機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnの糖尿病患者のデータセットでRidgeRegressionモデルを使い、特徴量の全ての組み合わせを検討してみました。

そこで分かったのは、やはり機械学習のモデルによって、予想精度のスコアが高い特徴量の組み合わせは違うということ。
であるならば複数の機械学習モデルに対して、特徴量の全ての組み合わせを検討するプログラムがあれば、モデル選択が自動できるんじゃないかと考えました。
ということで今回は特定の機械学習モデルに対し、特徴量全ての組み合わせを検討するプログラムを改変していこうと思います。
ということでまずはデータの読み込みから。
<セル1>
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df["target"] = diabetes.target
df
実行結果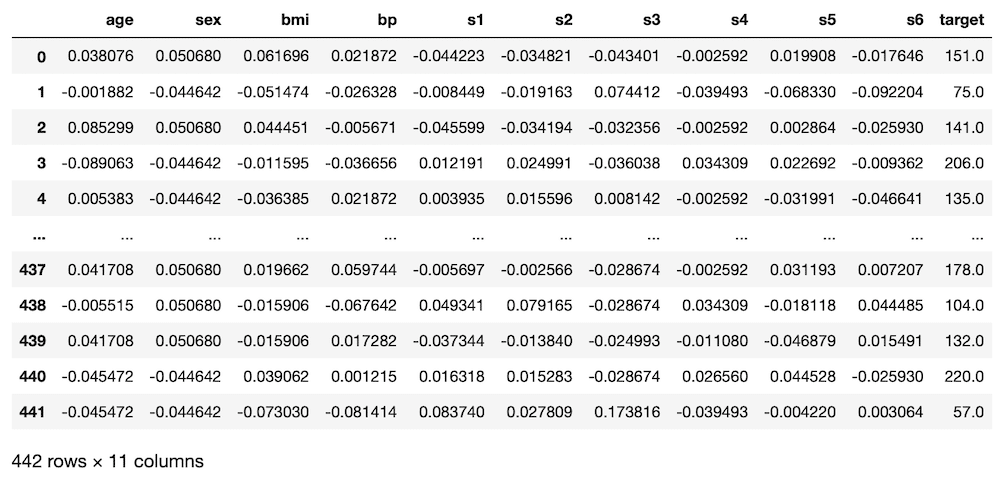
プログラムとしては、前回使用したRidgeRegressionモデルに対して特徴量全てを試すプログラムを改変していくので、まずは紹介しておきます。
<セル2>
import itertools
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from sklearn.metrics import r2_score
import numpy as np
trial=10
score_list = []; combination_list = []
for i in range(1, len(diabetes.feature_names)+1):
print(i)
for comb in itertools.combinations(diabetes.feature_names, i):
# print(comb)
x = df.loc[:, comb]
y = df.loc[:, "target"]
# print(x)
pred_rd_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_rd = Ridge()
model_rd.fit(x_train, y_train)
pred_rd = model_rd.predict(x_test)
pred_rd_score.append(r2_score(y_test, pred_rd))
pred_rd_ave = np.average(np.array(pred_rd_score))
# print(pred_rd_ave)
if len(score_list) < 10:
score_list.append(pred_rd_ave)
combination_list.append(comb)
elif len(score_list) == 10:
if np.min(score_list) < pred_rd_ave:
del combination_list[np.argmin(score_list)]
del score_list[np.argmin(score_list)]
combination_list.append(comb)
score_list.append(pred_rd_ave)
for comb, score in zip(combination_list, score_list):
print(comb, score)インポート部
まず最初に改変する点はインポートの部分です。
試したい分のモデルをインポートしておく必要があります。
ということで、変更前のインポート部。
import itertools
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from sklearn.metrics import r2_score
import numpy as npこれを「LinearRegression」、「Lasso」、「ElasticNet」、「RidgeRegression」、「SVR」を使えるようにライブラリをインポートします。
import itertools
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import Ridge
from sklearn.svm import SVR
from sklearn.metrics import r2_score
import numpy as npモデル選択・機械学習部
次にモデルを順番に試していく部分を追加していきます。
この部分の流れとしては、こんな感じです。
- 機械学習モデル名のリストから一つ選択する
- 選択されたモデル名のモデルを読み込む
- 読み込まれたモデルで複数回機械学習を行う
この後、計算・表示などがありますが、その部分の流れはまた後ほど。
ということで、改変していきましょう。
まずライブラリのインポートの下に、「機械学習モデル名のリスト」を追加します。
models = ["LinearRegression", "Lasso", "ElasticNet", "RidgeRegression", "SVR"]次に機械学習モデルの読み込み部分を改変していきます。
そこでこちらの部分のインテンドを一つ増やします。
pred_rd_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_rd = Ridge()
model_rd.fit(x_train, y_train)
pred_rd = model_rd.predict(x_test)
pred_rd_score.append(r2_score(y_test, pred_rd))
pred_rd_ave = np.average(np.array(pred_rd_score))
# print(pred_rd_ave)
if len(score_list) < 10:
score_list.append(pred_rd_ave)
combination_list.append(comb)
elif len(score_list) == 10:
if np.min(score_list) < pred_rd_ave:
del combination_list[np.argmin(score_list)]
del score_list[np.argmin(score_list)]
combination_list.append(comb)
score_list.append(pred_rd_ave)そして最初に機械学習モデル名を一つずつ取得するためfor文を追加します。
for mod in models:
pred_rd_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_rd = Ridge()
(以下略)次に取得した機械学習モデル名に合わせて、モデルを読み込みます。
この部分はif文で場合分けしていきます。
ということでこの部分が
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
model_rd = Ridge()こうなります。
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
if mod == "LinearRegression":
model = LinearRegression()
elif mod == "Lasso":
model = Lasso()
elif mod == "ElasticNet":
model = ElasticNet()
elif mod == "RidgeRegression":
model = Ridge()
elif mod == "SVR":
model = SVR()そしてRidgeRegressionモデルのため「model_rd」とか「pred_rd」というように”_rd”とつけていたのですが、これを削除して一般化しておきましょう。
ということでモデルの読み込み、機械学習の部分はこんな感じになります。
for mod in models:
pred_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
if mod == "LinearRegression":
model = LinearRegression()
elif mod == "Lasso":
model = Lasso()
elif mod == "ElasticNet":
model = ElasticNet()
elif mod == "RidgeRegression":
model = Ridge()
elif mod == "SVR":
model = SVR()
model.fit(x_train, y_train)
pred = model.predict(x_test)
pred_score.append(r2_score(y_test, pred))
pred_ave = np.average(np.array(pred_score))TOP100をリストとして格納する
次にこれまではTOP10をリストに格納し、表示させていましたが、今度は検討するモデル、特徴量の組み合わせが増えていきますので、TOP100までリストに格納するように変更します。
またその際、モデル名も格納するように変更しましょう。
ということで、元々はこうでした。
if len(score_list) < 10:
score_list.append(pred_ave)
combination_list.append(comb)
elif len(score_list) == 10:
if np.min(score_list) < pred_ave:
del combination_list[np.argmin(score_list)]
del score_list[np.argmin(score_list)]
combination_list.append(comb)
score_list.append(pred_ave)こうなります。
if len(score_list) < 100:
score_list.append(pred_ave)
combination_list.append(comb)
model_list.append(mod)
elif len(score_list) == 100:
if np.min(score_list) < pred_ave:
del combination_list[np.argmin(score_list)]
del model_list[np.argmin(score_list)]
del score_list[np.argmin(score_list)]
combination_list.append(comb)
score_list.append(pred_ave)
model_list.append(mod)if文で使っている数字が10から100に変わったことで、TOP100までを格納するようになります。
またモデル名を格納するのに「model_list.append(mod)」をif内部とelif内部に追加してあります。
そして格納されたデータが100となった時に、次格納するために一番低い値のものを削除します。
そこで「del model_list[np.argmin(score_list)]」が追加されています。
結果表示部
最後に結果を表示する部分を改変していきます。
これまでは単純に組み合わせを格納したリストとスコアを格納したリストを一つずつ表示させていました。
for comb, score in zip(combination_list, score_list):
print(comb, score)ただこれは結果を10個しか格納してなかったのでできたこと。
今回は100個の結果を格納しているため、流石に一つ一つ目で見てどれが一番スコアが確認するなんてことはできません。
ということで得られた結果はPandasのデータフレームに格納して、表示する形式に変更しましょう。
results = pd.DataFrame()
results["Model_name"] = model_list
results["Combination"] = combination_list
results["Score"] = score_list
results = results.sort_values("Score", ascending=False)
results最初の「results = pd.DataFrame()」で空のデータフレームを作成します。
次に「results[“Model_name”] = model_list」でモデル名を格納、「results[“Combination”] = combination_list」で組み合わせを格納、「results[“Score”] = score_list」でスコアを格納します。
そして「results = results.sort_values(“Score”, ascending=False)」でスコアを降順にソートします。
最後に「results」で結果を表示します。
完成したプログラム全体
完成したプログラム全体はこんな感じです。
trial数はとりあえずチェックのため1にしてあります。
import itertools
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import Ridge
from sklearn.svm import SVR
from sklearn.metrics import r2_score
import numpy as np
models = ["LinearRegression", "Lasso", "ElasticNet", "RidgeRegression", "SVR"]
trial=1
score_list = []; combination_list = []; model_list = []
for i in range(1, len(diabetes.feature_names)+1):
print(i)
for comb in itertools.combinations(diabetes.feature_names, i):
# print(comb)
x = df.loc[:, comb]
y = df.loc[:, "target"]
# print(x)
for mod in models:
pred_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
if mod == "LinearRegression":
model = LinearRegression()
elif mod == "Lasso":
model = Lasso()
elif mod == "ElasticNet":
model = ElasticNet()
elif mod == "RidgeRegression":
model = Ridge()
elif mod == "SVR":
model = SVR()
model.fit(x_train, y_train)
pred = model.predict(x_test)
pred_score.append(r2_score(y_test, pred))
# print(mod, r2_score(y_test, pred))
pred_ave = np.average(np.array(pred_score))
# print(pred_ave)
if len(score_list) < 100:
score_list.append(pred_ave)
combination_list.append(comb)
model_list.append(mod)
elif len(score_list) == 100:
if np.min(score_list) < pred_ave:
del combination_list[np.argmin(score_list)]
del model_list[np.argmin(score_list)]
del score_list[np.argmin(score_list)]
combination_list.append(comb)
score_list.append(pred_ave)
model_list.append(mod)
results = pd.DataFrame()
results["Model_name"] = model_list
results["Combination"] = combination_list
results["Score"] = score_list
results = results.sort_values("Score", ascending=False)
results
実行結果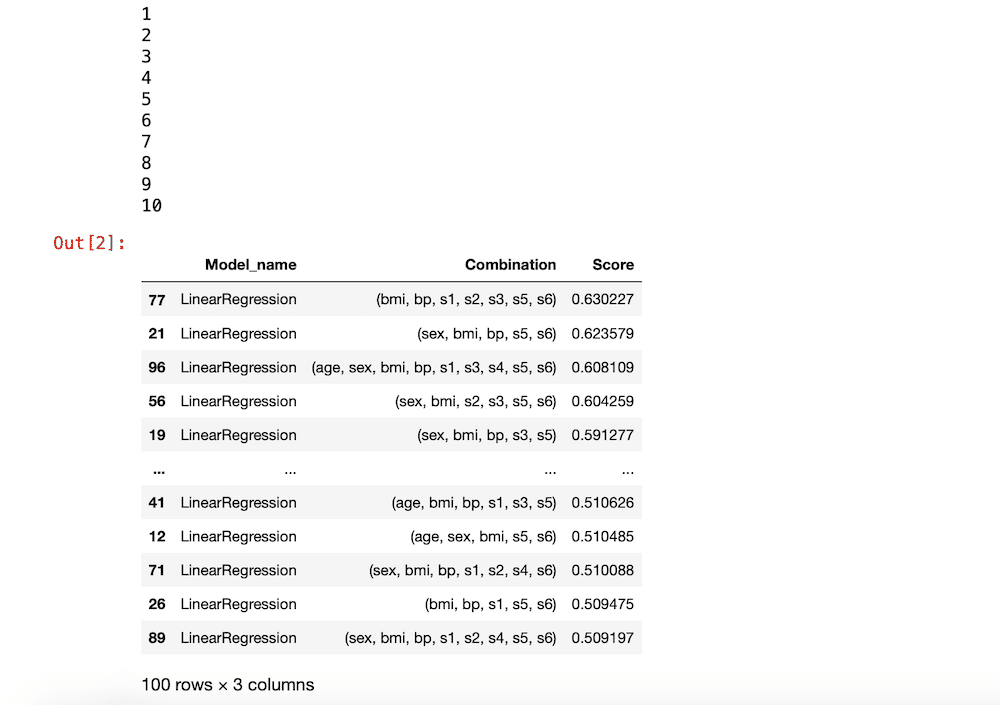
ちゃんと動きました。
ちなみに今回のプログラムの利点としては、全ての機械学習モデルに対して、同じ学習データで学習し、同じテストデータで予測しているという点です。
今回は改変だけで結構長くなってしまいましたので、検討はまた次回に回したいと思います。
ということで今回はこんな感じで。
コメント