機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnで複数の機械学習モデルで特徴量全ての組み合わせを試し、使われやすい機械学習モデルを円グラフで表示してみました。
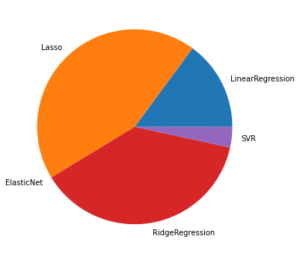
今回はそこからもう一歩進めて、使われやすいモデルのなかで、どの特徴量が使われやすいかをグラフ化していきたいと思います。
まずは前回のおさらいから。
<セル1>
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df["target"] = diabetes.target
df
実行結果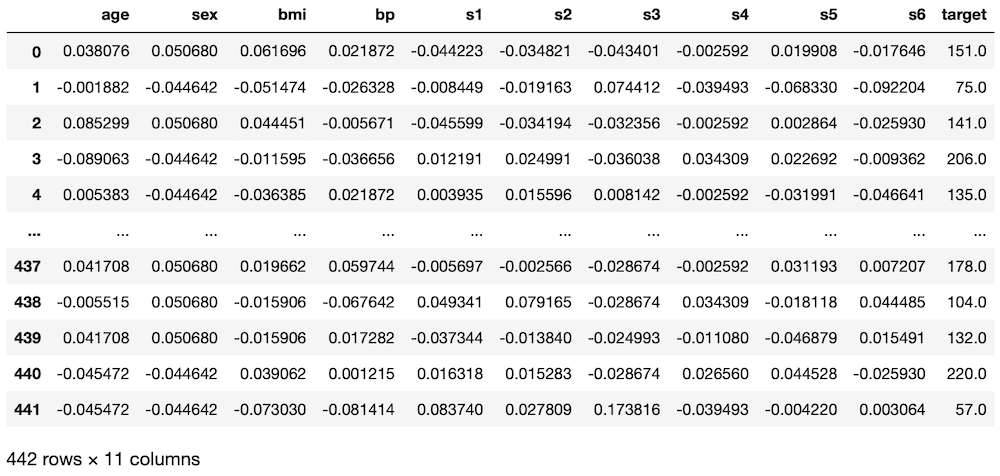
<セル2>
import itertools
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import Ridge
from sklearn.svm import SVR
from sklearn.metrics import r2_score
import numpy as np
models = ["LinearRegression","Lasso", "ElasticNet", "RidgeRegression", "SVR"]
trial=10
score_list = []; combination_list = []; model_list = []
std_list = []; max_list = []; min_list = []; score_std_list = []
for i in range(1, len(diabetes.feature_names)+1):
print(i)
for comb in itertools.combinations(diabetes.feature_names, i):
# print(comb)
x = df.loc[:, comb]
y = df.loc[:, "target"]
# print(x)
for mod in models:
pred_score = []
for t in range(trial):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8)
if mod == "LinearRegression":
model = LinearRegression()
elif mod == "Lasso":
model = Lasso()
elif mod == "ElasticNet":
model = ElasticNet()
elif mod == "RidgeRegression":
model = Ridge()
elif mod == "SVR":
model = SVR()
model.fit(x_train, y_train)
pred = model.predict(x_test)
pred_score.append(r2_score(y_test, pred))
# print(mod, r2_score(y_test, pred))
combination_list.append(comb)
score_list.append(np.average(np.array(pred_score)))
std_list.append(np.std(np.array(pred_score)))
max_list.append(np.max(np.array(pred_score)))
min_list.append(np.min(np.array(pred_score)))
model_list.append(mod)
results = pd.DataFrame()
results["Model_name"] = model_list
results["Combination"] = combination_list
results["Score"] = score_list
results["Max"] = max_list
results["Min"] = min_list
results["STD"] = std_list
results["Score/STD"] = results["Score"]/results["STD"]
results = results.sort_values("Score/STD", ascending=False)
results.head(10)
実行結果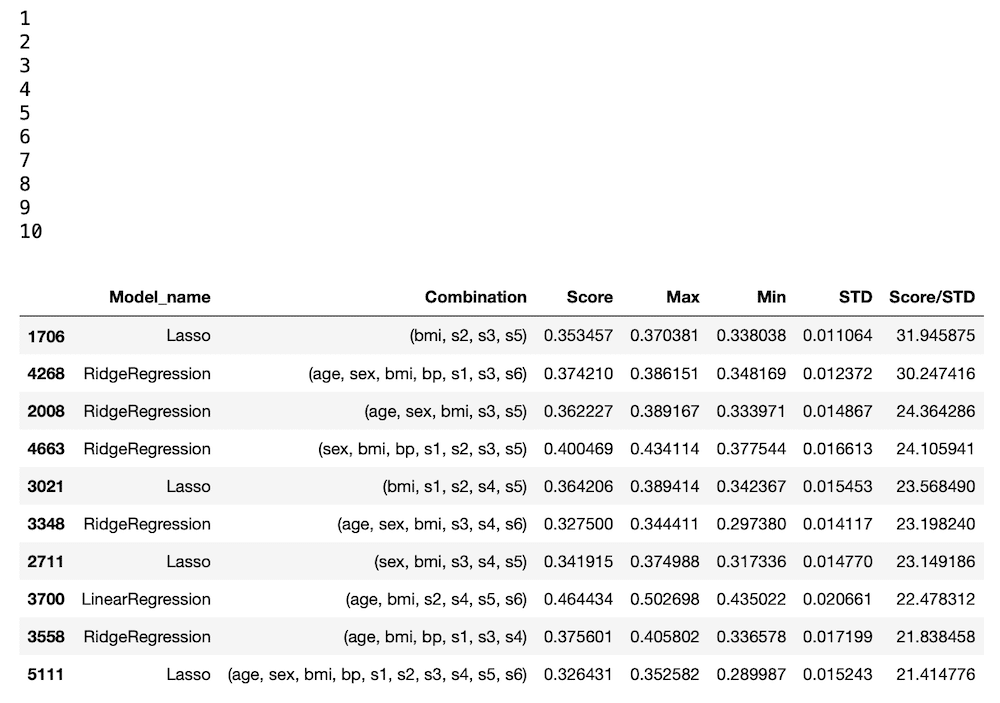
前回はこの次のセルに円グラフを表示するためのプログラムを書きました。
今回は円グラフはいらないので、この先に解析したいモデルを選択し、どの特徴量が使われやすいのかグラフ化するプログラムを作成していきましょう。
特徴量の個数をデータに追加
まずは特徴量の個数をデータに追加します。
つまり先ほどのデータの1行目「1706 Lasso」なら、bmi、s2、s3、s5が特徴量の組み合わせになっているので、「4」となります。
これをそれぞれの行においてカウントして、最後に新しい列として追加します。
プログラム的にはこんな感じ。
<セル3>
comb_count = []
for i in range(len(results)):
comb_count.append(len(results.iloc[i]["Combination"]))
results["No_comb"] = comb_count
results
実行結果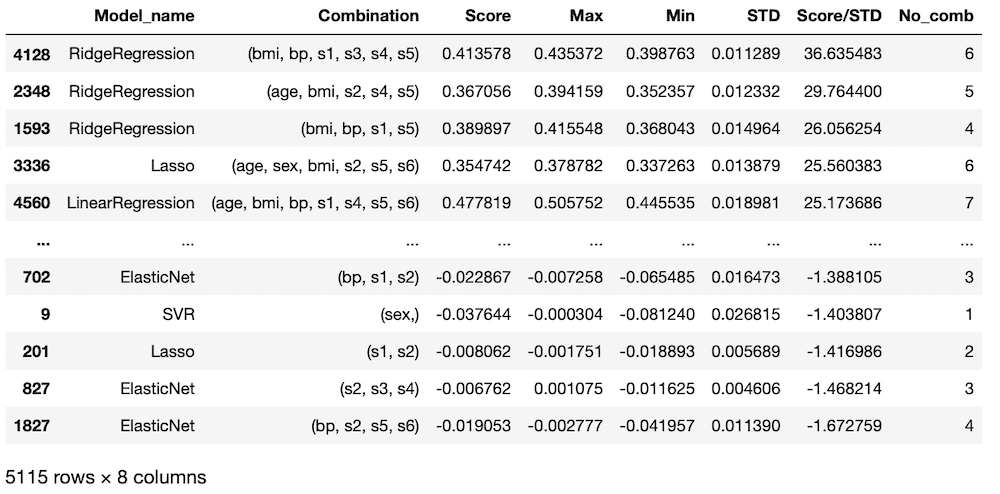
まずcomb_countという空のリストを作り、for文でresultsデータの行を一つ一つ読み込み、”Combination”の要素の個数をcomb_countリストに格納します。
そしてresults[“No_comb”] = comb_countで先ほどのリストをresultsデータフレームに追加します。
これで先ほどの実行結果の一番右側の列「No_comb」が出来上がるというわけです。
分析したいモデルのみ抽出
次に分析したいモデルのみ抽出します。
今回は前回の結果からよく使われているモデルである”RidgeRegression”を抽出してみましょう。
<セル4>
rd_data = results[results["Model_name"] == "RidgeRegression"]
rd_data
実行結果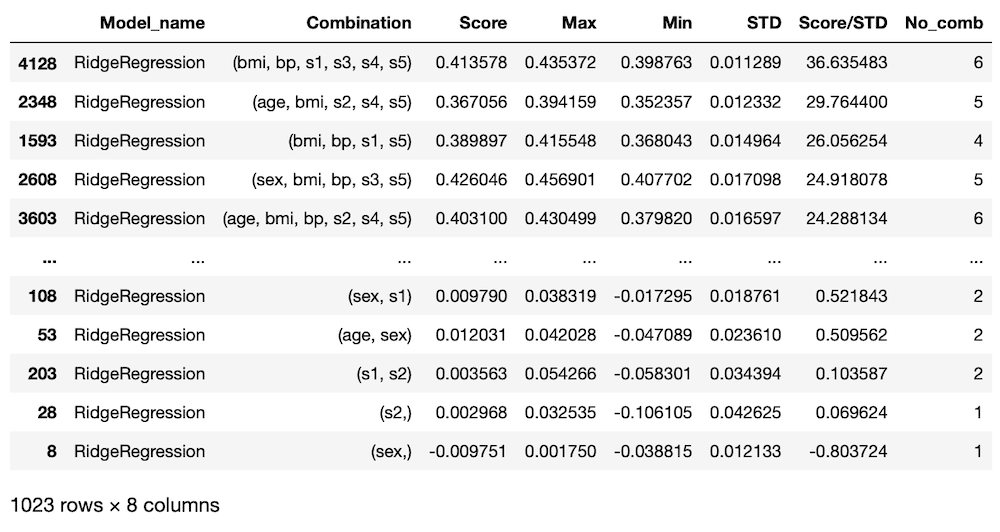
「results[results[“Model_name”] == “RidgeRegression”]」とすることで、”Model_name”が”RidgeRegression”と一致するものだけ抽出することができます。
それぞれの特徴量の個数をカウント
次にどこまでの順位のデータを取得するか決め、抽出し、そこまでの順位でのそれぞれの特徴量の個数をカウントしていきます。
<セル5>
ranking = 100
rd_ranking = rd_data[:ranking]
age_count = rd_ranking["Combination"].sum().count("age")
sex_count = rd_ranking["Combination"].sum().count("sex")
bmi_count = rd_ranking["Combination"].sum().count("bmi")
bp_count = rd_ranking["Combination"].sum().count("bp")
s1_count = rd_ranking["Combination"].sum().count("s1")
s2_count = rd_ranking["Combination"].sum().count("s2")
s3_count = rd_ranking["Combination"].sum().count("s3")
s4_count = rd_ranking["Combination"].sum().count("s4")
s5_count = rd_ranking["Combination"].sum().count("s5")
s6_count = rd_ranking["Combination"].sum().count("s6")
names = ["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"]
counts = [age_count,sex_count, bmi_count, bp_count, s1_count, s2_count, s3_count, s4_count, s5_count, s6_count]
print(names)
print(counts)
実行結果
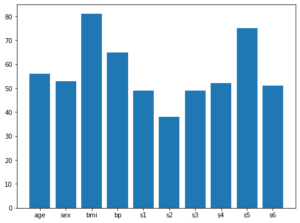
['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
[46, 48, 82, 60, 51, 52, 55, 45, 78, 49]最初の「ranking = 100」が取得する順位で、今回は100位までのデータを取得します。
「rd_ranking = rd_data[:ranking]」で100位までのデータを抽出し、rd_rankingに格納しました。
「age_count = rd_ranking[“Combination”].sum().count(“age”)」でrd_rankingの”Combination”の列に何個”age”が含まれているかカウントしています。
ちなみに「rd_ranking[“Combination”].sum()」の部分ですが、ここだけ実行してみるとこうなります。
print(rd_ranking["Combination"].sum())
実行結果
('bmi', 'bp', 's1', 's3', 's4', 's5', 'age', 'bmi', 's2', 's4', 's5', 'bmi', 'bp', 's1', 's5', 'sex', 'bmi', 'bp', 's3', 's5', 'age', 'bmi', 'bp', 's2', 's4', 's5', 'sex', 'bmi', 'bp', 's1', 's5', 'sex', 'bmi', 'bp', 's1', 's3', 'bmi', 'bp', 's4', 's5', 'age', 'sex', 'bp', 's1', 's3', 's4', 's5', 's6', 'bp', 's1', 's2', 's3', 's4', 's6', 'age', 'bmi', 's1', 's2', 's3', 's5', 's6', 'bmi', 's1', 's2', 's6', 'age', 'bmi', 'bp', 's1', 's3', 's6', 'sex', 'bmi', 's3', 's5', 's6', 'bmi', 's1', 's4', 'age', 'bmi', 's1', 's2', 's3', 's5', 'age', 'sex', 'bmi', 'bp', 's2', 's3', 's5',
(以下略)つまり「rd_ranking[“Combination”]」の列にある要素を全て合体させているわけです。
そして例えば「.count(“age”)」で”age” が含まれる個数をカウントしたということです。
そして「names」と「counts」に特徴量名と個数を格納していますが、これは次のグラフに表示するための準備です。
使われている特徴量の個数を棒グラフで表示
次に今回では100位までにそれぞれの特徴量が何個含まれているのか棒グラフで表示してみましょう。
<セル6>
from matplotlib import pyplot as plt
%matplotlib inline
fig = plt.figure(figsize=(8,6))
plt.clf()
plt.bar(names, counts)
実行結果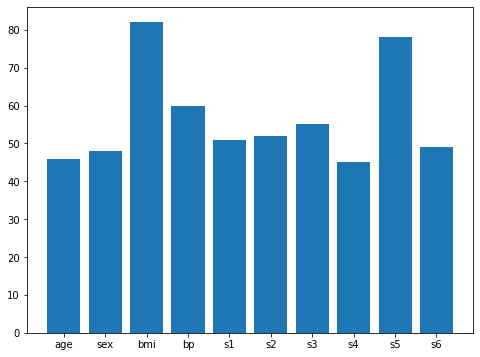
ぱっと見、bmiとs5が多そうですが、分析は次回に回しましょう。
まずこちらの2行でmatplotlibをjupyter notebookで使う準備。
from matplotlib import pyplot as plt
%matplotlib inlineこちらの2行でグラフ表示エリアの準備。
fig = plt.figure(figsize=(8,6))
plt.clf()「plt.bar(names, counts)」で横軸をnamesで、縦軸をcountsで棒グラフを表示しています。
使用した特徴量の数をヒストグラムで表示
次に使用した特徴量の個数をヒストグラムで表示してみます。
この際、比較対象として前データに対するヒストグラムも同時に表示してみます。
先ほどのセルでmaplotlibのインポートとマジックコマンドは読み込んであるので、今回はヒストグラムを表示するコマンドだけ。
<セル7>
plt.hist(rd_data["No_comb"],range=(0, 10))
plt.hist(rd_ranking["No_comb"], range=(0,10))
実行結果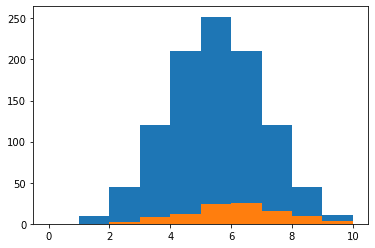
ヒストグラムでは単に個数(要素)が書かれたリストをplt.hist()に書き込むだけ。
最初の行はrd_dataということで全てのデータに対して、2行目はrd_rankingなので今回は100位までのデータに対しての特徴量の個数のヒストグラムを表示しています。
ちなみにrange=(0, 10)と書いてあるのは、x軸の範囲を指定しています。
これがないとこうなります。
plt.hist(rd_data["No_comb"])
plt.hist(rd_ranking["No_comb"])
実行結果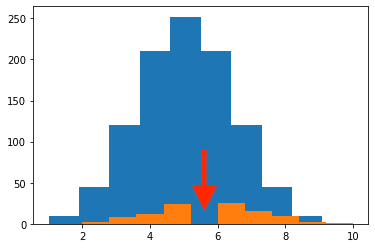
1箇所歯抜けになってしまっています。
これは出てこなかった要素(今回で言えば特徴量の個数)があったため、グラフが崩れてしまったのが原因です。
多分この例ですと、「10個全ての特徴量を使ったデータ」が100位までに出てこなかったので、グラフがずれてしまったのでしょう。
そのため、range=(0, 10)で範囲を固定しているということです。
これでデータをグラフ化し分析する準備が整いました。
次回はこのプログラムを使って、データを分析していきましょう。
ということで今回はこんな感じで。
コメント