機械学習ライブラリScikit-learn
前回、機械学習ライブラリScikit-learnで、全ての特徴量を二乗して新たな特徴量として、良い特徴量となりそうか、相関マップをみてみました。
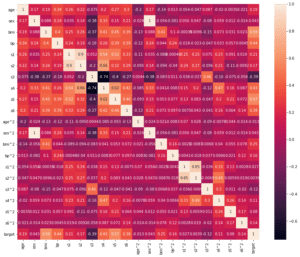
今回はそれぞれの特徴量を掛け合わせて、よい特徴量となるか試してみたいと思います。
ということでデータの読み込みから。
<セル1>
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df
実行結果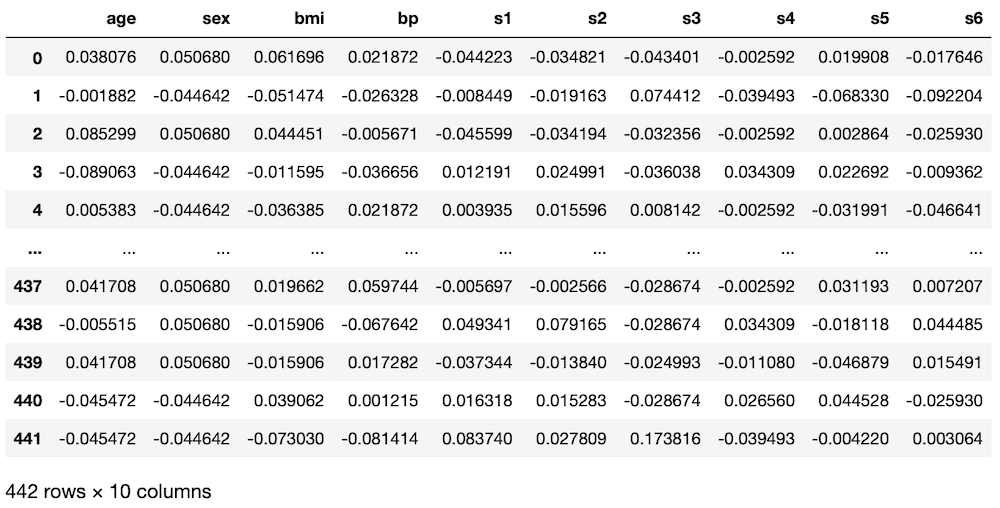
前回同様「target」の列は後から加えるので、ここでは記載していません。
特徴量を掛け合わせる
それでは特徴量をそれぞれ掛け合わせるプログラムを書いていきましょう。
前回のように最初に作成したデータフレームdfに計算した特徴量を追加していくと膨大になってしまいます。
そこで新しいデータフレームを作成して、そこに追加していくことにしましょう。
df_multi = pd.DataFrame()次にfor文を2回使って、特徴量を2つ取得し、それを掛け合わせ、先ほどの新しいデータフレーム「df_multi」に追加していきます。
for n in diabetes.feature_names:
for m in diabetes.feature_names:
dataname = n + " * " + m
df_multi[dataname] = df[n] * df[m]最後にターゲットの列を追加します。
df_multi["target"] = diabetes.targetということで全体としてはこんな感じ。
<セル2>
df_multi = pd.DataFrame()
for n in diabetes.feature_names:
for m in diabetes.feature_names:
dataname = n + " * " + m
df_multi[dataname] = df[n] * df[m]
df_multi["target"] = diabetes.target
df_multi
実行結果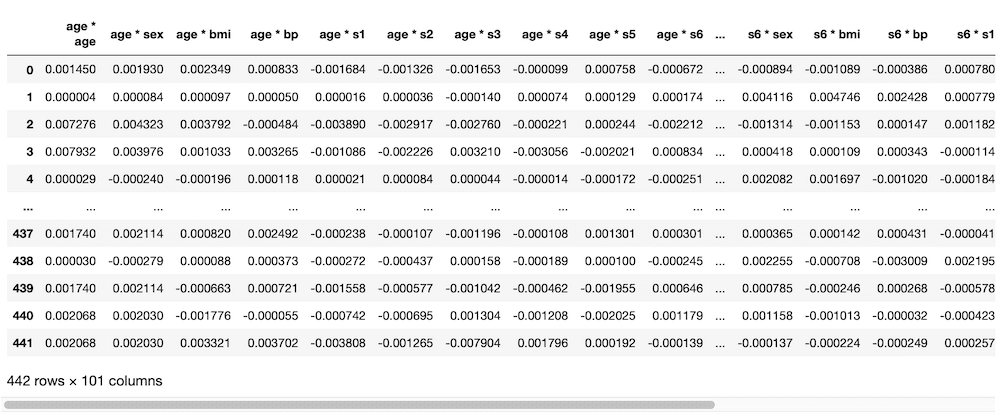
横に長くなってしまい、全部は表示されていませんが、スクロールするとちゃんと全部追加されていることが分かります。
相関値を計算
次に相関値を計算していきます。
ここは前回同様、「df_multi.corr()」で計算することができます。
<セル3>
corr = df_multi.corr()
corr
実行結果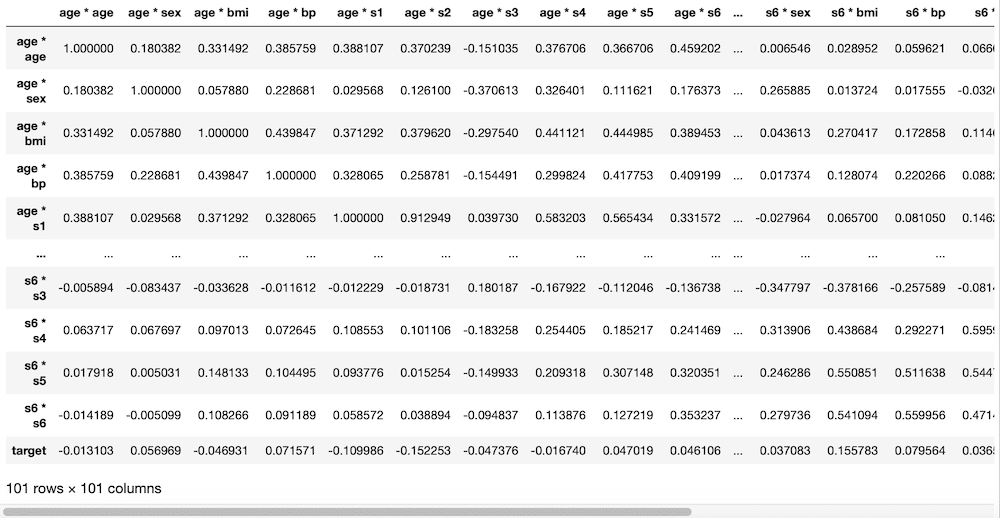
これも行数、列数が多くなりすぎ、行は途中が省略、列はスクロールで表示するようになっています。
これで相関マップとしたいところですが、今回は数が多すぎて、相関マップをみるのは難しいかなと思います。
ということで違う方法で結果を確認していきましょう。
ソートして、相関値の高い順に表示
今回、確認したい列としては「target」の列の値です。
ということでtargetの列で相関の高い順に並べ替え(ソート)、その結果を表示させてみましょう。
<セル4>
corr.sort_values("target", ascending=False)["target"]
実行結果
target 1.000000
bmi * bmi 0.252642
bp * bp 0.159668
s6 * bmi 0.155783
bmi * s6 0.155783
...
bmi * s2 -0.111384
s2 * bmi -0.111384
s3 * s3 -0.116275
age * s2 -0.152253
s2 * age -0.152253
Name: target, Length: 101, dtype: float64ちなみに上位20個のデータをみたい場合は、最後に「.head(20)」を追加します。
<セル4 上位20個>
corr.sort_values("target", ascending=False)["target"].head(20)
実行結果
target 1.000000
bmi * bmi 0.252642
bp * bp 0.159668
s6 * bmi 0.155783
bmi * s6 0.155783
bmi * bp 0.147113
bp * bmi 0.147113
s4 * s6 0.137648
s6 * s4 0.137648
s6 * s6 0.135534
s6 * s5 0.123427
s5 * s6 0.123427
s4 * s4 0.111540
s5 * bp 0.099435
bp * s5 0.099435
s5 * bmi 0.098690
bmi * s5 0.098690
s3 * s2 0.089468
s2 * s3 0.089468
s3 * sex 0.087390
Name: target, dtype: float64targetはそのままtargetと相関があって当たり前なので、1になります。
なので重要なのはその次の行から。
2番目は「bmi * bmi」の0.252642ですが、こちらは前回の二乗と同じデータなわけで、bmiやs5を単体で使った際の0.59とか0.57を超えていません。
この時点でこのデータセットでは特徴量を掛け合わせても相関値の向上は見られず、意味がないことが分かります。
残念な結果となってしまいましたが、それでも特徴量を使って計算をすることで、特徴量の重要度は変化させられることが分かりました。
ただし計算で良い特徴量とするには、その特徴量の性質や意味を理解し、その上で計算していかなければいけないのだと思います。
そろそろこの糖尿病患者のデータセットも結構使ってきましたので、新しいデータセットに変えることにしましょう。
ただ次回は新しいデータセットにする前に、matplotlibの円グラフに関して解説していきたいと思います。
ということで今回はこんな感じで。
コメント