機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnで複数の機械学習モデルで特徴量全ての組み合わせを試すためのプログラムを検討してみました。
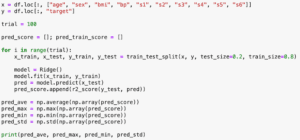
その結果分かったことは、単純に予想精度の平均スコアだけで比較すると、どうやらLinearRegressionばかり上位に入ってくること。
そしてLinearRegressionではその時々によって予想精度のばらつきが大きく、たまたま予想精度が良いものばかりになった時、スコアランキングの上位に入ってくること。
つまりLinearRegressionだけに有利なプログラムになっているようでした。
今回は予想精度のばらつきに注目して、新しいスコアを作り、それで比較するということをしてみたいと思います。
ということでいつも通りまずはデータの読み込みから。
<セル1>
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df["target"] = diabetes.target
df
実行結果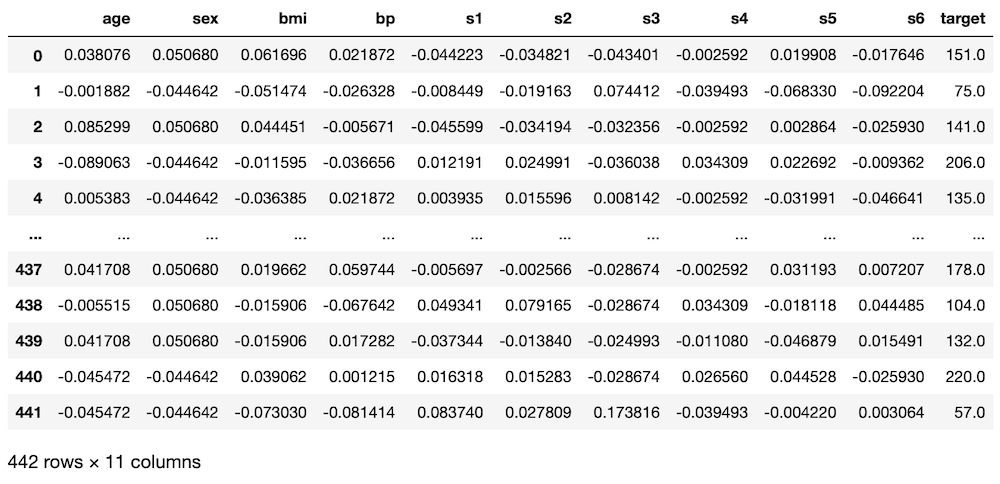
前回の複数の機械学習モデルに対し、特徴量の全ての組み合わせを試すプログラムはこんな感じ。
<セル2>
import itertools
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import Ridge
from sklearn.svm import SVR
from sklearn.metrics import r2_score
import numpy as np
models = ["LinearRegression", "Lasso", "ElasticNet", "RidgeRegression", "SVR"]
trial=10
score_list = []; combination_list = []; model_list = []
for i in range(1, len(diabetes.feature_names)+1):
print(i)
for comb in itertools.combinations(diabetes.feature_names, i):
# print(comb)
x = df.loc[:, comb]
y = df.loc[:, "target"]
# print(x)
for mod in models:
pred_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
if mod == "LinearRegression":
model = LinearRegression()
elif mod == "Lasso":
model = Lasso()
elif mod == "ElasticNet":
model = ElasticNet()
elif mod == "RidgeRegression":
model = Ridge()
elif mod == "SVR":
model = SVR()
model.fit(x_train, y_train)
pred = model.predict(x_test)
pred_score.append(r2_score(y_test, pred))
# print(mod, r2_score(y_test, pred))
pred_ave = np.average(np.array(pred_score))
# print(pred_ave)
if len(score_list) < 100:
score_list.append(pred_ave)
combination_list.append(comb)
model_list.append(mod)
elif len(score_list) == 100:
if np.min(score_list) < pred_ave:
del combination_list[np.argmin(score_list)]
del score_list[np.argmin(score_list)]
del model_list[np.argmin(score_list)]
combination_list.append(comb)
score_list.append(pred_ave)
model_list.append(mod)
results = pd.DataFrame()
results["Model_name"] = model_list
results["Combination"] = combination_list
results["Score"] = score_list
results = results.sort_values("Score", ascending=False)
results.head(10)
実行結果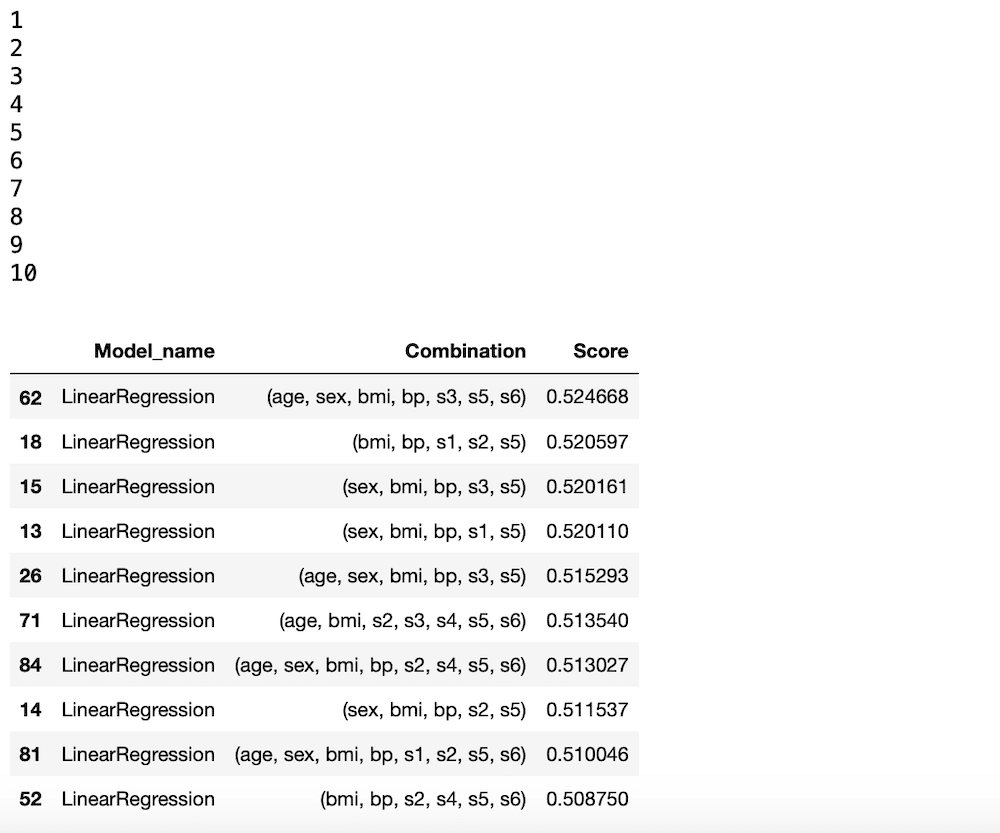
ということでこれをもとに改変していきましょう。
最大値、最小値、標準偏差、スコア/標準偏差を追加
今回は最大値、最小値、標準偏差、そして新しい評価としてスコア/標準偏差を追加します。
そのためそれらを格納するための空のリストを作ります。
ということで、この部分が、
trial=10
score_list = []; combination_list = []; model_list = []
for i in range(1, len(diabetes.feature_names)+1):
print(i)こうなります。
trial=10
score_list = []; combination_list = []; model_list = []
std_list = []; max_list = []; min_list = []; score_std_list = []
for i in range(1, len(diabetes.feature_names)+1):
print(i)そして今までは機械学習をしてスコアを取得、そのスコアを変数pred_aveに格納していました。
model.fit(x_train, y_train)
pred = model.predict(x_test)
pred_score.append(r2_score(y_test, pred))
# print(mod, r2_score(y_test, pred))
pred_ave = np.average(np.array(pred_score))しかし前回、表示をリストを順々に表示するシステムからPandasでスコアの降順にソートする方法に変えました。
そのため、よく考えたら取得するデータ数を100個に制限かけなくても、後でPandasで好きなようにデータをいじれることができます。
ということで、とりあえず全てのデータをリストに入れて、後でPandasのデータフレームに格納する方式に変更します。
つまりこの部分が
model.fit(x_train, y_train)
pred = model.predict(x_test)
pred_score.append(r2_score(y_test, pred))
# print(mod, r2_score(y_test, pred))
pred_ave = np.average(np.array(pred_score))
# print(pred_ave)
if len(score_list) < 100:
score_list.append(pred_ave)
combination_list.append(comb)
model_list.append(mod)
elif len(score_list) == 100:
if np.min(score_list) < pred_ave:
del combination_list[np.argmin(score_list)]
del score_list[np.argmin(score_list)]
del model_list[np.argmin(score_list)]
combination_list.append(comb)
score_list.append(pred_ave)
model_list.append(mod)これだけで十分ということです。
model.fit(x_train, y_train)
pred = model.predict(x_test)
pred_score.append(r2_score(y_test, pred))
# print(mod, r2_score(y_test, pred))
combination_list.append(comb)
score_list.append(np.average(np.array(pred_score)))
std_list.append(np.std(np.array(pred_score)))
max_list.append(np.max(np.array(pred_score)))
min_list.append(np.min(np.array(pred_score)))
model_list.append(mod)新しい評価はPandasに格納した後で計算する方が楽です。
ということでPandasのデータフレーム作成の部分を改変していきます。
results = pd.DataFrame()
results["Model_name"] = model_list
results["Combination"] = combination_list
results["Score"] = score_list
results = results.sort_values("Score", ascending=False)
results.head(10)空のデータフレームを作成した後、データを格納したリストを一つ一つデータフレームに格納していっています。
そして「.sort_values」を使って、スコアの降順にして、「.head」でTOP10を表示しています。
今回も追加していくデータの数は増えましたが、流れとしては同じです。
results = pd.DataFrame()
results["Model_name"] = model_list
results["Combination"] = combination_list
results["Score"] = score_list
results["Max"] = max_list
results["Min"] = min_list
results["STD"] = std_list
results["Score/STD"] = results["Score"]/results["STD"]
results = results.sort_values("Score/STD", ascending=False)
results.head(10)また新しい評価に関しては「results[“Score/STD”] = results[“Score”]/results[“STD”]」の行でスコアの列と標準偏差の列を直接割り算して、新しい評価の列「results[“Score/STD”]」として追加しています。
最後に「results.head(10)」でTOP10 を表示するというわけです。
改変したプログラム全体
これ改変したプログラム全体です。
<セル2>
import itertools
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import Ridge
from sklearn.svm import SVR
from sklearn.metrics import r2_score
import numpy as np
models = ["LinearRegression", "Lasso", "ElasticNet", "RidgeRegression", "SVR"]
trial=10
score_list = []; combination_list = []; model_list = []
std_list = []; max_list = []; min_list = []; score_std_list = []
for i in range(1, len(diabetes.feature_names)+1):
print(i)
for comb in itertools.combinations(diabetes.feature_names, i):
# print(comb)
x = df.loc[:, comb]
y = df.loc[:, "target"]
# print(x)
for mod in models:
pred_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
if mod == "LinearRegression":
model = LinearRegression()
elif mod == "Lasso":
model = Lasso()
elif mod == "ElasticNet":
model = ElasticNet()
elif mod == "RidgeRegression":
model = Ridge()
elif mod == "SVR":
model = SVR()
model.fit(x_train, y_train)
pred = model.predict(x_test)
pred_score.append(r2_score(y_test, pred))
# print(mod, r2_score(y_test, pred))
combination_list.append(comb)
score_list.append(np.average(np.array(pred_score)))
std_list.append(np.std(np.array(pred_score)))
max_list.append(np.max(np.array(pred_score)))
min_list.append(np.min(np.array(pred_score)))
model_list.append(mod)
results = pd.DataFrame()
results["Model_name"] = model_list
results["Combination"] = combination_list
results["Score"] = score_list
results["Max"] = max_list
results["Min"] = min_list
results["STD"] = std_list
results["Score/STD"] = results["Score"]/results["STD"]
results = results.sort_values("Score/STD", ascending=False)
results.head(10)
実行結果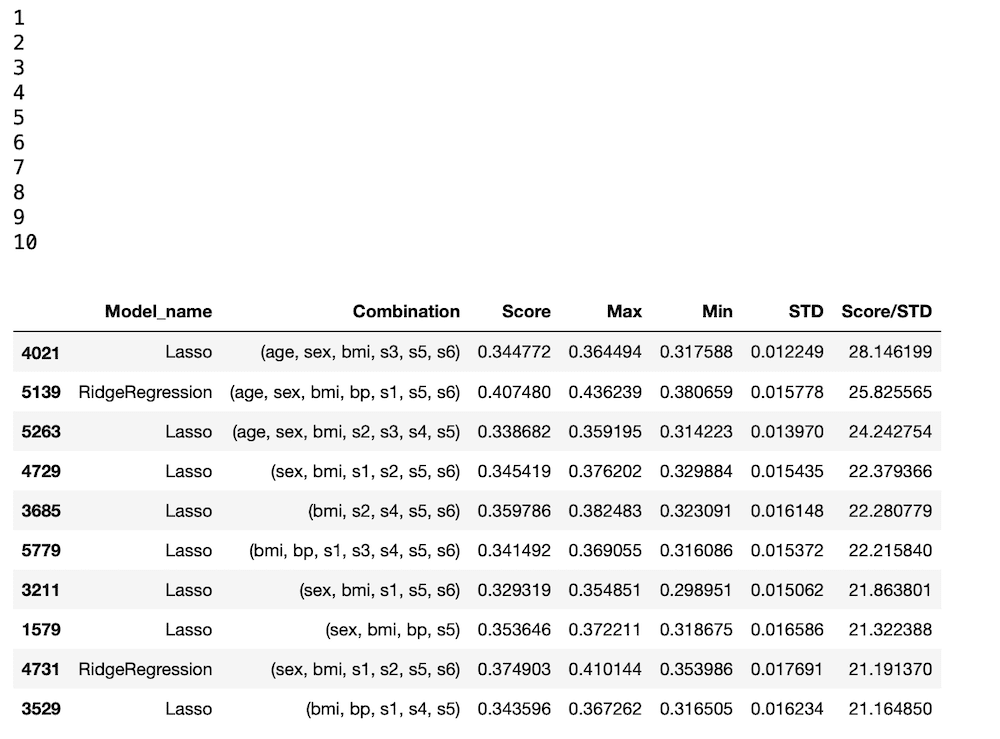
とりあえず1回実行してみた結果、今回のプログラムではTOP10はLassoモデルが多くなっています。
予想精度スコアを標準偏差で割った値を新しい評価としているので、ちょっと標準偏差の影響が強く出てしまった感じがあります。
プログラムの改変だけでなかなか長くなってしまいましたので、今回はここまでとします。
次回は分析としてそれぞれのモデルの個数をカウントし、円グラフとして表示するということをしてみようと思います。

ということで今回はこんな感じで。
コメント