2_score(y_train, pred_svr_train))
pred_svr_ave = np.average(np.array(pred_svr_score))
pred_svr_train_ave = np.average(np.array(pred_svr_train_score))
print(pred_svr_ave, pred_svr_train_ave)
実行結果
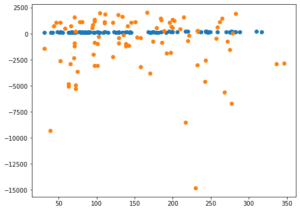
-11.088466758666124 0.2881840633733465今度はかなり悪い数値となってしまいました。
グラフも見てみましょう。
<セル6 degree=10>
fig=plt.figure(figsize=(8,6))
plt.clf()
plt.scatter(y_test_ori, pred_svr_ori)
plt.scatter(y_test, pred_svr)
実行結果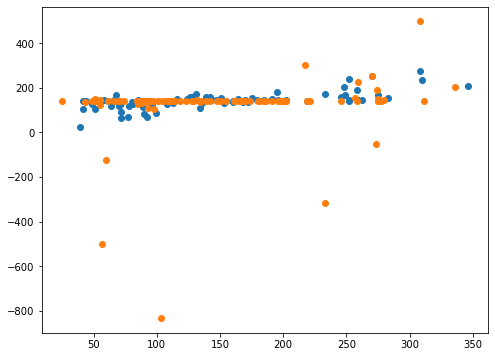
所々にものすごくずれた値が出てきてしまっています。
それ以外のところはdegreeの指定なしと比べて一点に集まっているように見えます。
ということは縛りが強すぎて一点に集まるようになったが、所々計算が上手くいかず大きく外れた値を予想してしまうという感じが見受けられます。
もう一つくらい試してみましょう。
先ほどdegree=1でスコアが良くなったので、degree=2としてみたらどうなるでしょうか。
<セル5 degree=2>
trial = 100
pred_svr_score = []; pred_svr_train_score = []
for i in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_svr = SVR(kernel="poly", degree=2)
model_svr.fit(x_train, y_train)
pred_svr = model_svr.predict(x_test)
pred_svr_score.append(r2_score(y_test, pred_svr))
pred_svr_train = model_svr.predict(x_train)
pred_svr_train_score.append(r2_score(y_train, pred_svr_train))
pred_svr_ave = np.average(np.array(pred_svr_score))
pred_svr_train_ave = np.average(np.array(pred_svr_train_score))
print(pred_svr_ave, pred_svr_train_ave)
実行結果
-0.012933961635605831 0.027487037478286035こちらもかなり悪いスコアとなってしまいました。
degree=1では「0.42440」、デフォルトのdegree=3(degree指定なし)では「0.31505」なのでその間くらいになるのかと思っていたのですが、そうはいきませんでした。
これだけ大きくスコアが変化するということは、データによって色々と変えてみる価値のあるオプションなんだと思います。
ちなみにdegree=2のグラフも表示させてみましょう。
<セル6 degree=2>
fig=plt.figure(figsize=(8,6))
plt.clf()
plt.scatter(y_test_ori, pred_svr_ori)
plt.scatter(y_test, pred_svr)
実行結果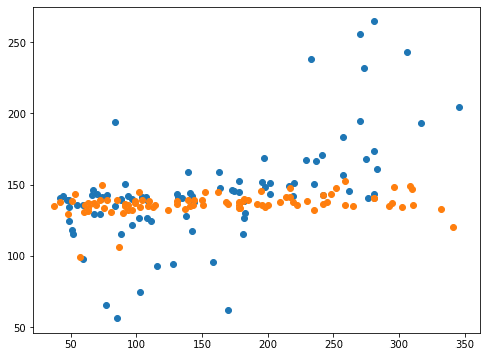
スコアから受ける印象よりは全然マシなグラフになったと感じていますが、いかがでしょうか。
予想値としては全体的に一点に固まりかけているようで、それがスコアを落とす要因になったと考えられます。
これまでもそうですが、オプション一つでこれだけ結果が変わる機械学習はなかなかいじりがいがあるものだなぁと思います。
オプションではなかなか良い予想精度スコアに巡り会えなかったため、次回はこの糖尿病のデータセットではどの特徴量を使えばいいか、再度考えてみたいと思います。
ということで今回はこんな感じで。
コメント