機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnで複数の機械学習モデルで特徴量全ての組み合わせを試すためのプログラムを改変してみました。
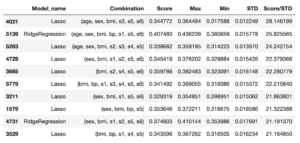
作ってみたところで気づいたのは、複数の機械学習モデルで特徴量の全ての組み合わせを試した時に、どのモデルが比率が高いのか、このままでは分からないということです。
つまりは分析しようにも、データが膨大すぎて、ぱっと見で感覚を掴めない。
ということでぱっと見てどの機械学習モデルが使われやすいのか、円グラフにしてみようというのが今回の目標です。
ただ円グラフにする時に、それぞれのモデルの個数をカウントするので、Pandasを使った特定のデータの個数の数え方も解説していきます。
ということでプログラムのおさらい。
こちらが機械学習用データ(糖尿病患者のデータ)の読み込み部分です。
<セル1>
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df["target"] = diabetes.target
df
実行結果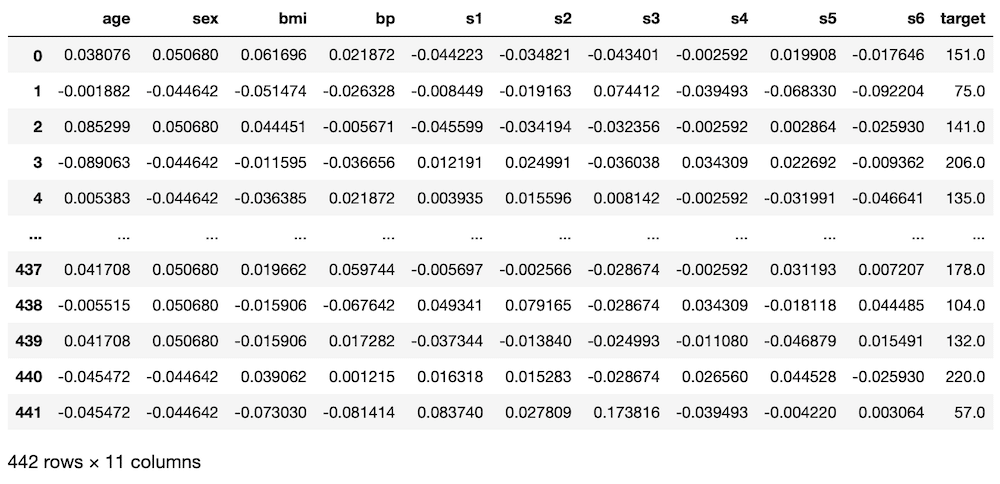
次に機械学習・評価部分です。
<セル2>
import itertools
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import Ridge
from sklearn.svm import SVR
from sklearn.metrics import r2_score
import numpy as np
models = ["LinearRegression", "Lasso", "ElasticNet", "RidgeRegression", "SVR"]
trial=10
score_list = []; combination_list = []; model_list = []
std_list = []; max_list = []; min_list = []; score_std_list = []
for i in range(1, len(diabetes.feature_names)+1):
print(i)
for comb in itertools.combinations(diabetes.feature_names, i):
# print(comb)
x = df.loc[:, comb]
y = df.loc[:, "target"]
# print(x)
for mod in models:
pred_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
if mod == "LinearRegression":
model = LinearRegression()
elif mod == "Lasso":
model = Lasso()
elif mod == "ElasticNet":
model = ElasticNet()
elif mod == "RidgeRegression":
model = Ridge()
elif mod == "SVR":
model = SVR()
model.fit(x_train, y_train)
pred = model.predict(x_test)
pred_score.append(r2_score(y_test, pred))
# print(mod, r2_score(y_test, pred))
combination_list.append(comb)
score_list.append(np.average(np.array(pred_score)))
std_list.append(np.std(np.array(pred_score)))
max_list.append(np.max(np.array(pred_score)))
min_list.append(np.min(np.array(pred_score)))
model_list.append(mod)
results = pd.DataFrame()
results["Model_name"] = model_list
results["Combination"] = combination_list
results["Score"] = score_list
results["Max"] = max_list
results["Min"] = min_list
results["STD"] = std_list
results["Score/STD"] = results["Score"]/results["STD"]
results = results.sort_values("Score/STD", ascending=False)
results.head(10)
実行結果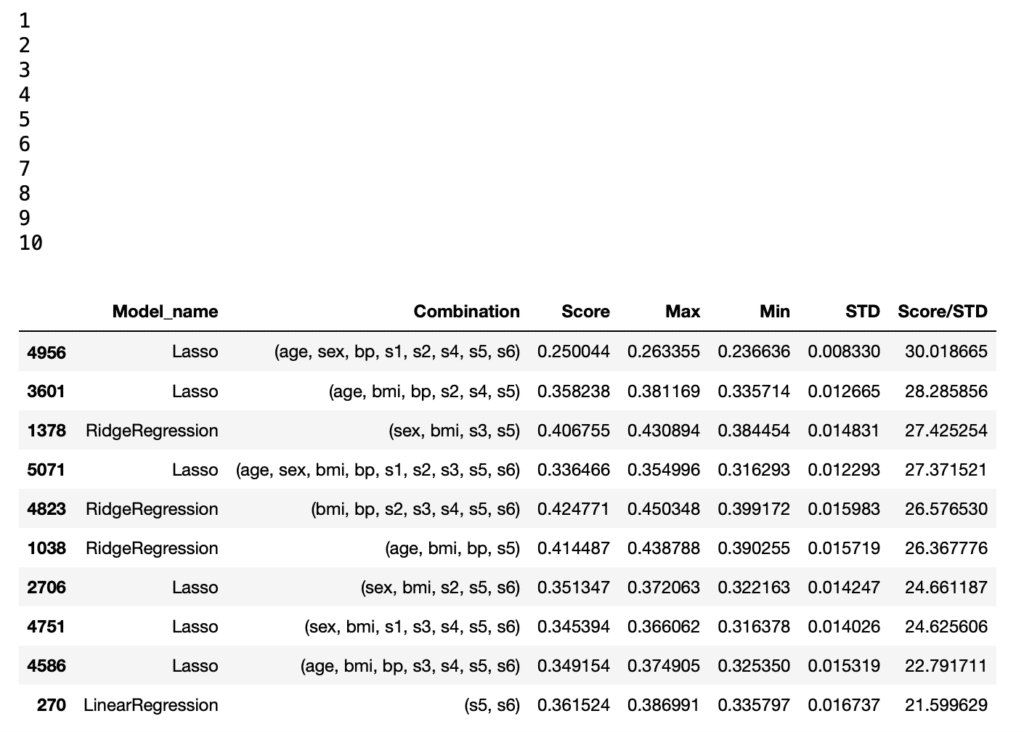
スコアの評価方法を「スコア/標準偏差」としたことで、LinearRegression以外の機械学習モデルも上位に入ってくるようになりました。
こうなってくると気になるのがどのモデルがよく使われているのかということ。
ということである特定の順位までの機械学習モデルの比率を計算し、円グラフにしてみましょう。
特定の順位までのそれぞれの機械学習モデルの出現回数を取得
まず行うのは、特定の順位までにそれぞれの機械学習モデルが何回現れるのか、その回数を取得してみましょう。
まずは特定の順位というものを定義します。
ranking = 100定義というと難しそうに聞こえますが、単純にrankingという変数に取得したい順位を格納します。
今回はとりあえず100位としてみました。
次に”LinearRegression”モデルの出現回数を取得します。
lr_count = results["Model_name"][:ranking][results["Model_name"] == "LinearRegression"].count()一つずつ解説すると、results[“Model_name”]で”Model_name”の列を指定します。
そして[:ranking]でその範囲を指定しています。
このとき「:」の前を指定していないため、前は一番前から、そして「:」の後ろに「ranking」としているため、変数rankingで指定した数までを抽出しているというわけです。
次に[results[“Model_name”] == “LinearRegression”]で、”Model_name”が”LinearRegression”と一致するものを抽出します。
最後の.count()でその個数を取得しています。
ということで他のモデルも同様にして個数を取得します。
ranking = 100
lr_count = results["Model_name"][:ranking][results["Model_name"] == "LinearRegression"].count()
lasso_count = results["Model_name"][:ranking][results["Model_name"] == "Lasso"].count()
en_count = results["Model_name"][:ranking][results["Model_name"] == "ElasticNet"].count()
rd_count = results["Model_name"][:ranking][results["Model_name"] == "RidgeRegression"].count()
svr_count = results["Model_name"][:ranking][results["Model_name"] == "SVR"].count()次に円グラフにするために、これらの取得した個数をリストに格納し、確認のためにprint関数で表示しておきます。
model_count_list = [lr_count, lasso_count, en_count, rd_count, svr_count]
print(model_count_list)ということで全体としてはこんな感じ。
<セル3>
ranking = 100
lr_count = results["Model_name"][:ranking][results["Model_name"] == "LinearRegression"].count()
lasso_count = results["Model_name"][:ranking][results["Model_name"] == "Lasso"].count()
en_count = results["Model_name"][:ranking][results["Model_name"] == "ElasticNet"].count()
rd_count = results["Model_name"][:ranking][results["Model_name"] == "RidgeRegression"].count()
svr_count = results["Model_name"][:ranking][results["Model_name"] == "SVR"].count()
model_count_list = [lr_count, lasso_count, en_count, rd_count, svr_count]
print(model_count_list)
実行結果
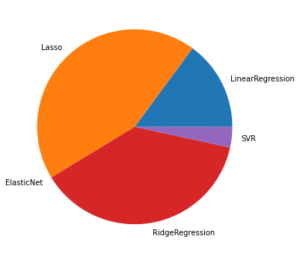
[5, 52, 0, 43, 0]これでそれぞれの機械学習モデルの出現回数を取得することができました。
円グラフを表示してみる。
次に先ほど取得した機械学習モデルの出現回数を円グラフにしてみましょう。
今回は短いコードなので、解説は後回しにします。
<セル4>
from matplotlib import pyplot as plt
%matplotlib inline
fig = plt.figure(figsize=(8,6))
plt.clf()
plt.pie(model_count_list, labels=models)
実行結果
([<matplotlib.patches.Wedge at 0x7fa651c7f650>,
<matplotlib.patches.Wedge at 0x7fa651c7f9d0>,
<matplotlib.patches.Wedge at 0x7fa651c8a050>,
<matplotlib.patches.Wedge at 0x7fa651c8a110>,
<matplotlib.patches.Wedge at 0x7fa651c8af10>],
[Text(0.772914956812565, 0.7826892547719247, 'LinearRegression'),
Text(-1.0302048843761413, 0.38558772828960897, 'Lasso'),
Text(-0.7326130369690883, -0.8205352753312494, 'ElasticNet'),
Text(0.3791072750466436, -1.032607221554599, 'RidgeRegression'),
Text(1.0973737641382457, -0.07596592513132563, 'SVR')])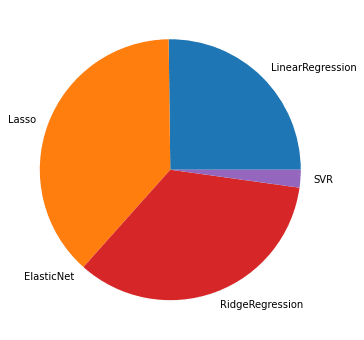
ということで解説。
from matplotlib import pyplot as plt
%matplotlib inline最初の2行はmatplotlibライブラリのインポートと、jupyter notebookでグラフが表示させるためのマジックコマンドです。
fig = plt.figure(figsize=(8,6))
plt.clf()次の2行はグラフを表示するための領域の準備と、前のグラフデータが残っていたりする時のために、その領域をまっさらにしています。
plt.pie(model_count_list, labels=models)円グラフを表示しているのは最後の1行だけです。
「plt.pie」で円グラフを指定し、その要素をリスト「model_count_list」として最初に記述。
そのラベルを「labels=models」として指定しています。
ちなみに「models」は<セル2>の最初の方にあるこちらのリスト名のことです。
models = ["LinearRegression", "Lasso", "ElasticNet", "RidgeRegression", "SVR"]これで特定の順位までの機械学習モデルの比率を取得し、円グラフとして表示することができました。
次回はとうとうこのプログラムを使って、解析を進めていきたいと思います。
ということで今回はこんな感じで。
コメント